
Paper Title: VMamba: Visual State Space Model Authors: Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Yunfan Liu Compiled by: Frank Reviewed by: Los

Convolutional Neural Networks (CNNs) and Visual Transformers (ViTs) are currently the two most popular foundational models for visual representation. CNNs have impressive scalability with linear complexity. ViTs outperform CNNs in terms of performance; however, they have quadratic complexity. In-depth analysis reveals that ViTs possess stronger performance due to their utilization of global receptive fields and dynamic weight allocation methods. Therefore, a framework that combines the global perception advantages of ViTs with high computational efficiency needs to be proposed. Inspired by state space models, we propose the Visual State Space Model (VMamba), which achieves linear computational complexity without compromising the global receptive field. To address the direction sensitivity issue within the model, we introduce a Cross-Scan Module (CSM). This module can traverse the spatial domain of images, transforming any visual image into an ordered sequence. Experimental results show that the proposed VMamba not only excels in various visual perception tasks but also demonstrates more pronounced advantages as image resolution increases.

Visual representation learning is one of the fundamental research problems in the field of computer vision. Since the advent of deep learning, visual representation learning has undergone many significant breakthroughs. Among them, CNNs and ViTs are two foundational deep learning models that have been applied in many visual tasks. Although both models have achieved considerable success in visual representation, ViTs generally outperform CNNs. This is due to the global receptive fields and dynamic weight allocation brought by the attention mechanism in ViTs.
However, the attention mechanism has a quadratic algorithmic complexity with respect to image size. This results in significant computational overhead when addressing downstream dense prediction tasks, such as object detection and semantic segmentation. To tackle this problem, many methods have been proposed to enhance the efficiency of the attention mechanism. While these methods improve computational efficiency by limiting the size and stride of the moving image processing window, they often compromise the global perception range. This has motivated us to design a new foundational visual representation model with linear complexity while maintaining the advantages of global perception and dynamic weight allocation.
Inspired by recent state space models, we introduce the Visual State Space Model (VMamba) for efficient visual representation learning. The concept of VMamba reducing the complexity of the attention mechanism originates from the “Selective Scan Space State Sequential Model” (S6). Originally applied in natural language processing, S6 differs from traditional attention mechanisms in that it allows each element in the sequence to interact with any previously scanned sample. This reduces the quadratic complexity of the attention mechanism to linear.
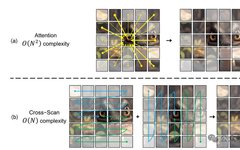
However, due to the non-causal nature of visual data, directly applying the S6 method to chunked and flattened visual images leads to a loss of global receptive field. This is because the attention associations between unscanned image patches are not estimated. The paper refers to this phenomenon as the “direction sensitivity” problem. To address this issue, the paper proposes the “Cross-Scan Module” (CSM). Unlike traditional traversal methods that scan row-wise or column-wise, CSM adopts a “four-way” scanning strategy, starting from the four corners of the image and winding its way to the diagonals (as shown below). This strategy ensures that every element in the feature map can integrate elements from other positions and directions. Therefore, this strategy allows the model to maintain a global receptive field while achieving linear computational complexity.
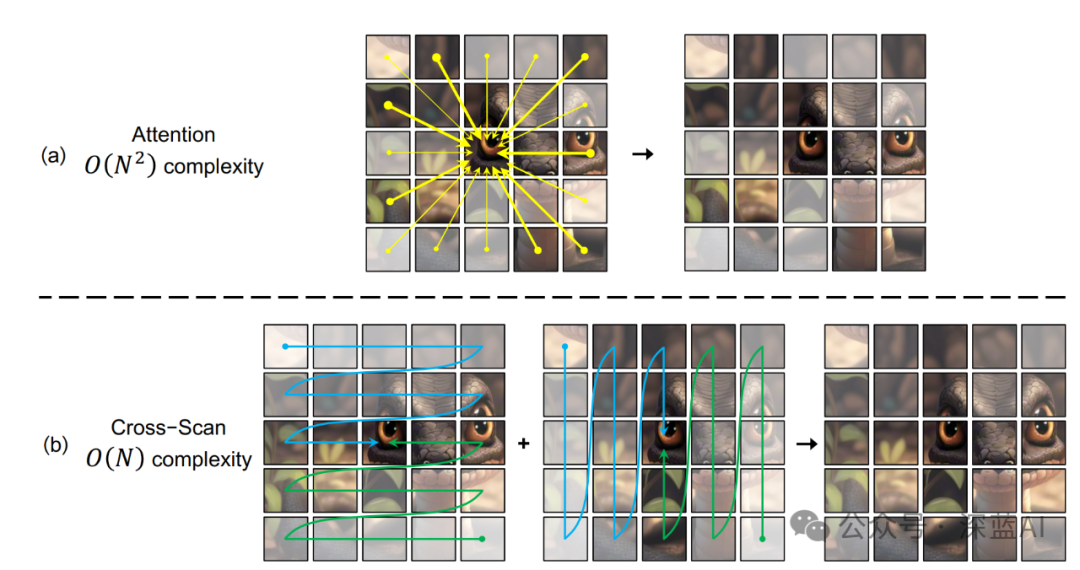 ▲Figure 1|Comparison of Attention Mechanism and the Proposed CSM ©️【Deep Blue AI】
▲Figure 1|Comparison of Attention Mechanism and the Proposed CSM ©️【Deep Blue AI】
The paper conducts extensive experiments on various visual tasks to validate the effectiveness of the proposed VMamba. As shown in Figure 2, on the ImageNet-1K dataset, VMamba demonstrates stronger or at least comparable performance compared to ResNet, ViT, and Swin models. The paper also conducts experiments on downstream dense tasks, for example: VMambaTiny/Small/Base (with 22/44/75 M parameters respectively) achieves 46.5%/48.2%/48.5% mAP using the Mask R-CNN detector on the COCO dataset, and reaches 47.3%/49.5%/50.0% mIoU using UperNet on the ADE20K dataset. These results indicate that the proposed VMamba is a powerful foundational model. Furthermore, as the input image size increases, although ViT achieves better performance, the growth rate of FLOPs for ViT is significantly higher than that of CNN. The proposed VMamba, in comparison to ViT, achieves comparable performance while experiencing a much smaller growth in FLOPs, approximately linear.
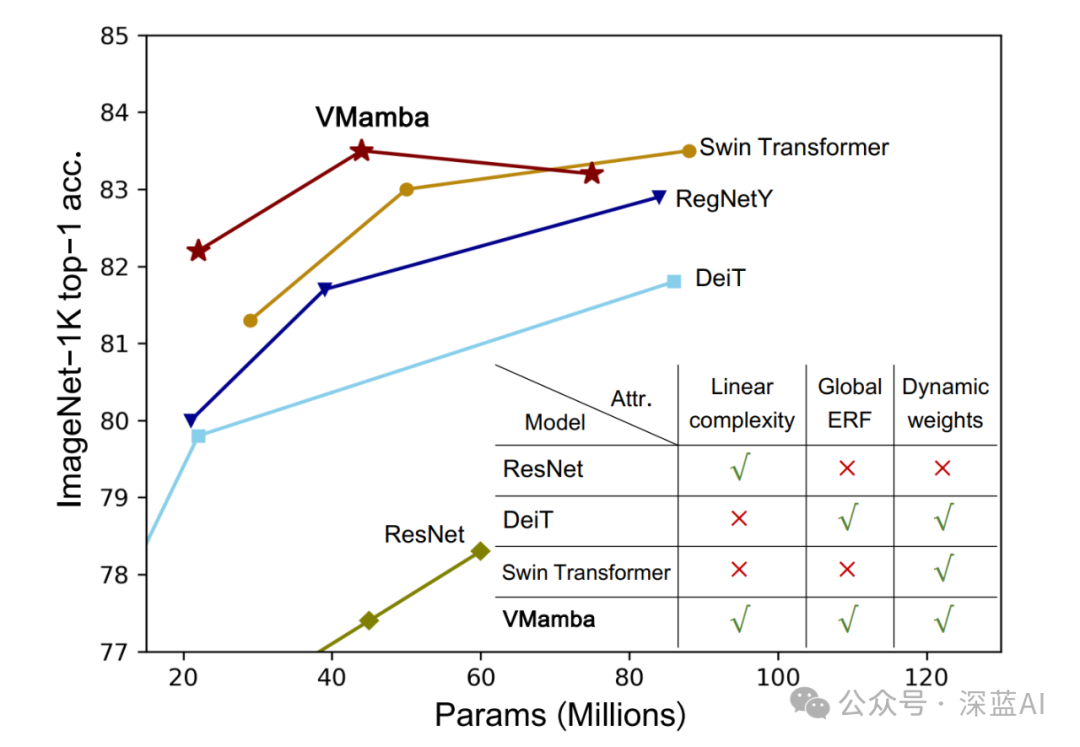 ▲Figure 2|Overall Performance of VMamba on ImageNet-1K Compared to Other Mainstream Algorithm Models ©️【Deep Blue AI】
▲Figure 2|Overall Performance of VMamba on ImageNet-1K Compared to Other Mainstream Algorithm Models ©️【Deep Blue AI】
The contributions of this work are summarized as follows:
● VMamba, a visual state space model, provides global receptive fields and dynamic weights for visual representation learning. VMamba offers an alternative foundational representation model beyond CNN and ViT.
● The introduction of the Cross-Scan Module (CSM) addresses the transition issue from 1D sequence scanning to 2D image scanning, extending the application of the S6 model to visual data without compromising the characteristics of global receptive fields.
● Extensive visual task experiments were conducted, including image classification, object detection, and semantic segmentation. Experimental results indicate the significant potential of VMamba as a robust foundational model for visual representation.

Deep neural networks continue to drive the advancement of visual perception research. Among them, two representative foundational models for vision are CNN and ViT. Recently, the success of state space models (SSMs) in enhancing computational efficiency on long sequences has garnered widespread attention in the fields of NLP and CV. This paper follows this route and proposes VMamba, a visual representation model based on state space models. The contribution of VMamba lies in providing a usable foundational model beyond CNN and ViT.
Convolutional Neural Networks (CNN) are milestone models in the field of visual perception. Early CNNs were applied to basic tasks such as recognizing handwritten digits and text classification. The most notable feature of CNNs is the design of convolutional kernels, which are used to capture visual information within the receptive field. With the development of GPUs and the rise of large-scale datasets, deeper and more efficient network models have been proposed, enhancing performance across various visual tasks. Additionally, more advanced convolutional operators or network structures have been successively proposed.
Visual Transformers (ViT) are derived from improvements in the NLP field. They have become one of the most promising foundational models for vision. Early ViT models typically required large-scale datasets for training. Later, DeiT utilized techniques in model training to address optimization issues, and more research introduced inductive biases of visual perception into network design. For instance, the CV community proposed multi-level ViTs to gradually reduce the feature resolution in the Backbone. Furthermore, other studies have proposed integrating some advantages of CNNs into ViTs, such as incorporating convolutional operators into ViTs and combining CNN and ViT modules within the network structure.
State Space Models (SSM) are recently proposed models. Deep learning has introduced SSMs as a means of state space transformation. Inspired by state space models in continuous control systems, combined with the HiPPO initialization method, the LSSL model demonstrates the potential of SSMs in addressing long-term dependencies in sequences. However, due to the high computational and storage costs of state representations, LSSL is difficult to apply in practical problems. To address this issue, the S4 model was proposed, normalizing parameters into diagonal structures. Since then, many different structures of state space models have been proposed, such as complex diagonal structures, supporting multi-input multi-output structures, selective mechanisms, etc. These models have since been integrated into large-scale visual representation models.
These models mainly focus on processing long sequences and causal data, such as language understanding and pixel-level one-dimensional image classification, with little research attention given to the field of visual representation.

This research involves the foundational concepts and theories related to VMamba, including state space models, discretization processes, and selective scanning mechanisms. The paper then introduces the core element of VMamba—the two-dimensional state space model. Finally, the paper presents the overall architecture of VMamba.
■4.1 Basic Concepts
●State Space Model:
State space models are typically used to describe time-varying systems, mapping system inputs to system responses. Mathematically, state space models are described in the following differential equation form: where represents the number of state space variables.●Discretization of Differential Equations: For deep learning, the required state transitions are discrete rather than continuous. Therefore, the discretization of states is crucial. Here we consider inputs that refer to a signal flow of length. The above differential equation can be discretized as follows: where. In practice, for the computation of, first-order Taylor expansion is typically used for linear approximation, which can be approximated as follows:
●Selective Scanning Mechanism:
The selective scanning mechanism in the S6 method refers to the fact that all inputs in state transitions come from the input data. This indicates that state space models can utilize contextual information present in the input data, ensuring that weights in the mechanism are always dynamic.
■4.2 Two-Dimensional Selective Scanning
In the introduction and related work, the paper has already discussed the issues of directly applying the S6 method to two-dimensional images—the “direction sensitivity” problem, which leads to the loss of information in the global receptive field. To resolve this issue, the paper proposes a method for 2D selective scanning. The proposed “four-way” scanning process is very intuitive, scanning from the left upper to the right lower, left upper to the right lower, left lower to the right upper, and right upper to the left lower in four directions, as shown in Figure 1. After scanning, we serialize the results of the “four-way” scan, then use the state space model for selective scanning, and finally restore and merge them into a single image, as shown in the following figure.
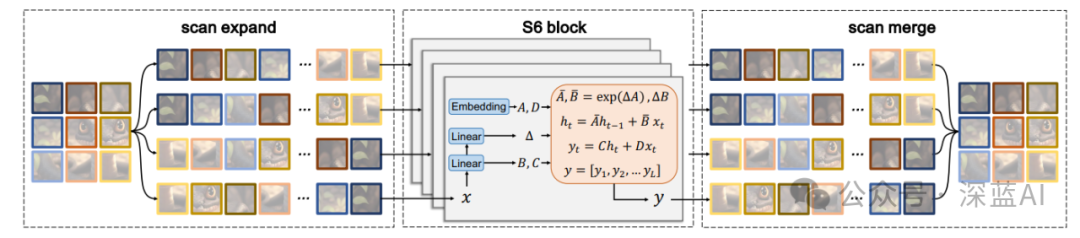 ▲Figure 3|Flowchart of the Two-Dimensional Selective Scanning Mechanism SS2D ©️【Deep Blue AI】
▲Figure 3|Flowchart of the Two-Dimensional Selective Scanning Mechanism SS2D ©️【Deep Blue AI】
The two-dimensional selective scanning described above, namely the CSM module, is the core module of VMamba. This module primarily replaces the attention mechanism in Transformers, maintaining linear computational complexity while preserving global perception.
■4.3 VMamba Model
The overall structure of the Tiny version of VMamba is shown below. The core component is the VSS Block module, which replaces the Encoder module in Transformers. The main difference lies in replacing Attention with SSD two-dimensional selective scanning.
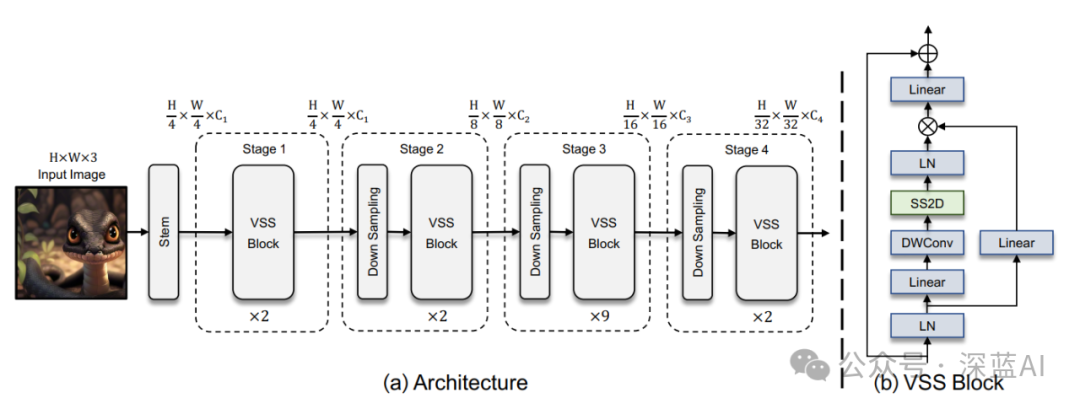 ▲Illustration of VMamba-Tiny Network Structure ©️【Deep Blue AI】
▲Illustration of VMamba-Tiny Network Structure ©️【Deep Blue AI】
The specific network architectures for Tiny/Small/Base are shown in the table below:
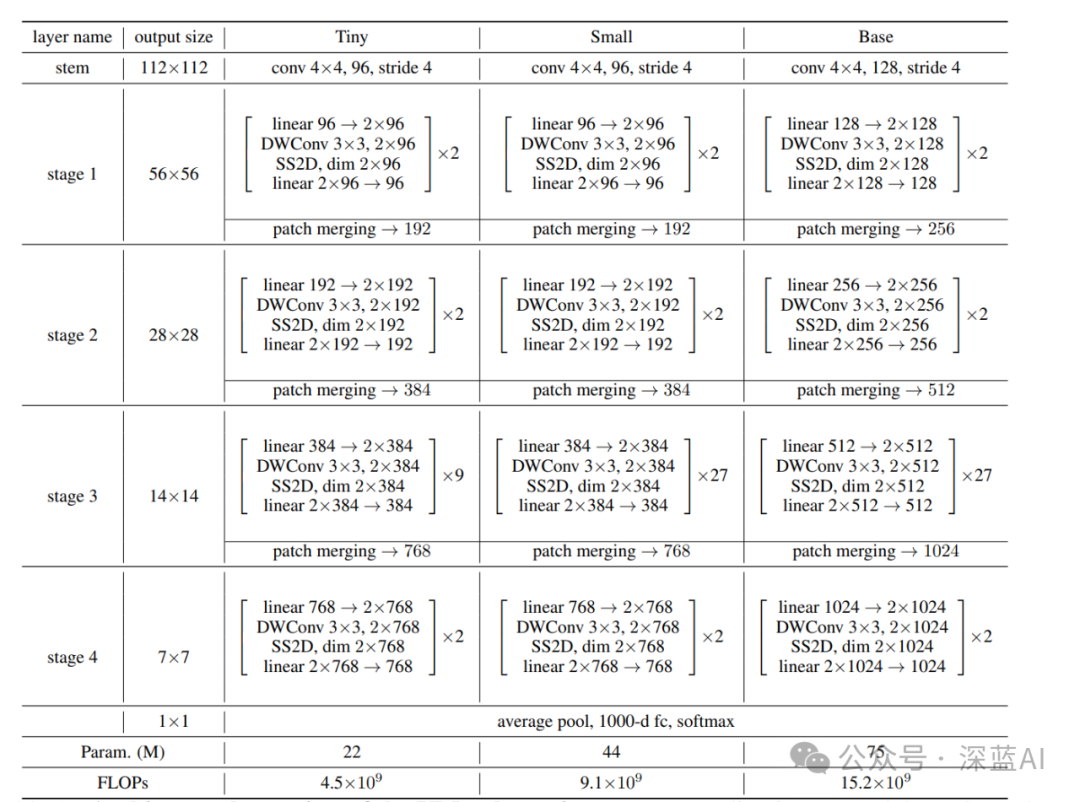 ▲Table 1|Specific Network Architecture Design, Parameter Count, and FLOP Count for VMamba Tiny/Small/Base ©️【Deep Blue AI】
▲Table 1|Specific Network Architecture Design, Parameter Count, and FLOP Count for VMamba Tiny/Small/Base ©️【Deep Blue AI】

The experiments in the paper mainly focus on visual tasks, conducting image classification tasks on the ImageNet-1K dataset, object detection tasks on the COCO dataset, and semantic segmentation tasks on the ADE20K. Based on this, the advantages of VMamba are further analyzed.
■5.1 Image Classification Task—ImageNet-1K
In the image classification task, VMamba was trained from scratch for 300 epochs, and the results compared to other models are shown in the following table. Compared to CNN methods, VMamba achieves higher accuracy; compared to ViT methods, VMamba requires significantly fewer FLOPs to achieve better or comparable accuracy; compared to previous state space model works, VMamba demonstrates higher accuracy.
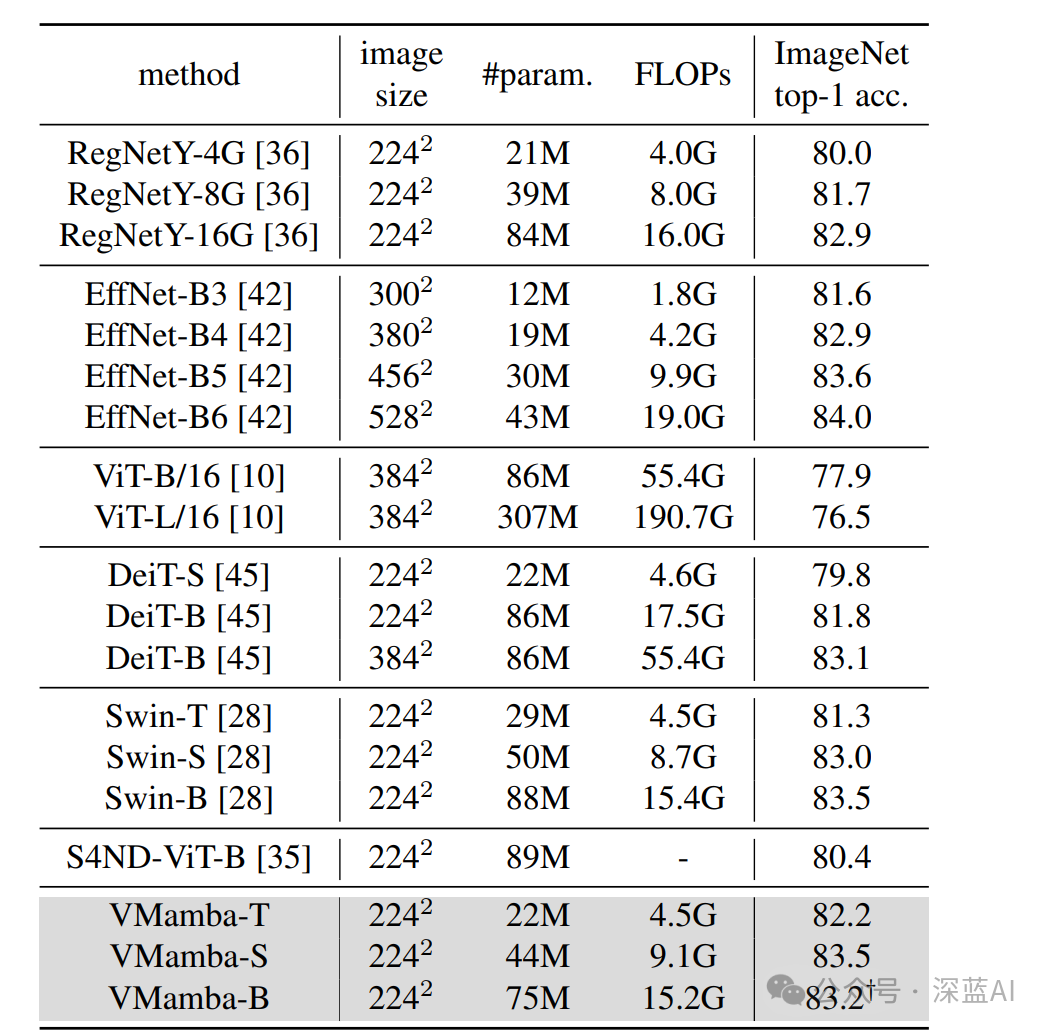 ▲Table 2|Comparison of VMamba with Other Algorithm Models in Image Classification Tasks ©️【Deep Blue AI】
▲Table 2|Comparison of VMamba with Other Algorithm Models in Image Classification Tasks ©️【Deep Blue AI】
■5.2 Object Detection Task—COCO
In the image training task, VMamba performed fine-tuning for 12 and 36 epochs based on the image classification task training. The results are shown in the following table. Compared to CNN methods, VMamba performs better; compared to ViT methods, VMamba requires significantly fewer FLOPs to achieve better or comparable performance; compared to previous state space model works, VMamba performs better.
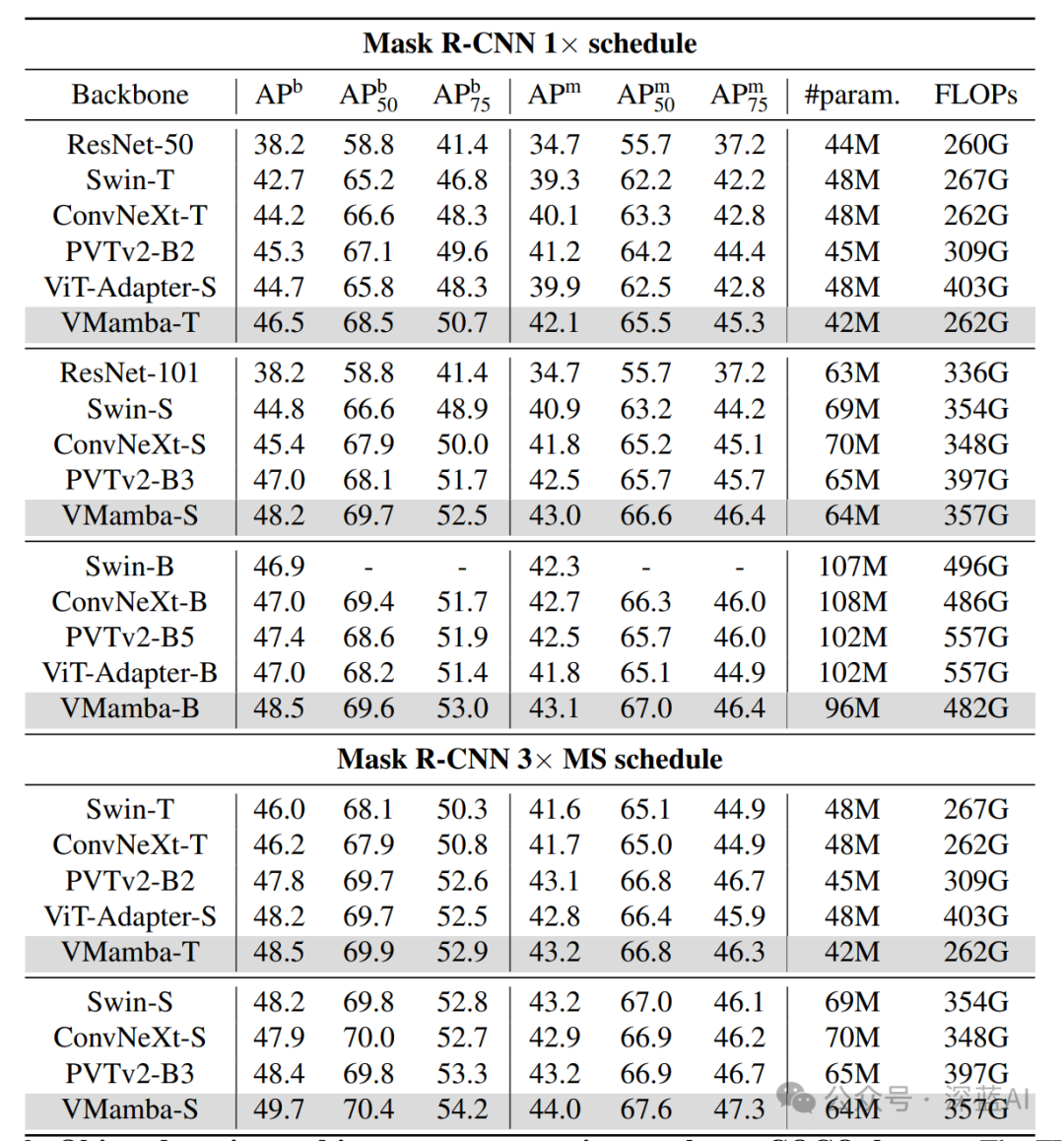 ▲Table 3|Comparison of VMamba with Other Algorithm Models in Object Detection Tasks ©️【Deep Blue AI】
▲Table 3|Comparison of VMamba with Other Algorithm Models in Object Detection Tasks ©️【Deep Blue AI】
■5.3 Semantic Segmentation Task—ADE20K
In the semantic segmentation task, VMamba performed fine-tuning on the pre-trained model of UperHead. The results are shown in the following table. Compared to CNN methods, VMamba performs better; compared to ViT methods, VMamba requires significantly fewer FLOPs to achieve better or comparable performance; compared to previous state space model works, VMamba performs better.
 ▲Table 4|Comparison of VMamba with Other Algorithm Models in Semantic Segmentation Tasks ©️【Deep Blue AI】
▲Table 4|Comparison of VMamba with Other Algorithm Models in Semantic Segmentation Tasks ©️【Deep Blue AI】
■5.4 Experimental Result Analysis
In terms of the effective area of the receptive field, as shown in the following figure, VMamba is the only model that can achieve a global receptive field under linear complexity.
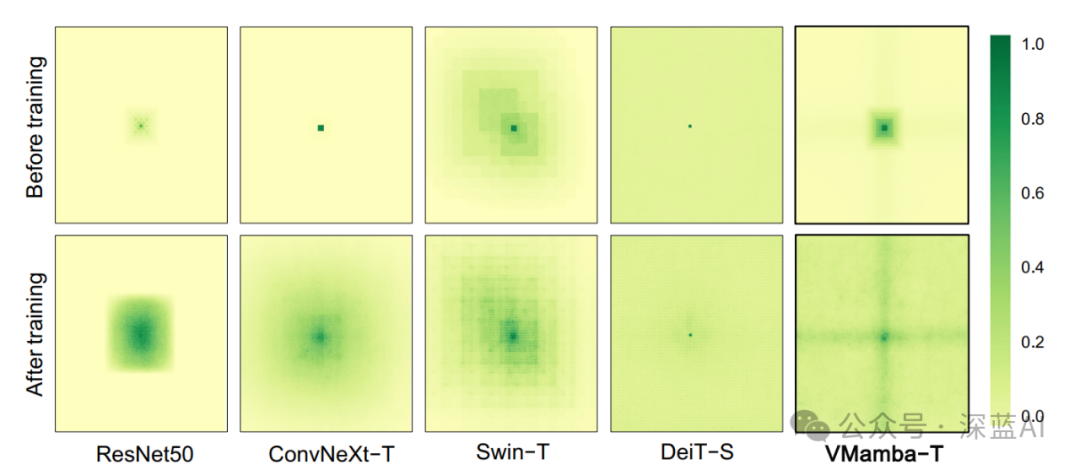 ▲Figure 5|Comparison of VMamba-Tiny in Effective Receptive Field Area with Other Algorithm Models ©️【Deep Blue AI】
▲Figure 5|Comparison of VMamba-Tiny in Effective Receptive Field Area with Other Algorithm Models ©️【Deep Blue AI】
As shown in the following figure, as the image resolution increases, the performance of VMamba is superior to that of other algorithm models, with a smaller increase in FLOPs and higher computational efficiency.
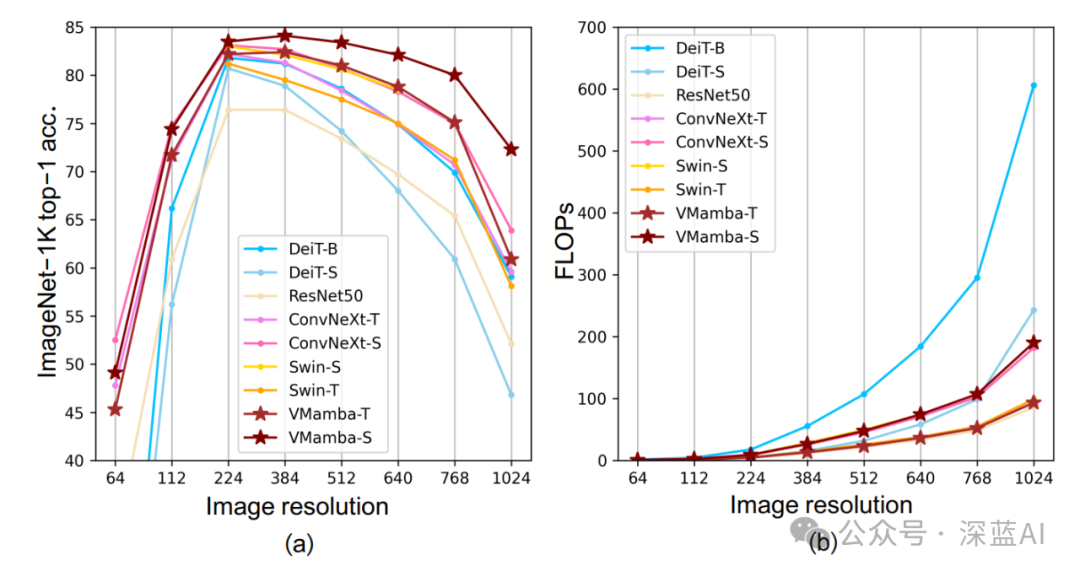
▲Figure 6|Comparison of VMamba with Other Algorithm Models in Performance and FLOPs as Image Resolution Increases ©️【Deep Blue AI】
The VMamba proposed in this paper primarily introduces state space models into image processing, replacing the attention mechanism with the design of CSM while maintaining the global receptive field, reducing computational complexity to linear. Experimental results also indicate that VMamba has the potential to replace ViT as the next mainstream visual representation model backbone.

InverseMatrixVT3D: A Simple and Efficient Implementation of a 3D Occupancy Prediction Model!
2024-02-02

New Framework for Speaker Face Synthesis NeRF-AD Enhances Image Generation Quality and Lip Sync
2024-02-01

【Deep Blue AI】 is continuously recruiting authors. We welcome those who want to transform their research and technical experiences into words to share with more readers. If you want to join, please click on the tweet below for more details👇

Deep Blue Academy’s author team is strongly recruiting! Looking forward to your joining

【Deep Blue AI】‘s original content is created with dedication by the author team. We hope everyone adheres to the original rules and cherishes the authors’ hard work. Please contact the backend for authorization if you wish to reprint, and be sure to indicate that it is from【Deep Blue AI】 WeChat public account, otherwise legal action for infringement will be pursued.
*Click to view and recommend this article*

Click to read the original article directly to the paper