
MLNLP community is a well-known machine learning and natural language processing community in China and abroad, covering NLP graduate students, university teachers, and corporate researchers.The vision of the community is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning, especially for beginners. Reprinted from | Machine Heart Author | Ant Group AI Team
With the rapid development of large language models, their length extrapolating ability has increasingly attracted researchers’ attention. Although this was seen as an innate capability at the inception of the Transformer, the reality is far from it as research deepens. Traditional Transformer architectures invariably exhibit poor reasoning performance beyond the training length.
Researchers have gradually realized that this defect may be related to position encoding, leading to a transition from absolute position encoding to relative position encoding, resulting in a series of related optimizations. Notable examples include: Rotary Position Encoding (RoPE) (Su et al., 2021), Alibi (Press et al., 2021), Xpos (Sun et al., 2022), and the recent position interpolation (PI) developed by Meta (Chen et al., 2023). Reddit users have proposed the NTK-aware Scaled RoPE (bloc97, 2023), all of which aim to endow models with the desired extrapolation capability.
However, while researchers focused solely on position encoding, they overlooked another heavyweight player in the Transformer — self-attention itself. The latest research from Ant Group AI Team indicates that this neglected role is likely to be the key to reversing the situation. The poor extrapolation performance of Transformers is not only due to position encoding; there are still many unresolved mysteries regarding self-attention.
Based on this discovery, Ant Group AI Team has developed a new generation of attention mechanisms that achieve length extrapolation while also performing excellently on specific tasks.

-
Paper Link: https://arxiv.org/abs/2309.08646
-
Github Repository: https://github.com/codefuse-ai/Collinear-Constrained-Attention
-
ModelScope: https://modelscope.cn/models/codefuse-ai/Collinear-Constrained-Attention/summary
-
HuggingFace: Stay Tuned
Background Knowledge
Before delving deeper, let’s quickly review some core background knowledge.
Length Extrapolating
Length extrapolating refers to the ability of large language models to process texts longer than those in their training data. When training large language models, there is usually a maximum sequence length; texts longer than this must be truncated or split. However, in practical applications, users may provide models with longer texts than those used during training. If the model lacks length extrapolation capability or has poor extrapolation performance, this will lead to unexpected outputs and ultimately affect the model’s practical application effectiveness.
Self-Attention
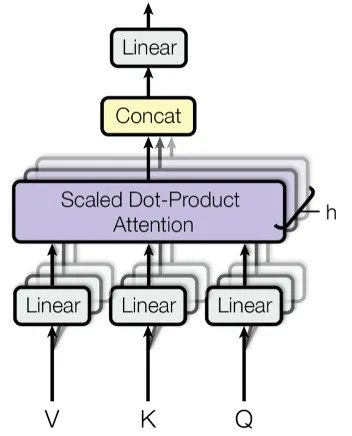
Proposed by (Vaswani et al., 2017), multi-head self-attention is the core of today’s large language models, playing a crucial role in advancing the field of artificial intelligence. A visual description is provided in Figure 1, and this work has been widely recognized, so it will not be elaborated further. Readers unfamiliar with this work can refer to the original paper for more details (Vaswani et al., 2017).
Position Encoding
Since the self-attention mechanism does not directly handle positional information in the sequence, introducing position encoding becomes necessary. However, traditional position encoding methods in Transformers have fallen out of favor due to their poor extrapolation capabilities, and this article will not delve into traditional encoding methods. Readers seeking more related knowledge can refer to the original paper (Vaswani et al., 2017). Here, we will focus on the currently popular Rotary Position Encoding (RoPE) (Su et al., 2021). Notably, Meta’s LLaMa series models (Touvron et al., 2023a) adopt this encoding method.
From an aesthetic modeling perspective, RoPE is a very elegant structure that integrates positional information into the rotation of queries and keys to express relative positions.
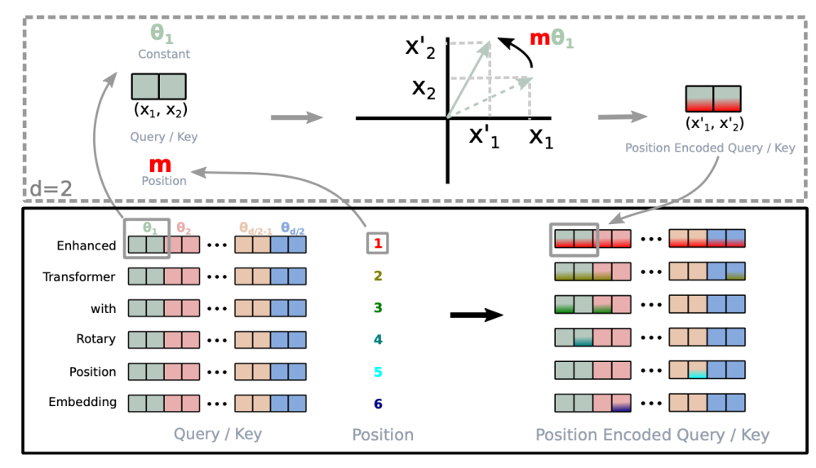
Figure 2. Structure of Rotary Position Encoding, adapted from (Su et al., 2021).
Position Interpolation
Although RoPE performs significantly better in extrapolation compared to absolute position encoding, it still cannot meet the rapidly evolving application demands. Consequently, researchers have proposed various improvements, with PI (Chen et al., 2023) and NTK-aware Scaled RoPE (bloc97, 2023) being typical representatives. However, to achieve the desired effects, position interpolation still requires fine-tuning. Experiments show that even the NTK-aware Scaled RoPE, which claims to allow extrapolation without fine-tuning, can only achieve 4-8 times the extrapolated length under traditional attention architectures, with difficulty ensuring good language modeling performance and long-range dependency capabilities.
Figure 3. Schematic diagram of position interpolation, adapted from (Chen et al., 2023).
CoCA
Previous research has primarily focused on position encoding, assuming that the self-attention mechanism has been perfectly implemented. However, the Ant Group AI Team recently discovered a long-overlooked key: to fundamentally solve the extrapolation performance problem of Transformer models, the self-attention mechanism also needs to be reconsidered.
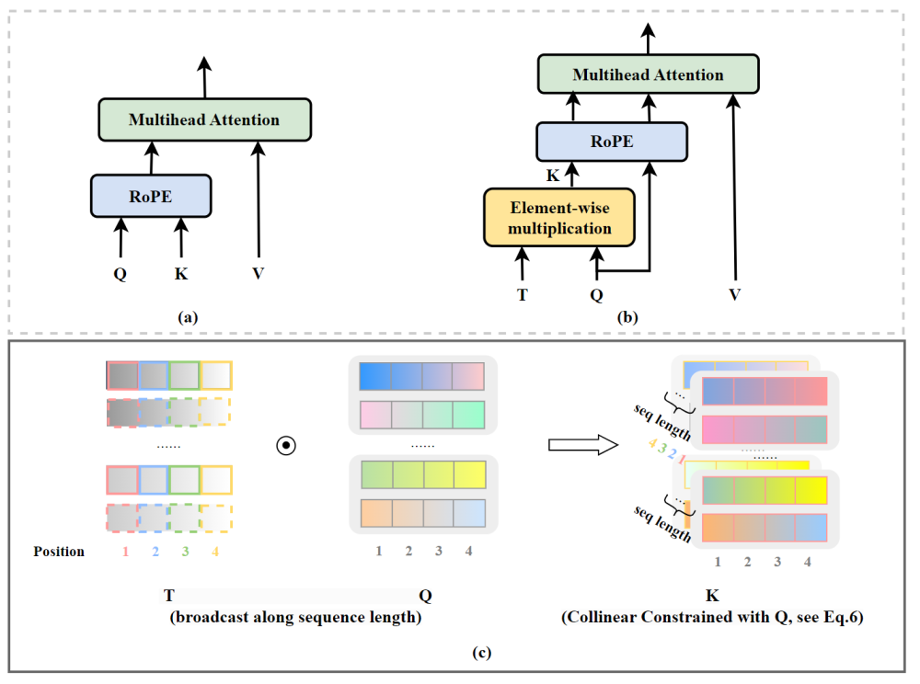
Figure 4. CoCA model architecture, adapted from (Zhu et al., 2023).
Abnormal Behavior of RoPE and Self-Attention
In the Transformer model, the core idea of self-attention is to compute the relationships between queries (q) and keys (k). The attention mechanism uses these relationships to determine which parts of the input sequence the model should “focus on”.
Consider the input 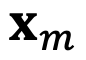 and
and 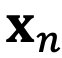 , representing the m-th and n-th position index corresponding to tokens in the input sequence, respectively. Their queries and keys are
, representing the m-th and n-th position index corresponding to tokens in the input sequence, respectively. Their queries and keys are 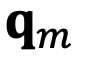 and
and 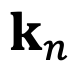 . The attention between them can be represented as a function
. The attention between them can be represented as a function  , and if RoPE is applied, it can be further simplified to a function that only depends on the relative positions of m and n
, and if RoPE is applied, it can be further simplified to a function that only depends on the relative positions of m and n 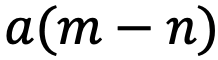 .
.
From a mathematical perspective, 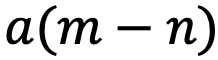 can be interpreted as the sum of the inner products of groups of complex numbers (
can be interpreted as the sum of the inner products of groups of complex numbers (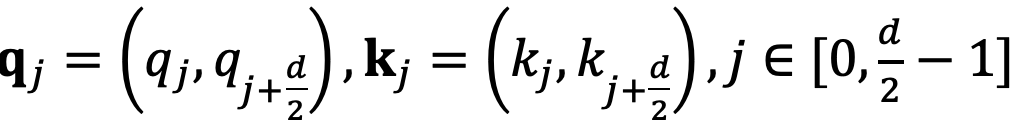 , where d is the hidden dimension, omitting position indices m,n) after rotation. This is intuitively meaningful because positional distances can be modeled as an order, and the inner product of two complex numbers varies with the rotation angle
, where d is the hidden dimension, omitting position indices m,n) after rotation. This is intuitively meaningful because positional distances can be modeled as an order, and the inner product of two complex numbers varies with the rotation angle 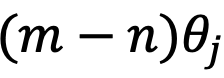 as shown in Figure 5, where
as shown in Figure 5, where 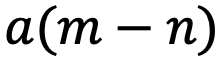 and
and 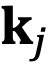 represent the initial angles.
represent the initial angles.
However, it hides a technical defect that has been overlooked until now.
To facilitate understanding, we first consider bidirectional attention models, such as Bert (Devlin et al., 2019) and GLM (Du et al., 2021). As shown in Figure 5, for any group of complex numbers 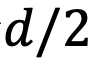 , they have position indices m and n, respectively.
, they have position indices m and n, respectively.
Without loss of generality, we assume there is a small angle less than 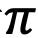 that rotates counterclockwise from
that rotates counterclockwise from 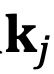 to
to 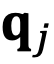 , then there are two possible scenarios for their positional relationships (not considering =, as it is trivial).
, then there are two possible scenarios for their positional relationships (not considering =, as it is trivial).
- Normal Order Relation: When
 , as shown on the right side of Figure 5. The attention score decreases as the positional distance increases (until their relative angles exceed
, as shown on the right side of Figure 5. The attention score decreases as the positional distance increases (until their relative angles exceed  , this part has been discussed in the appendix of the original paper (Zhu et al., 2023)).
, this part has been discussed in the appendix of the original paper (Zhu et al., 2023)). - Abnormal Behavior: However, when
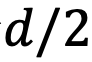 , as shown on the left side of Figure 5, abnormal behavior disrupts the order of the nearest tokens. When
, as shown on the left side of Figure 5, abnormal behavior disrupts the order of the nearest tokens. When 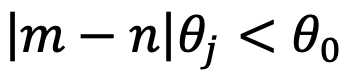 and
and  have a relative angle, it will decrease as the angle increases, meaning that the closest tokens may receive lower attention scores. (We use “may” here because attention scores are the sum of the inner products, perhaps one is negligible. However, subsequent experiments confirmed this importance.) Moreover, neither PI nor NTK-aware Scaled RoPE can eliminate this impact.
have a relative angle, it will decrease as the angle increases, meaning that the closest tokens may receive lower attention scores. (We use “may” here because attention scores are the sum of the inner products, perhaps one is negligible. However, subsequent experiments confirmed this importance.) Moreover, neither PI nor NTK-aware Scaled RoPE can eliminate this impact.
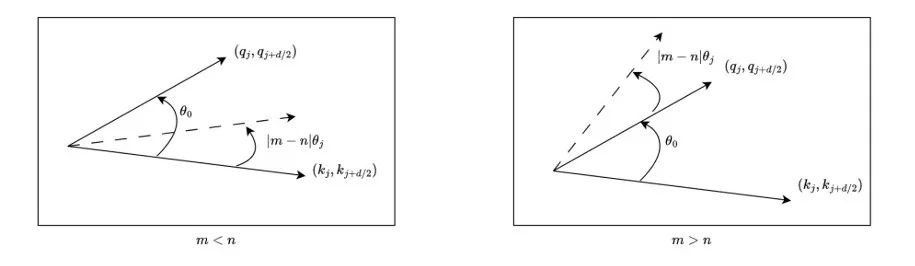
Figure 5. The order in bidirectional models is disrupted, adapted from (Zhu et al., 2023).
For causal models, although m is always greater than n, the same issue exists. As shown in Figure 6, for certain j, when there is an angle less than  that rotates counterclockwise from
that rotates counterclockwise from 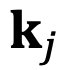 to
to 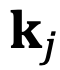 , the same problem persists.
, the same problem persists.
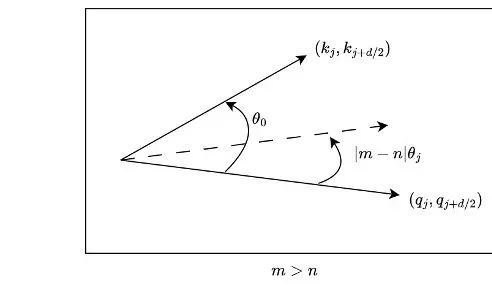
Figure 6. The order in causal models is disrupted, adapted from (Zhu et al., 2023).
Collinear Constrained Attention (CoCA)
Based on the above analysis of the abnormal behaviors of RoPE and self-attention, it is evident that merely addressing position encoding is not the solution. The fundamental solution is to set the initial angle between queries and keys in self-attention to 0, which leads to the concept of Collinear Constrained Attention.
For detailed derivations and formulas, we will not elaborate here; readers can refer to the original text for in-depth understanding.
It is particularly noteworthy that the theoretical explanations provided in the paper indicate:
-
Stable Long-Range Decay Characteristics: CoCA exhibits more stable long-range decay characteristics compared to RoPE.
-
Memory Bottleneck and Solutions: CoCA poses a risk of introducing memory bottlenecks, but the paper offers highly efficient solutions, making the computational and spatial complexity of CoCA nearly indistinguishable from the original self-attention structure. This is an important feature that enhances the practicality of CoCA.
-
Seamless Integration: CoCA can be seamlessly integrated with existing interpolation techniques (the paper experiments with NTK-aware Scaled RoPE) and achieves performance far superior to the original attention structure without requiring fine-tuning. This means that models trained with CoCA inherently possess near-infinite extrapolation capabilities, a sought-after feature for large language models.
Experimental Conclusions
The paper compares CoCA with RoPE (Su et al., 2021) and ALibi (Press et al., 2021) in terms of extrapolation performance, yielding exciting results. The corresponding models are denoted as:
-
Origin: Original attention structure with position encoding method as RoPE
-
ALibi: Original attention structure with position encoding method as ALibi
-
CoCA: Model structure from the paper with position encoding method as RoPE
For detailed experimental backgrounds, please refer to the original text.
Long Text Modeling Capability
The paper evaluates the long text language modeling capabilities of CoCA against the Origin and ALibi models. This evaluation uses 100 documents, each containing at least 8,192 tokens, randomly sampled from the PG-19 dataset (Rae et al., 2019). All three models have a training length of 512 and a model size of 350M.
Figure 7 illustrates a noteworthy trend: when the inference length exceeds the training length, the perplexity of the Origin model rapidly diverges (>1000). In contrast, the CoCA model maintains low perplexity, even at 16 times its training length, without showing a divergence trend.
NTK-aware Scaled RoPE (bloc97, 2023), as a method that does not require fine-tuning for extrapolation, was allowed in the experiments. However, even when applying the dynamic NTK method to the Origin model, its perplexity remains significantly higher than that of CoCA.
ALibi performs best in terms of perplexity, while CoCA achieves results comparable to ALibi after applying the dynamic NTK method.
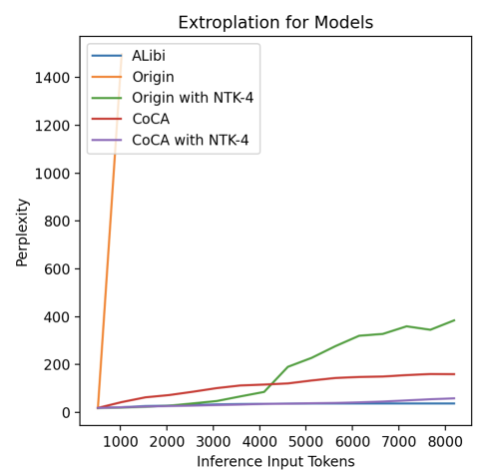
Figure 7. Sliding window perplexity test results, adapted from (Zhu et al., 2023).
Capturing Long-Range Dependencies
Perplexity is an indicator of a language model’s proficiency in predicting the next token. However, it does not fully represent an ideal model. While local attention performs well in terms of perplexity, it often struggles to capture long-range dependencies.
To assess this issue more thoroughly, the paper employs the key retrieval comprehensive evaluation task proposed by (Mohtashami & Jaggi, 2023) to evaluate CoCA against the Origin and ALibi models. In this task, there is a hidden random key that needs to be identified and retrieved from a long document.
As shown in Figure 8, models like ALibi, which have certain local assumptions, perform well in perplexity tasks but face irreparable disadvantages in capturing long-range dependencies. When extrapolating by 1 times the length, the accuracy begins to drop rapidly, ultimately falling below 10%. In contrast, even when the test sequence length extends to 16 times the original training length, CoCA consistently demonstrates high accuracy, exceeding 60% at 16 times the extrapolated length. This is 20% higher than the Origin model and over 50% higher than ALibi.
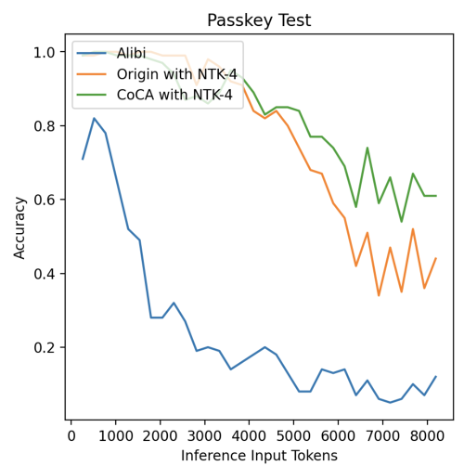
Figure 8. Performance curve for random key identification and retrieval, adapted from (Zhu et al., 2023).
Hyperparameter Stability
Due to the application of the dynamic NTK method in the experiments, the paper delves into the scaling factor hyperparameter stability of the Origin and CoCA models under the dynamic NTK method.
As shown in Figure 9, the Origin model exhibits severe fluctuations (200-800) across different scaling factors, while the CoCA model remains relatively stable (60-70). Furthermore, from the detailed data in Table 4, it can be seen that the worst perplexity performance of the CoCA model is still over 50% better than the best perplexity performance of the Origin model.
In the Passkey experiment, the Origin and CoCA models exhibited similar characteristics to those in the perplexity experiments. The CoCA model maintained high accuracy across different scaling factors, while the Origin model’s accuracy dropped below 20% at scaling factor=8. Additionally, from the detailed data in Table 5, it can be seen that even at the best performance scaling factor=2, the Origin model still lags behind the CoCA model by 5%-10% in accuracy.
At the same time, the Origin model’s perplexity performance at scaling factor=2 is poor, reflecting the difficulty of the original attention structure in simultaneously ensuring performance in both perplexity and capturing long-range dependencies during length extrapolation. In contrast, CoCA achieves this.
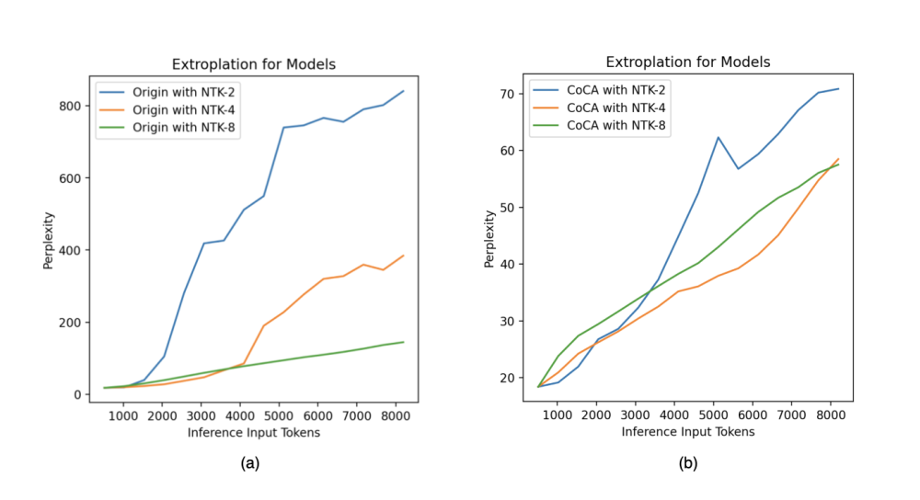
Figure 9. Perplexity of the Origin model and CoCA under different scaling factors, adapted from (Zhu et al., 2023)
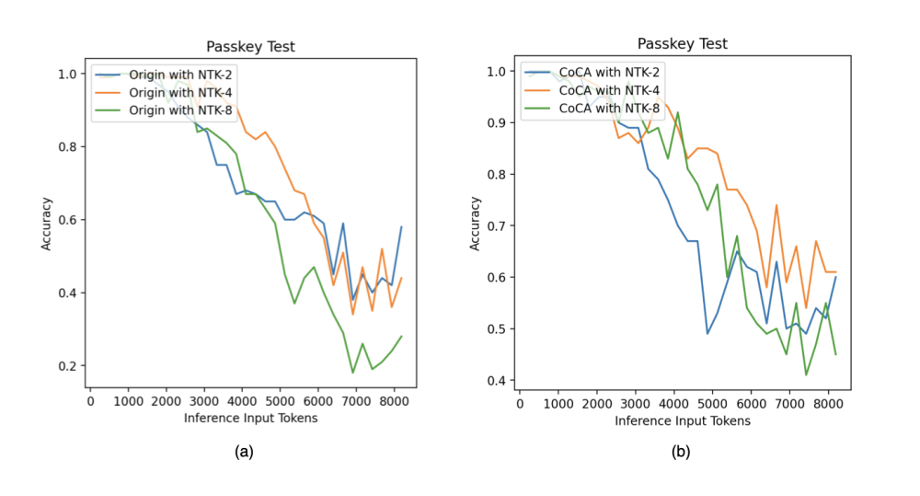
Figure 10. Accuracy of Origin model and CoCA under different scaling factors, adapted from (Zhu et al., 2023)
Attention Scores in Length Extrapolation
As explored in the PI (Chen et al., 2023) paper, the failures of large language models in length extrapolation are directly related to the outliers in attention scores (which are usually very high). The paper further investigates this phenomenon, which also indirectly illustrates why the CoCA model outperforms traditional attention structures in length extrapolation.
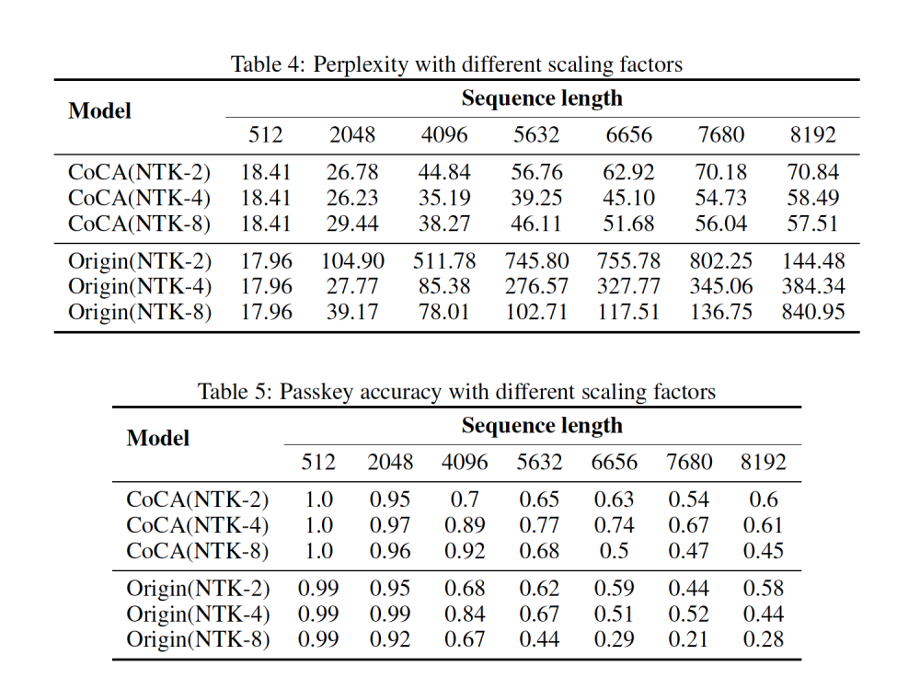
The experiment used a random segment of length 1951 tokens from the PG-19 dataset (Rae et al., 2019), approximately 4 times the model training length.
As shown in Figure 11, (a1) represents the attention scores of the Origin and CoCA models without using the dynamic NTK method, (b1) shows the scores after applying the dynamic NTK method, with low layers indicating the 6th, 12th, and 18th layers, and last layer indicating the 24th layer. (a2) is an enlarged version of (a1) for the last 500 tokens, and (b2) is similarly enlarged.
-
From (a1) and (b1), it can be found that the Origin model has a few outliers in attention scores, with values 10-20 times larger than those of the CoCA model.
-
Due to these outliers affecting the observation effect, (a2) locally enlarges the last 500 tokens, revealing that the last layer attention scores of the Origin model are almost 0, indicating that the Origin model fails to focus on nearby tokens during length extrapolation.
-
From (b2), it can be seen that after applying the dynamic NTK method, the attention scores of the Origin model at nearby tokens become abnormally high. This abnormal phenomenon is closely related to the previously discussed abnormal behavior of RoPE and self-attention, indicating that the Origin model may suffer from severe overfitting at nearby tokens.
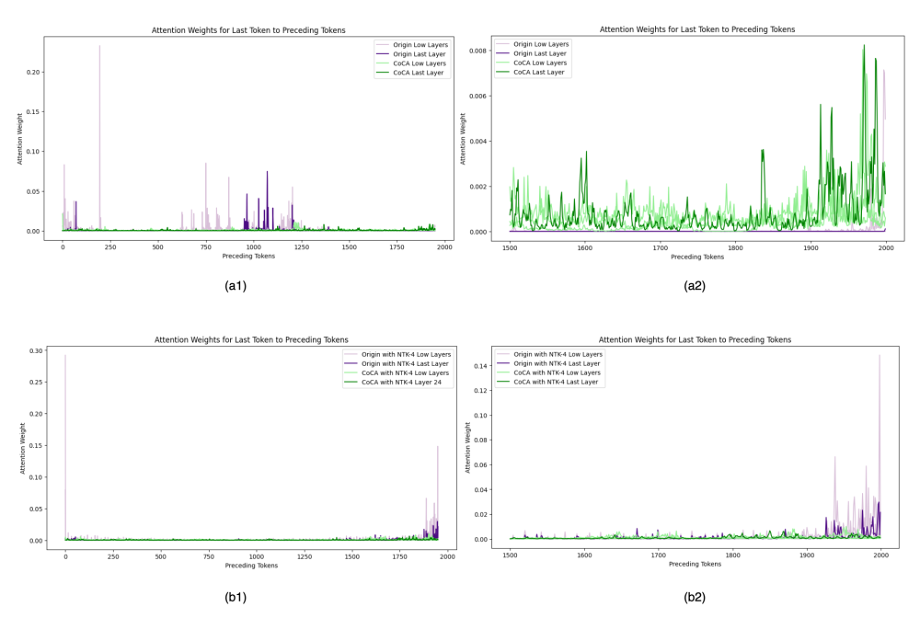
Figure 11. Attention scores in extrapolation, adapted from (Zhu et al., 2023)
Human Eval
Beyond the paper, we further evaluated the performance of the CoCA and Origin models on human eval using the same data (120B tokens), the same model size (1.3B), and the same training configuration, with the following comparisons to the Origin model:
-
Compared to the Origin model, both are at a comparable level, and CoCA does not suffer a loss in expressive capability due to its extrapolation capability.
-
The Origin model performs much better in Python and Java than in other languages, while CoCA’s performance is relatively balanced, which is related to the smaller amount of Go data in the training corpus, indicating that CoCA may have potential few-shot learning capabilities.
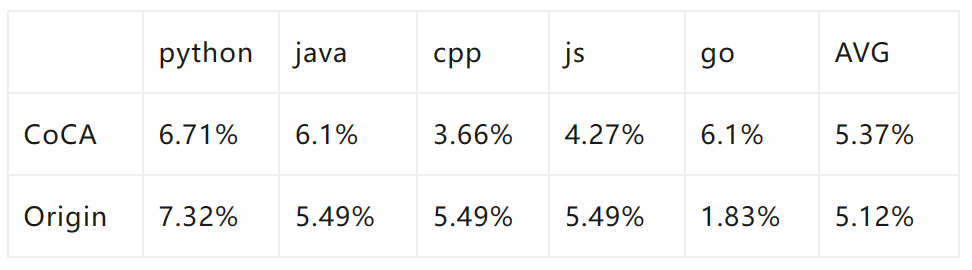
Conclusion
In this work, the Ant Group AI Team discovered some abnormal behavior between RoPE and the attention matrix, which leads to a disorder in the interaction between the attention mechanism and position encoding, especially for tokens at the nearest positions that contain key information.
To fundamentally solve this problem, the paper introduces a new self-attention framework called Collinear Constrained Attention (CoCA). The mathematical evidence provided in the paper demonstrates the superior characteristics of this method, such as stronger long-range decay forms and computational and spatial efficiency in practical applications.
Experimental results confirm that CoCA exhibits outstanding performance in long text language modeling and long-range dependency capture. Furthermore, CoCA can seamlessly integrate with existing extrapolation, interpolation techniques, and other optimization methods designed for traditional Transformer models. This adaptability indicates that CoCA has the potential to evolve into an enhanced version of Transformer models.
References
Shiyi Zhu, Jing Ye, Wei Jiang, Qi Zhang, Yifan Wu, and Jianguo Li. Cure the headache of transformers via collinear constrained attention, 2023.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. ArXiv, abs/2104.09864, 2021. URL https://api.semanticscholar.org/CorpusID:233307138.
Ofir Press, Noah A. Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. ArXiv, abs/2108.12409, 2021. URL https://api.semanticscholar.org/CorpusID:237347130.
Yutao Sun, Li Dong, Barun Patra, Shuming Ma, Shaohan Huang, Alon Benhaim, Vishrav Chaudhary, Xia Song, and FuruWei. A length-extrapolatable transformer. ArXiv, abs/2212.10554, 2022. URL https://api.semanticscholar.org/CorpusID:254877252.
Shouyuan Chen, ShermanWong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation. ArXiv, abs/2306.15595, 2023. URL https://api.semanticscholar.org/CorpusID:259262376.
bloc97. Ntk-aware scaled rope allows llama models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation, 2023. URL https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_modes_to_have/.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, TimothÅLee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models. ArXiv, abs/2302.13971, 2023a. URL https://api.semanticscholar.org/CorpusID:257219404.
Hugo Touvron, Louis Martin, Kevin R. Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Daniel M. Bikel, Lukas Blecher, Cristian CantÅLon Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony S.Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel M. Kloumann, A. V. Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, R. Subramanian, Xia Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zhengxu Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models. ArXiv, abs/2307.09288, 2023b. URL https://api.semanticscholar.org/CorpusID:259950998.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. ArXiv, abs/1810.04805, 2019. URL https://api.semanticscholar.org/CorpusID:52967399.
Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. Glm: General language model pretraining with autoregressive blank infilling. In Annual Meeting of the Association for Computational Linguistics, 2021. URL https://api.semanticscholar.org/CorpusID:247519241.
Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, and Timothy P. Lillicrap. Compressive transformers for long-range sequence modelling. ArXiv, abs/1911.05507, 2019. URL https://api.semanticscholar.org/CorpusID:207930593.
Amirkeivan Mohtashami and Martin Jaggi. Landmark attention: Random-access infinite context length for transformers. ArXiv, abs/2305.16300, 2023. URL https://api.semanticscholar.org/CorpusID:258887482.
About DevOpsGPT
DevOpsGPT is an open-source project initiated by us, focused on large models related to the DevOps field and mainly divided into three modules.
The DevOps-Eval introduced in this article is one of the evaluation modules, aiming to build industry standard evaluations for LLMs in the DevOps field. Additionally, there are two other modules: DevOps-Model and DevOps-ChatBot, which are dedicated to large models and intelligent assistants in the DevOps field, respectively.
Our goal is to genuinely enhance efficiency and cost savings in the DevOps field, encompassing development, testing, operations, monitoring, and other scenarios, by integrating large models.
We hope that relevant practitioners will contribute their wisdom to make “there is no difficult coder in the world” a reality, and we will regularly share our experiences and attempts in the LLM4DevOps field.
Welcome to use, discuss, and co-build
(1) ChatBot – Out-of-the-box DevOps intelligent assistant: https://github.com/codefuse-ai/codefuse-chatbot
(2) Eval – Industry standard evaluation for LLMs in the DevOps field: https://github.com/codefuse-ai/codefuse-devops-eval
(3) Model – Dedicated large model for the DevOps field: https://github.com/codefuse-ai/CodeFuse-DevOps-Model
(4) CoCA – Ant Group’s self-developed new generation transformer: https://github.com/codefuse-ai/Collinear-Constrained-Attention
Technical Group Invitation

△ Long press to add assistant
Scan the QR code to add the assistant on WeChat
Please note: Name-School/Company-Research Direction(e.g.: Xiao Zhang-Harbin Institute of Technology-Dialogue System) to apply to join the Natural Language Processing/Pytorch and other technical groups
About Us
MLNLP community is a grassroots academic community jointly built by scholars in machine learning and natural language processing from both China and abroad. It has now developed into a well-known community in the field of machine learning and natural language processing, aimed at promoting progress between the academic and industrial circles and enthusiasts in machine learning and natural language processing.The community provides an open communication platform for relevant practitioners in further education, employment, and research. Everyone is welcome to follow and join us.
