
Is the potential of agents underestimated?
AI agents were a hot topic last year, but many may not have a clear concept of how much potential AI agents really have.
Recently, Stanford University professor Andrew Ng mentioned in a speech that they found workflows built on GPT-3.5 performed better in applications than those built on GPT-4. Of course, workflows based on GPT-4 perform better. It seems that AI agent workflows will drive significant advancements in artificial intelligence this year, potentially even surpassing the next generation of foundational models. This is a trend worth everyone’s attention.

This speech about agents sparked widespread attention on social media. Some expressed that this represents a paradigm shift in AI development, reflecting a transition from static outputs to dynamic iterations. Standing at such a crossroads, we must not only consider how AI will change our work but also how we will adapt to the new environment it creates.

Others said this resonates with their life experiences: some people can outperform those who are smarter than them by having a good process.
So, how is this effect of agents achieved?
Unlike traditional LLM usage, agent workflows do not let LLM generate the final output directly, but rather prompt the LLM multiple times to gradually construct higher-quality outputs.
In his speech, Andrew Ng introduced four design patterns for AI agent workflows:

-
Reflection: The LLM checks its own work to suggest improvements.
-
Tool Use: The LLM has functions like web searching, code execution, or any other capabilities to help collect information, take action, or process data.
-
Planning: The LLM proposes and executes a multi-step plan to achieve a goal (e.g., drafting an outline, conducting online research, and then writing a draft…).
-
Multi-Agent Collaboration: Multiple AI agents work together, assigning tasks and discussing and debating ideas to come up with better solutions than a single agent could.
In subsequent blogs, Andrew Ng focused on the Reflection mode. Ng stated: “The reflection mode is a relatively fast design pattern that has already brought about astonishing performance improvements.”

He wrote in his blog:
We may all have had this experience: prompting ChatGPT/Claude/Gemini and receiving unsatisfactory outputs, providing critical feedback to help the LLM improve its response, ultimately getting a better response.
If we automate the step of providing critical feedback, allowing the model to critique its own output and improve its response, what would happen? This is the essence of the reflection mode.
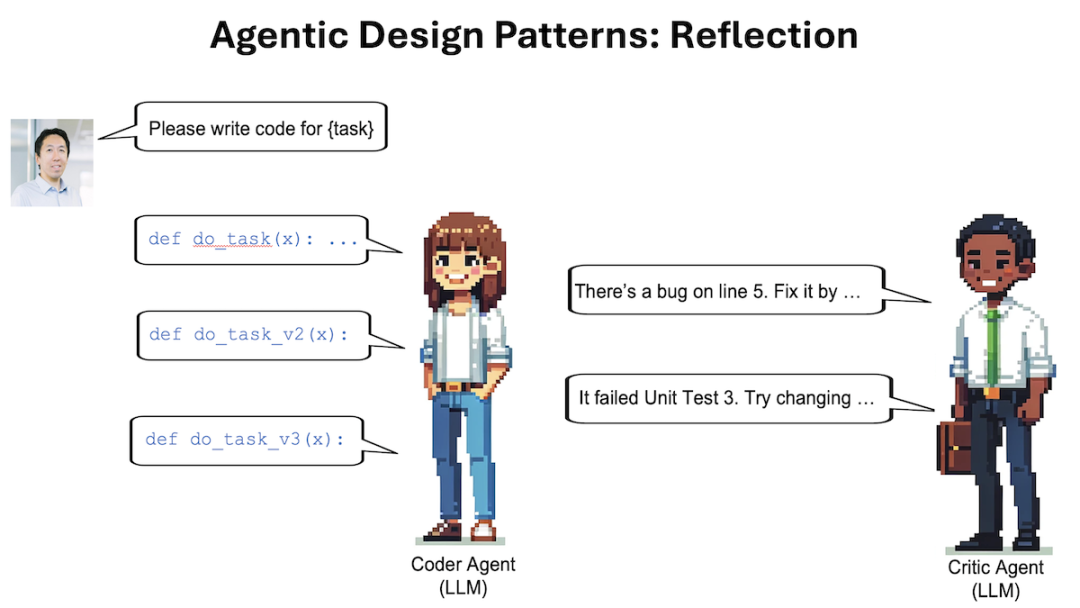
For example, when asking the LLM to write code, we can prompt it to directly generate the required code for a task X. Afterwards, we can prompt it to reflect on its output as follows:
This is the code for task X: [previously generated code]
Carefully check the correctness, style, and efficiency of the code, and provide constructive suggestions on how to improve it.
Sometimes this will lead the LLM to discover issues and propose constructive suggestions. Next, we can provide context prompts to the LLM, including:
-
Previously generated code;
-
Constructive feedback;
-
Requesting it to use the feedback to rewrite the code.
This can allow the LLM to ultimately output better responses. The iterative critique/rewrite process may yield further improvements. This self-reflection process enables the LLM to identify gaps and improve its outputs across various tasks, including generating code, writing text, and answering questions.
We can help the LLM evaluate its outputs by providing tools. For example, running the code against several test cases to check if it generates the correct results or searching the web to verify text outputs. Then, the LLM can reflect on any errors it finds and propose improvement ideas.
Additionally, we can use a multi-agent framework to implement reflection. Creating two distinct agents is convenient, one prompts for good output, while the other critiques the output from the first agent. The discussion between the two agents drives improvements in the response.
Reflection is a relatively basic agent workflow pattern, but it has significantly improved results in some cases.
Finally, regarding reflection, Ng recommended several papers:
-
“Self-Refine: Iterative Refinement with Self-Feedback,” Madaan et al., 2023
-
“Reflexion: Language Agents with Verbal Reinforcement Learning,” Shinn et al., 2023
-
“CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing,” Gou et al., 2024
Below, Machine Heart summarizes the content of this speech.
Andrew Ng: The Future of AI Agents
I look forward to sharing what I see in AI agents. I believe this is an exciting trend, and every AI practitioner should pay attention to it.

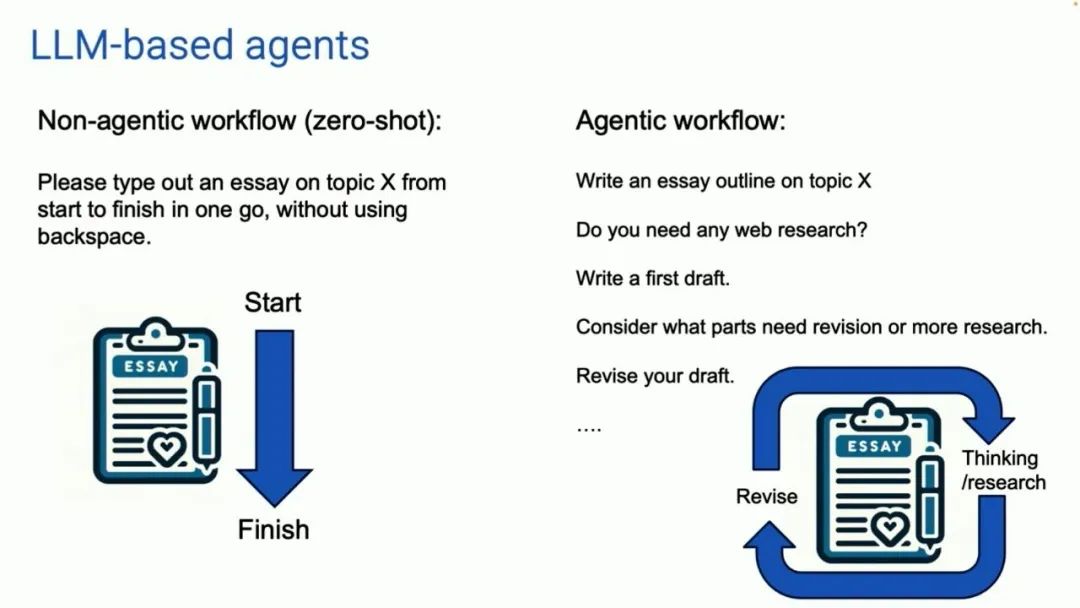
What I want to share is AI agents. Currently, most of us use large language models in a non-agent workflow: you input prompts into a dialog box and generate answers. This is somewhat like asking a person to write an article on a certain topic. I say, please sit at the keyboard and type out an article from start to finish without using the backspace key. Even though this is difficult, the AI large model does it very well.
Agent workflows look like this (right image). There is an AI large model, and you can ask it to write a paper outline. Do you need to search the internet for information? If so, we connect to the internet. Then write a draft, read the draft, and think about which parts need modification. Then modify your draft and continue to advance. This workflow allows for easier iterations. You can have the AI large model think a bit, then modify the article, and then continue to think and iterate. Repeat this process multiple times.
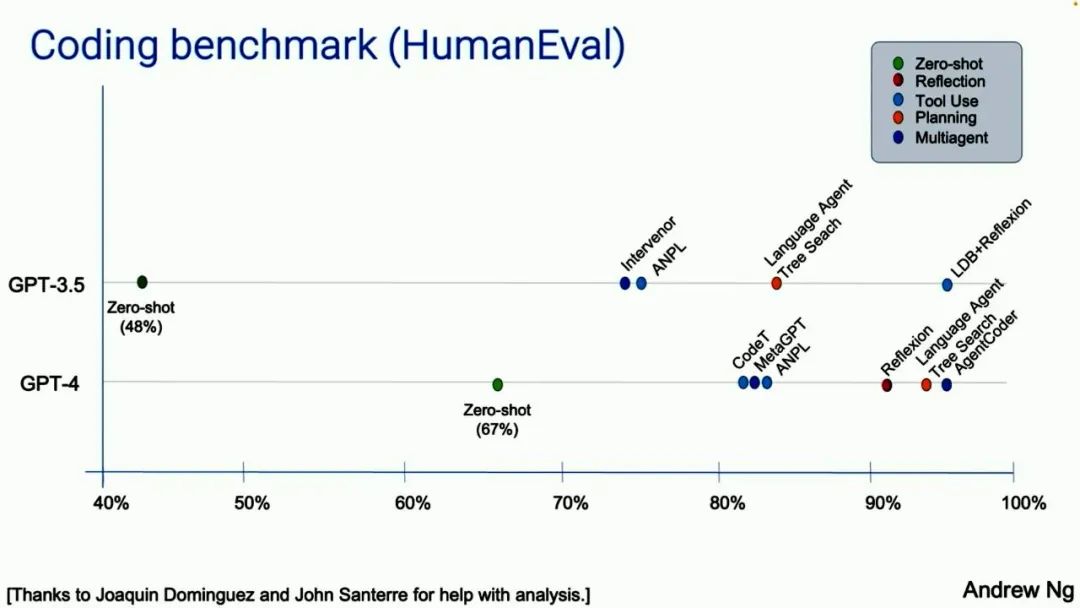
Many people do not realize that doing this produces much better results. In fact, I was surprised myself at their decision-making processes and their excellent performance. Besides these case studies, my team also analyzed some data using a programming assessment benchmark called HumanEval, which was released by OpenAI a few years ago. It contains programming problems, such as returning the sum of all odd elements at even positions in a non-empty integer list. The AI-generated answer is a code snippet like this.

Nowadays, many of us use zero-shot prompts. For example, we tell the AI to write code and let it run at the first position. Who codes like this? No one writes code this way. We just input the code and run it. Maybe you code this way, but I can’t. It turns out that if you use GPT-3.5 under zero-shot prompting conditions, the accuracy of GPT-3.5 is 48%. GPT-4 is much better, reaching 67%. But if you adopt an agent workflow and package it, GPT-3.5 actually performs better, even better than GPT-4. If you build such a workflow around GPT-4, it will also perform well. Note that GPT-3.5 in an agent workflow actually outperforms GPT-4. I think this is already a signal.
Everyone is having extensive discussions around the term and tasks of agents. There are many consulting reports about agents, the future of AI, and so on. I want to be more specific and share the broad design patterns I see in agents. This is a very chaotic and turbulent space. There is a lot of research, and many things are happening, and I try to categorize it more specifically and discuss what is happening in the field of agents.

Reflection is a tool I believe many of us are using. It is effective. I think tool use has gained more recognition, but reflection also works very well. I think they are both very powerful techniques. When I use them, I can almost always get them to work well. Planning and multi-agent collaboration are emerging technologies. Sometimes I am amazed by their effectiveness when I use them. But at least at this moment, I feel I cannot make them work reliably all the time.
Next, I will explain these four design patterns in detail. If some of you go back and use these patterns or let your engineers use them, I believe you can quickly achieve productivity gains.
First is reflection. For example, suppose I ask a system to write code for a given task. Then we have a code agent, just a large model that accepts your written prompts. It will write a function as shown in the figure. Here is an example of self-reflection. If you give your large model such a prompt, telling it this is the code for performing a certain task, give it the code you just generated, and let it check the correctness, efficiency, and similar issues of that code. As a result, you will find that the large model that wrote the code based on your prompt may be able to identify issues in the code, such as a bug in line five. It will also tell you how to modify it. If you now adopt its feedback and prompt it again, it may propose a better second version of the code than the first version. It is not guaranteed, but it is effective. This method is worth trying in many applications.
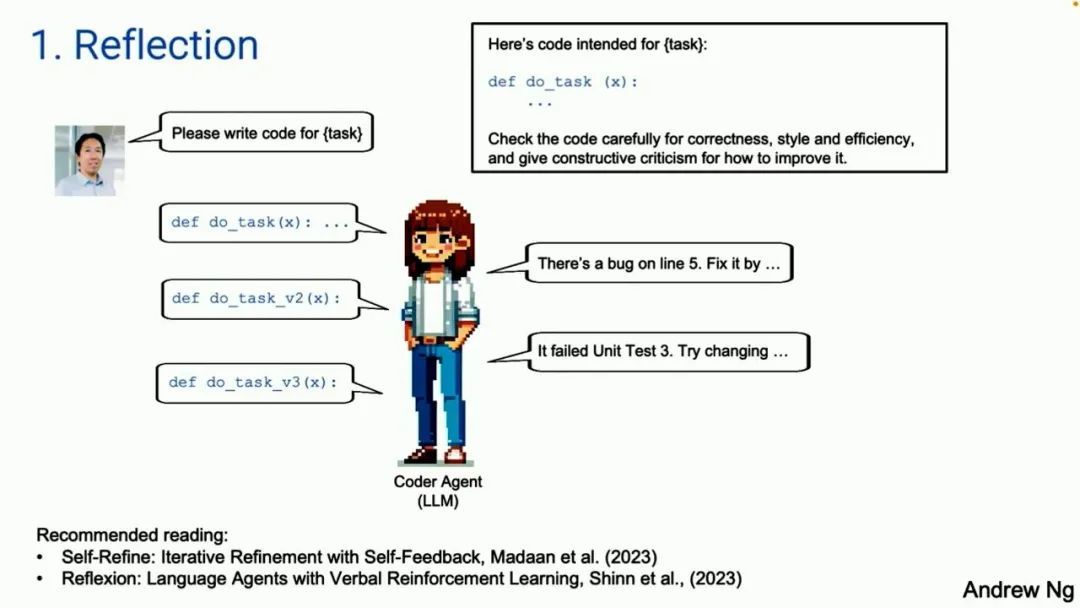
Here, let me mention tool use in advance. If you let it run unit tests, and it does not pass, you want to know why it failed. Engaging in such a dialogue may help identify the reasons. This way, you can try to correct it. By the way, if anyone is interested in these techniques, I have written a small recommended reading section at the bottom of each part of the slides, just at the bottom of the PPT. It contains more references.
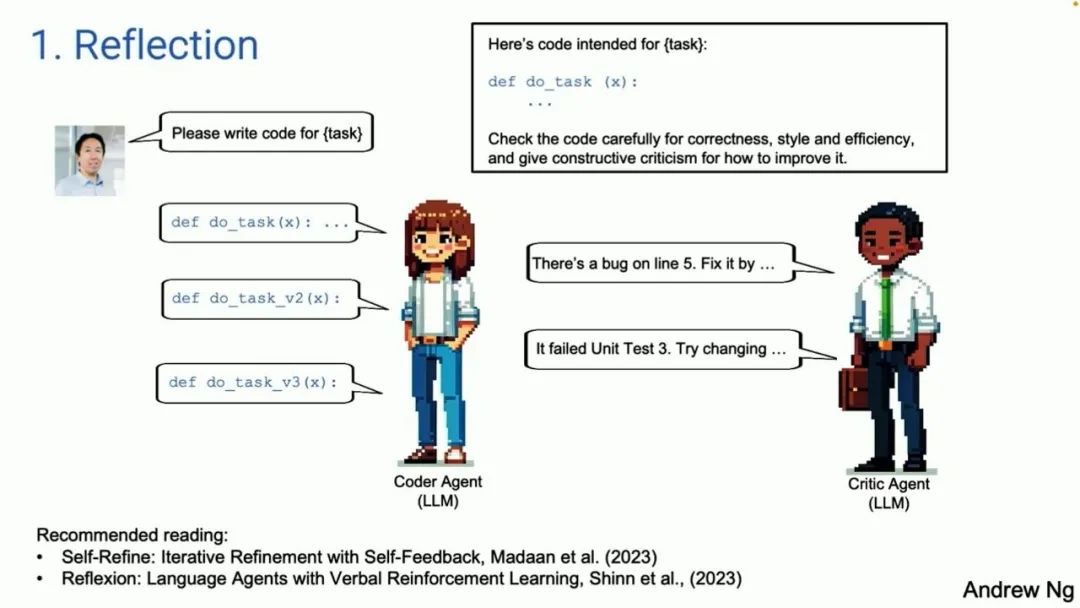
Let me also mention multi-agent systems in advance. It is described as a single code agent, where you give it prompts and have them engage in dialogue. A natural evolution of this idea is a single programming agent. You could have two agents, one being a coding agent and the other being a reviewing agent. They may have the same underlying large model, but the prompts you give them are different. We tell one of them, you are the expert in writing code, responsible for coding. To the other, we say, you are the expert in reviewing code, responsible for auditing this code. This workflow is actually easy to implement. I think this is a very general technique applicable to many workflows. It will bring significant improvements to the performance of large language models.
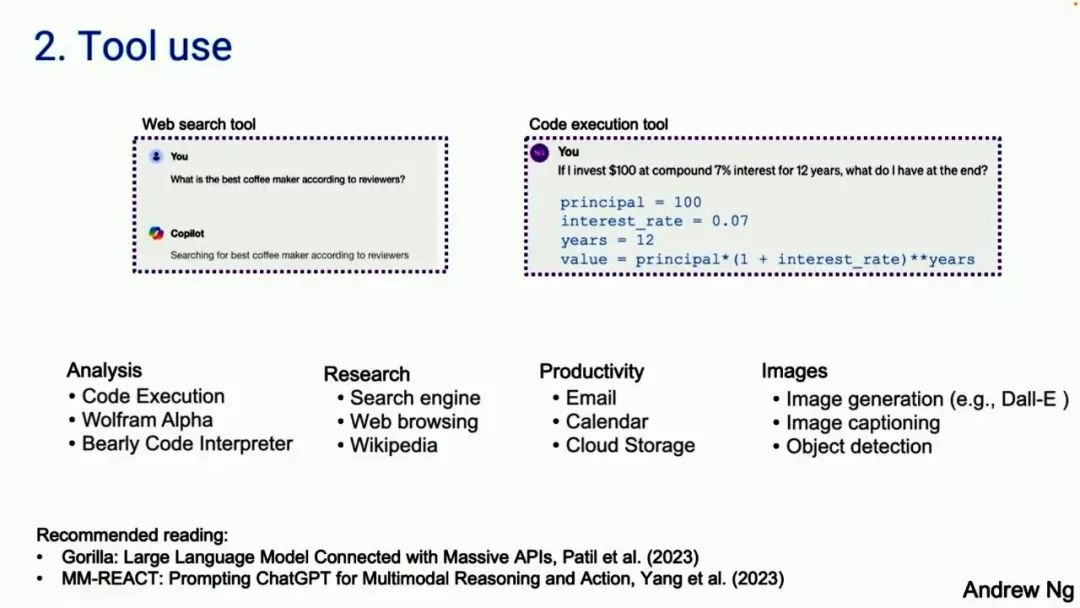
The second design pattern is tool use. Many people may have already seen systems based on large models using tools. The left screenshot is from Copilot. The right screenshot is from GPT-4. The question on the left is, which is the best coffee machine online? Copilot would solve some problems by searching online. GPT-4 will generate code and run it. It turns out that many different tools are used by people to analyze, collect information to take action, and improve individual productivity. Many early works on tool use seem to have originated from the computer vision community. Previously, large language models were ineffective with images, so the only option was for the large model to generate a function call that could manipulate images, such as generating images or performing object detection. Let’s take a look at the literature; interestingly, much of the work in the tool use field seems to have originated from the vision community because large language models could not see images before the emergence of models like GPT-4V and LLaVA. This is tool use, which extends the capabilities of large language models.
Next, let’s talk about planning. For those who have not had much exposure to planning algorithms, I think many people feel, when talking about the ChatGPT moment, “Wow, I’ve never seen anything like this.” I think you have not used planning algorithms. Many people are surprised by what AI agents can do, “Wow, I didn’t expect AI agents could do this.” In some live demonstrations I conducted, some demonstrations failed, and the AI agents would replanning paths. I have actually experienced many such moments, “Wow, I can’t believe my AI system just did that automatically.” One example is adapted from the HuggingGPT paper. What you input is: please generate an image of a girl reading, with her posture the same as the boy in the image. Then describe this new image in your voice. Given such an example, today with AI agents, the first thing you need to do is determine the boy’s posture. Then find the appropriate model, perhaps on HuggingFace, to extract the posture. Next, you need to find a posture image model to follow the instructions to generate an image of the girl. Then use an image-to-text model to get the description. Finally, use a text-to-speech model to read out the description.

We already have AI agents today; I don’t want to say they are reliably working, they are a bit picky, and not always easy to use. But when they work, the effects are actually very amazing.
With agent loops, sometimes you can fix early issues. I have been using research agents for some of my work; I don’t want to spend a lot of time Googling. I send the requirements to the AI agent and check back in a few minutes to see what it has done. Sometimes it is effective, sometimes not. But that has already become part of my personal workflow.
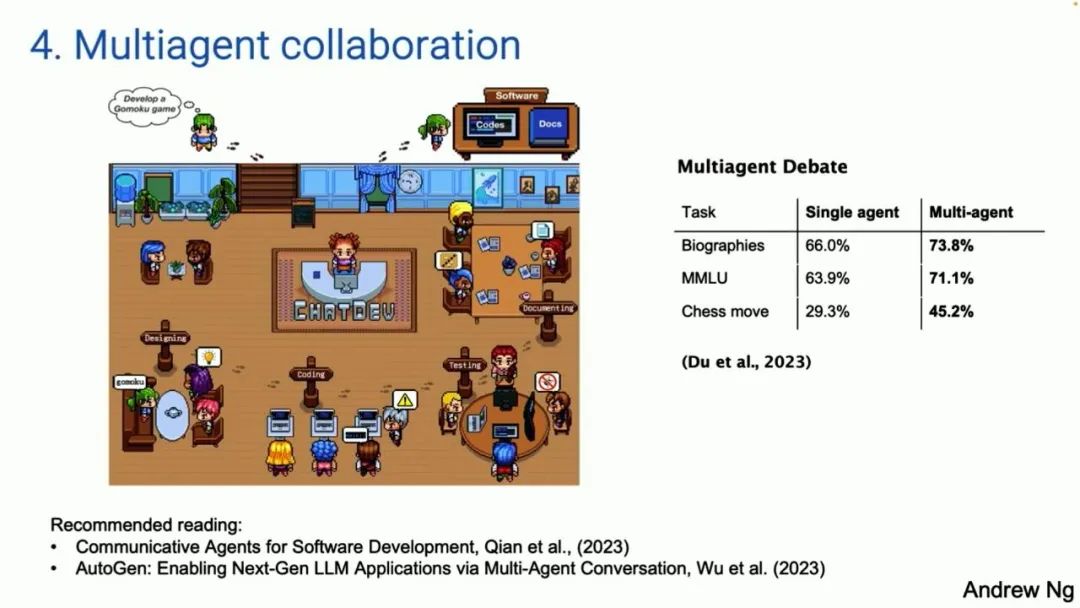
The last pattern to discuss is multi-agent collaboration. This part is interesting; its effects are much better than you might think. The left image comes from a paper called ChatDev. It is completely open-source, and many of you have seen Devin’s demonstration on social media. ChatDev is an instance of a multi-agent system. You can give it a prompt, and it sometimes plays the role of the CEO of a software engine company, sometimes a designer, sometimes a product manager, and sometimes a tester. This group of agents is constructed by giving prompts to the large model, telling them “you are now the CEO/you are now the software engineer.” They will collaborate and engage in further dialogue. If you tell them, “please develop a game,” they will spend a few minutes writing code, testing, iterating, and then generating a surprisingly complex program, although it doesn’t always run. I have tried it; sometimes the generated results are unusable, and sometimes they are stunning. But this technology is indeed getting better and better. This is one of the design models. Additionally, it turns out that multi-agent debates (where you have multiple agents), for example, you can have ChatGPT and Google’s Gemini debate, actually lead to better performance. Therefore, having multiple similar AI agents work together is also a powerful design pattern.
To summarize, these are the patterns I see. I believe that if we use these patterns in our work, many of us can quickly achieve practical improvements. I think agent reasoning design patterns will be very important. This is my brief PPT. I expect that what AI can do this year will expand significantly, thanks to agent workflows.

One thing that is actually very difficult is that people need to get used to the fact that after inputting prompts, we always want immediate results. In fact, over a decade ago, when I was discussing big box search at Google, we entered a long prompt. One reason I did not succeed in promoting this project was that when conducting web searches, you want a response in half a second. This is human nature—we like instant access and instant feedback. But for many AI agent workflows, I think we need to learn to delegate tasks to AI agents and patiently wait a few minutes, even hours, for them to respond. I have seen many new managers delegate something to someone and then check the results five minutes later. This is not an effective way to work. I think we need this; it is really hard. We also need to be more patient with our AI agents.
Another important thing is that fast token generation is very important. Because with these AI agents, we iterate over and over again. AI generates tokens for human reading. If AI generates tokens faster than anyone can read, that would be great. I believe that generating more tokens quickly, even with slightly lower-quality large models, can yield good results. Compared to slowly generating tokens with better large models, this may be controversial. Because it might allow you to iterate more times in this loop. This is somewhat like the results of the large model and agent architecture I showed in the previous slides.
To be frank, I am very much looking forward to Claude 4, GPT-5, Gemini 2.0, and other outstanding large models being built. I feel that if you expect to run your tasks on GPT-5 in a zero-shot manner, you may be approaching that level of performance on some AI agent applications, which may exceed your expectations, with agent reasoning combined with previously released large models. I believe this is an important trend. Honestly, the road to AGI feels more like a journey than a destination, and I think this set of agent workflows can help us take a small step forward on this long journey.
Reference Links:
https://www.deeplearning.ai/the-batch/issue-242/
https://zhuanlan.zhihu.com/p/689492556?utm_medium=social&utm_psn=1756970518132240384&utm_source=wechat_session
https://www.youtube.com/watch?v=sal78ACtGTc&t=108s

© THE END
For reprints, please contact this public account for authorization.
Submissions or inquiries: [email protected]