
With the development of deep learning technology, the detection of human skeletal key points has continuously improved and has been widely applied in fields related to computer vision, becoming the foundation for many computer vision tasks, including security, new retail, motion capture, human-computer interaction, and more. Now, the popular human pose recognition has also been implemented using PaddlePaddle. Let’s learn how to use PaddlePaddle to implement human pose recognition tasks.
Project Address:
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/human_pose_estimation
Human pose estimation refers to restoring the positions of key points of a human body in a given video or photo. In recent years, researchers have conducted in-depth studies on pose estimation, leading to significant advancements in this field. However, this has also increased the overall complexity of algorithms and systems, making it more challenging to analyze and compare algorithms. Here, we have implemented a simple and effective baseline method using PaddlePaddle, achieving state-of-the-art results on challenging benchmarks, which may inspire new ideas and simplify evaluation methods.
Human pose recognition can be applied in many areas, such as in security to determine whether individuals in a scene exhibit aggressive behavior and trigger alarms. In new retail, it can analyze people’s purchasing behavior. It can also be used for gait analysis to assess athletes’ performance and improve their results. Additionally, it can be applied in human-computer interaction, allowing users to control home appliances from a distance.
The following video is a simple demonstration of a baseline method for human pose recognition and tracking, re-implemented based on Paddle Fluid, using the dataset provided by MSRA [1].
 Figure 1 Video Demonstration: Bruno Maes- That’s What I Like [Official Video]
Figure 1 Video Demonstration: Bruno Maes- That’s What I Like [Official Video]
The original author believes that current pose recognition methods are overly complex and exhibit significant differences, such as Hourglass, CPN, etc. The differences in these works are more evident at the system level rather than the information level. For example, the main methods for the MPII benchmark have substantial differences in many details, yet the accuracy differences are minimal. Thus, it is challenging to determine which details are critical for accuracy. Furthermore, the representative works for the COCO benchmark are also complex, but the differences are significant, with comparisons primarily at the system level rather than the information level. Therefore, the author proposes a pose estimation method that is both accurate and simple (with a very simple network structure) as a baseline, hoping to inspire new ideas and simplify evaluation methods.
A core question of the article is how good the results can be with a simple method. To better answer this core question, the author provides a baseline method for pose recognition and tracking. Although the baseline is quite simple, it is also very effective. Therefore, we compare the baseline with two current state-of-the-art human pose recognition methods, Hourglass and CPN. The network structure of the three is compared in the figure below:
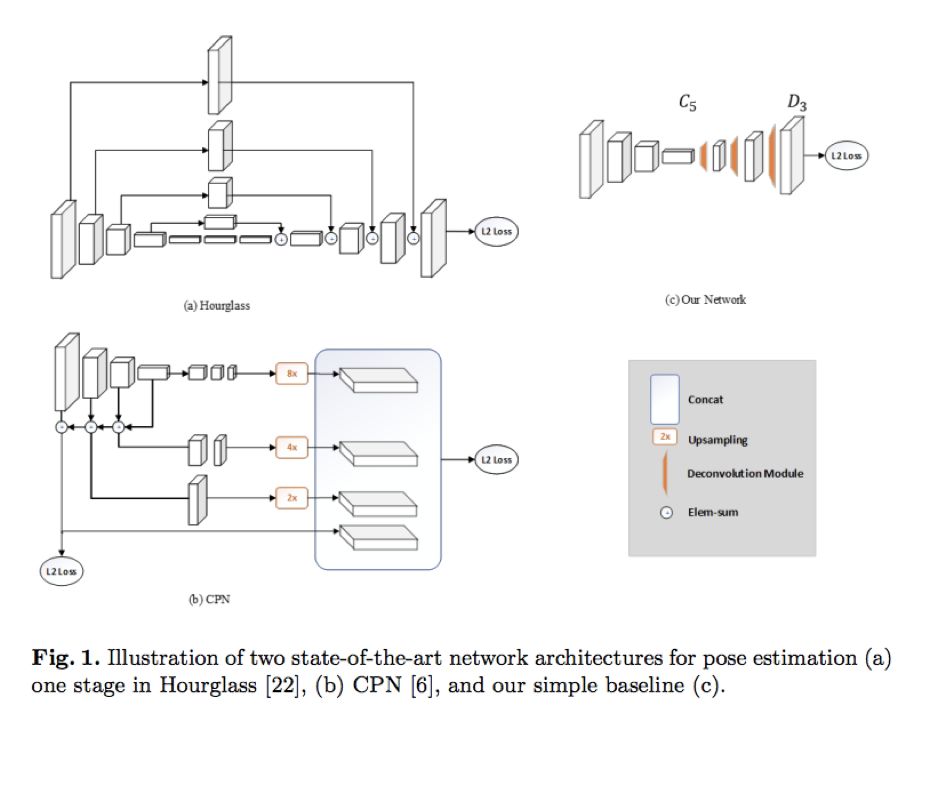
The pose recognition method proposed by the author in the paper is a simple baseline (the small image c in Figure 1). Compared to Hourglass and CPN, this network structure is simpler and does not involve any feature fusion. It merely inserts several deconvolution layers into ResNet to replace the structure composed of upsampling and convolution, which allows the low-resolution feature map to be expanded to the original image size, thereby generating the heatmap needed for predicting key points. However, this method achieves better results on the COCO key point detection task than CPN and Hourglass, yielding a higher average precision (AP) value, as shown in Figure 2:
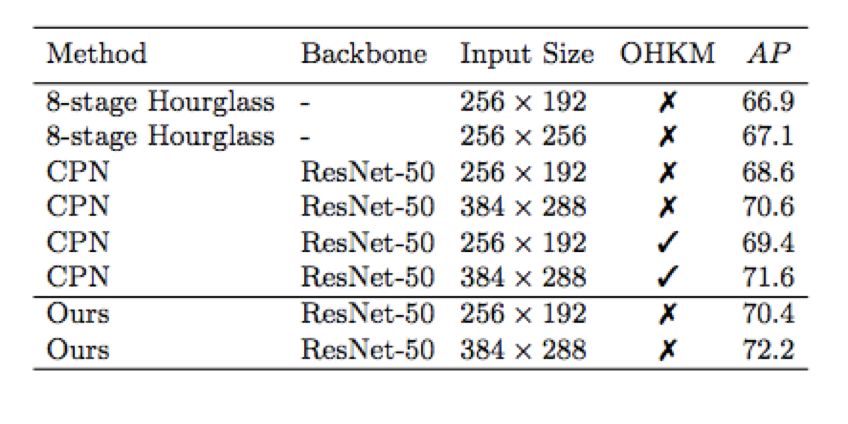 Figure 2: Comparison Results of Simple Baseline, Hourglass, and CPN on COCO val2017 Dataset
Figure 2: Comparison Results of Simple Baseline, Hourglass, and CPN on COCO val2017 Dataset
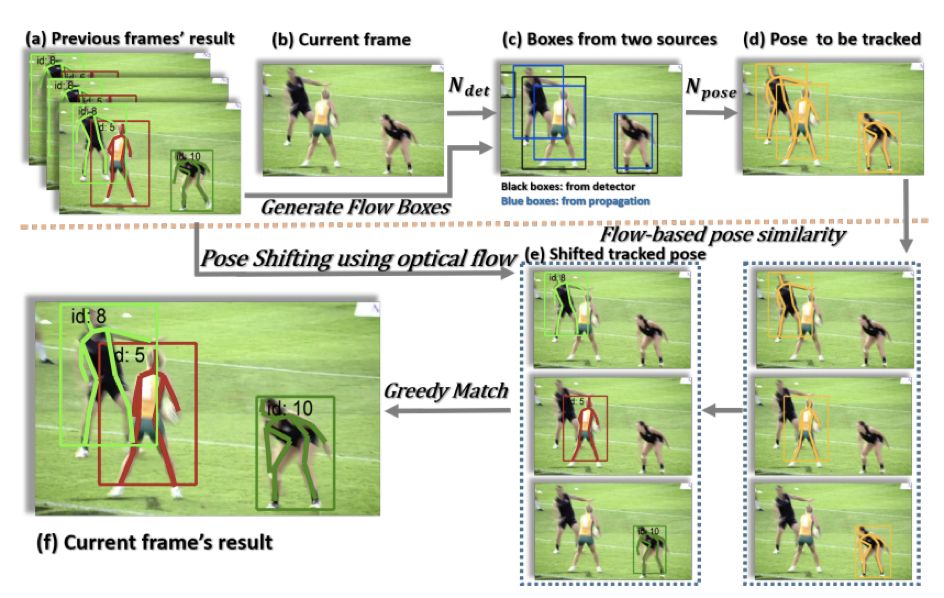 Figure 3: Proposed Flow-based Pose Tracking Framework
Figure 3: Proposed Flow-based Pose Tracking Framework
For multi-person pose tracking in videos, the human poses in the frame are first estimated, and then these poses are tracked by assigning unique identification numbers (IDs) to them in the frame. The article first introduces an algorithm from the winner of the ICCV’17 PoseTrack Challenge to solve multi-person trajectory tracking, which uses Mask R-CNN for person detection. In the first frame of the video, each detected person is given an identification ID, and in subsequent frames, the detected persons are matched with those from the previous frame using a certain metric (calculating the IoU of the detection boxes) to determine similarity. Those with high similarity are assigned the same identification ID, while unmatched persons are assigned a new ID. The method proposed by the author retains the main flow of this method and presents two improvements:
1. In addition to the detection network, optical flow is used to supplement some detection boxes to address the issue of missed detections by the detection network (for example, the person on the far left in Figure 3© was not detected by the detection network).
2. Object Keypoint Similarity (OKS) is used instead of the IoU of the detection boxes to calculate similarity. This is because using IoU may not be reasonable when the person’s movements are fast.
Next, we will show how to reproduce this simple baseline using PaddlePaddle.
-
Python == 2.7 or 3.6
-
PaddlePaddle >= 1.4.0
-
opencv-python >= 3.3
-
Prepare the dataset according to the instruction guidelines
-
Download the pre-trained ResNet-50 model
wget http://paddle-imagenet-models.bj.bcebos.com/resnet_50_model.tarThen, place them in the pretrained folder at the root directory of this repo, organized as follows:
${THIS REPO ROOT} `-- pretrained `-- resnet_50 |-- 115 `-- data `-- coco |-- annotations |-- images `-- mpii |-- annot |-- images# COCOAPI=/path/to/clone/cocoapigit clone https://github.com/cocodataset/cocoapi.git $COCOAPIcd $COCOAPI/PythonAPI# if cython is not installedpip install Cython# Install into global site-packagesmake install# Alternatively, if you do not have permissions or prefer# not to install the COCO API into global site-packagespython2 setup.py install --userDownload the checkpoint of Pose-ResNet-50 trained on the MPII dataset from here. Unzip it into the checkpoints folder at the root directory of this repo, and then run:
python val.py --dataset 'mpii' --checkpoint 'checkpoints/pose-resnet50-mpii-384x384' --data_root 'data/mpii'python train.py --dataset 'mpii'Note: Training configurations are summarized in lib/mpii_reader.py and lib/coco_reader.py.
We also support applying the pre-trained model on custom images. Place the images in the test folder at the root directory of this repo, and then run:
python test.py --checkpoint 'checkpoints/pose-resnet-50-384x384-mpii'Note: If there are multiple people in the image, it is necessary to first detect and crop the human areas using detectors like Faster R-CNN or SSD before performing pose estimation, as the simple baseline mentioned in this article is a top-down pose estimation method.
The following results were tested in the environment: CentOS 6.3, 4 Tesla K40 / P40 GPUs, CUDA-9.0 / 8.0, and cuDNN-7.0.
Results on the MPII test set:
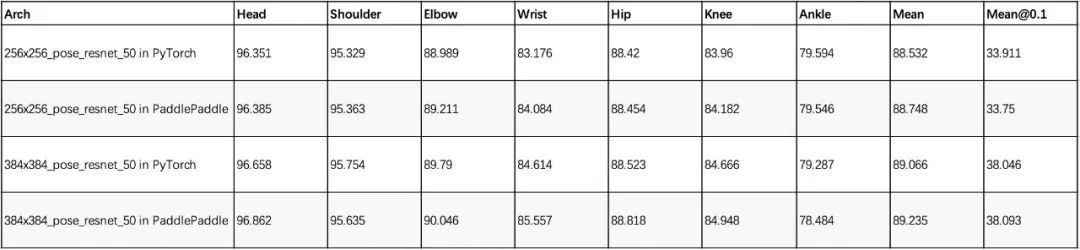
Results on the COCO val2017 dataset using a human AP of 0.564 detector on the COCO val2017 dataset:
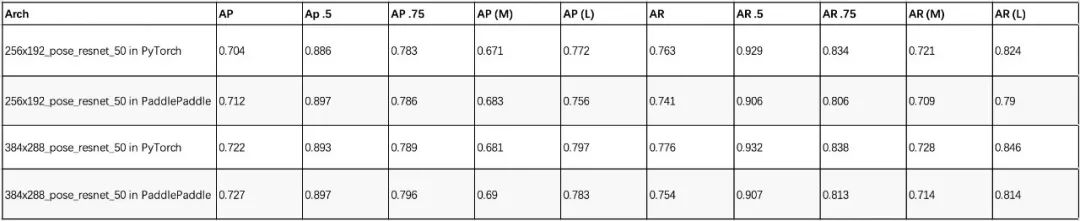
Notes:
-
All results used flip testing.
-
We did not use any model selection strategy to choose the best model, directly testing the results of the last checkpoint.
Note: For model downloads, please visit the GitHub project page:
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/human_pose_estimation
Simple Baselines for Human Pose Estimation and Tracking, Bin Xiao, Haiping Wu, Yichen Wei https://arxiv.org/abs/1804.06208