VMamba: Revolutionizing Visual Transformers as the Next Mainstream Backbone?
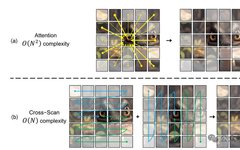
Paper Title: VMamba: Visual State Space Model Authors: Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Yunfan Liu Compiled by: Frank Reviewed by: Los Convolutional Neural Networks (CNNs) and Visual Transformers (ViTs) are currently the two most popular foundational models for visual representation. CNNs have impressive scalability with linear … Read more