

Contrastive Language-Image Pre-training (CLIP) has gained wide attention for its excellent zero-shot performance and outstanding transferability. However, training such large models typically requires substantial computation and storage, posing a barrier for general users with consumer-grade computers.
To address this observation, this paper explores how to achieve competitive performance using only an Nvidia RTX 3090 GPU and 1TB of storage.
On one hand, the authors simplify the Transformer block structure and combine weight inheritance with multi-stage knowledge distillation (WIKD), thereby reducing parameters and improving inference speed during training and deployment. On the other hand, facing the convergence challenges posed by small datasets, the authors generate synthetic captions for each sample as data augmentation and design a novel Pair Matching (PM) loss to fully leverage the distinction between positive and negative image-text pairs.
Extensive experiments show that the authors’ model can achieve new state-of-the-art trade-offs between data quantity, parameters, and accuracy, which may further popularize the CLIP model in the relevant research community.
1 Introduction
Pre-trained large image-text foundation models, such as the Contrastive Language-Image Pre-training (CLIP) model [28], have recently attracted significant attention in the fields of computer vision and natural language processing. These models demonstrate excellent zero-shot performance and robustness across a wide range of downstream tasks, such as image-text retrieval and classification (Zhu et al., 2023). However, the enormous computation and storage costs of CLIP-like models hinder their further popularity. For instance, MobileCLIP [33] is trained on 256xA100 GPUs with a global batch size of 65,536, requiring 140 TB of local storage for the corresponding dataset DataCompDR-1B. Additionally, the large parameter size (e.g., the CLIP-B/16 model [28] contains 86.2M image encoder parameters and 63.4M text encoder parameters) leads to increased inference latency, posing challenges for deployment on devices with limited computational resources. These drawbacks set barriers for general users without sufficient computational resources and datasets to engage in the training and deployment of large-scale models.
In practical applications, consumer-grade GPUs typically have memory no greater than 24GB (e.g., Nvidia RTX 3090), and storage capacity may be less than 1TB. Training CLIP-like models in such resource-constrained contexts requires addressing two primary issues. First, the number of parameters that need to be trained must be minimized while retaining as much existing model knowledge as possible. Second, small datasets need to be appropriately augmented, and more effective methods must be developed to fully utilize the internal associations between image-text pairs within limited samples.
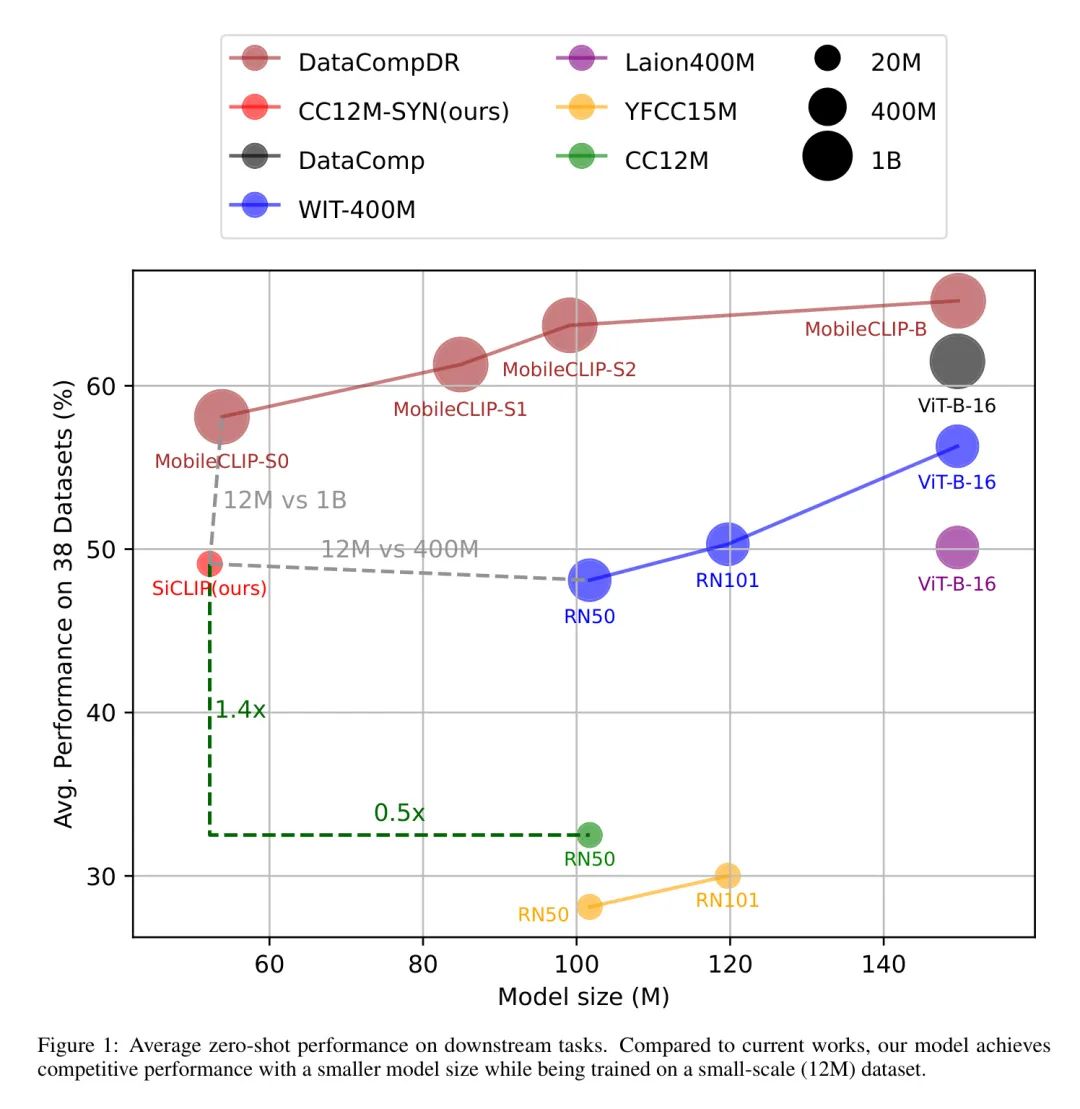
This paper investigates how to train a lightweight CLIP model using only one RTX 3090 GPU and 1TB of storage, thereby popularizing CLIP-like model research on consumer-grade computers. To this end, the authors first propose simplifying the traditional Transformer block into SAS-P blocks and adopting a weight-sharing strategy. Then, by inheriting the weights of existing models and extracting knowledge, they can further reduce the number of parameters required for training. Regarding the dataset, the authors choose the widely used CC12M [1] as the base. This dataset not only has a smaller scale but also suffers from low label quality, which poses difficulties for the convergence of the model training process. To address this issue, the authors add multiple text labels to each image sample in CC12M, creating a new dataset called CC12M-SYN. Furthermore, to extract valuable information from such a small dataset, the authors introduce Pair Matching (PM) loss to help the model capture the distinction between positive and negative image-text pairs. These methods significantly improve the convergence speed of model training in the authors’ extensive experiments. Finally, through performance comparisons on 38 datasets (as shown in Figure 1), the proposed SiCLIP framework achieves new state-of-the-art levels of data quantity-parameter-accuracy trade-offs.
Authors’ Contributions: The contributions of this work can be summarized as follows:
The authors propose a systematic framework for training lightweight CLIP models on consumer-grade computers, including dataset construction and the corresponding training process, called SiCLIP. In SiCLIP, the computational and storage costs are reduced while maintaining competitive performance with other large-scale models.
The authors simplify the structure of the CLIP model by sharing weights between SAS-P blocks and combine weight inheritance with multi-stage knowledge distillation (WIKD) to reduce memory requirements during training and deployment.
A new loss function called PM loss is designed, which predicts whether image-text pairs match during training. Combined with the authors’ enhanced CC12M-SYN dataset, PM loss can leverage the distinction between positive and negative image-text pairs. Experimental results show that both the new dataset and PM loss can significantly improve training efficiency while slightly increasing dataset size.
2 Related Work
Efficient Training for CLIP
Since CLIP emerged as a large-scale image-text foundation model, demonstrating astonishing zero-shot performance across various downstream tasks, numerous related studies have aimed to enhance its training efficiency and model size. For example, fine-grained image-text alignment [42], data augmentation [23, 20, 33], unimodal self-supervision [23, 20], and contrastive learning in the image-text label space [39]. Additionally, Zhai et al. [45] proposed a dual Sigmoid loss as a simple alternative to contrastive loss, proving its effectiveness during small-batch training. However, the need to compute the matching pairs between all positive and negative image-text pairs may lead to quadratic computational complexity. Li et al. [19] employed fine-grained image-text matching (ITM) loss as a supplement to contrastive loss, but ITM requires a multi-layer Transformer-based encoder to encode multimodal fine-grained features, which is not suitable for lightweight models.
Methods based on weight inheritance (WI) and knowledge distillation (KD) [13] have also been employed to achieve efficient training. TinyCLIP [36] trains compact CLIP models through cross-modal affinity simulation and WI. Yang et al. [38] explored the effectiveness of different KD methods for CLIP training.
High-quality datasets are also crucial for effective training. Fang et al. [6] utilized filtering methods to remove noisy samples, and Gadre et al. [7] proposed a similar approach. However, the remaining descriptions are still insufficient. Recent studies [40; 18] indicate that synthetic descriptions generated from pre-trained description generation models can enhance dataset quality.
Simplifying the Transformer Architecture
In recent years, with the remarkable success of Transformers in various tasks, many efforts have been dedicated to simplifying the Transformer architecture to improve its training and inference efficiency. Yu et al. [44] demonstrated that the general structure of Transformer blocks is more critical for their performance, thus allowing for the elimination of attention-based token mixers, which often become prohibitively expensive due to the quadratic complexity of multi-head self-attention (MHSA) on long sequence representations. Additionally, early research on CNNs and Transformers has shown that shallow layers primarily focus on local patterns, while deeper layers tend to capture high-level semantics or global relationships [14; 37; 5], indicating that modeling global relationships through MHSA is often unnecessary in early stages. Based on these facts, Liu et al. [22] proposed a hierarchical Transformer and employed shifted windows to limit self-attention calculations to non-overlapping local windows while allowing cross-window connections for higher efficiency. In another line of work, Pan et al. [26] and Guo et al. [9] introduced convolutional layers into the early layers of Transformers. Building on these works, Vasu et al. [32] proposed RepMixer as a token mixer that reduces memory access costs by leveraging structural reparameterization through the removal of shortcuts in the network.
As a simple yet effective lightweight approach, weight-sharing strategies have been applied in many Transformer-based models. Dehghani et al. [3] first proposed utilizing Transformer layers for natural language processing tasks with different motivations: they viewed repeated network layers as a complementary way for Transformers to introduce cyclical inductive biases and observed that their method outperformed the original Transformer on multiple tasks. Jaegle et al. [17] adopted cross-attention layer weight sharing in multimodal pre-training. Hernandez et al. [12] explored sharing different parts of conformers [8] at different granularities, constrained by model size. Recently, He et al. [10] studied the standard Pre-LN Transformer block [34] through signal propagation theory and proposed a simplified parallel structure Transformer block equipped with shape attention [25] as a token mixer, called Simplified Attention Subblock Parallel (SAS-P), which demonstrates impressive performance on multiple linguistic tasks while being faster in inference and utilizing fewer parameters. The authors’ work is the first attempt to extend SAS-P into the multimodal domain and further simplify it by sharing token mixer weights between adjacent blocks.
3 Methods
In this section, the authors first introduce their simplified model structure, which is achieved by sharing weights among SAS-P blocks. They then present an efficient training method called WIKD. Next, the authors introduce a new loss function called Pair Matching (PM) loss to further improve training performance. Finally, the authors also enhance the data diversity and quality by adding synthetic captions to the CC12M dataset used for training the model, while minimizing additional storage space. The new dataset is called CC12M-SYN. Figure 2 illustrates the overall framework of the authors’ approach.
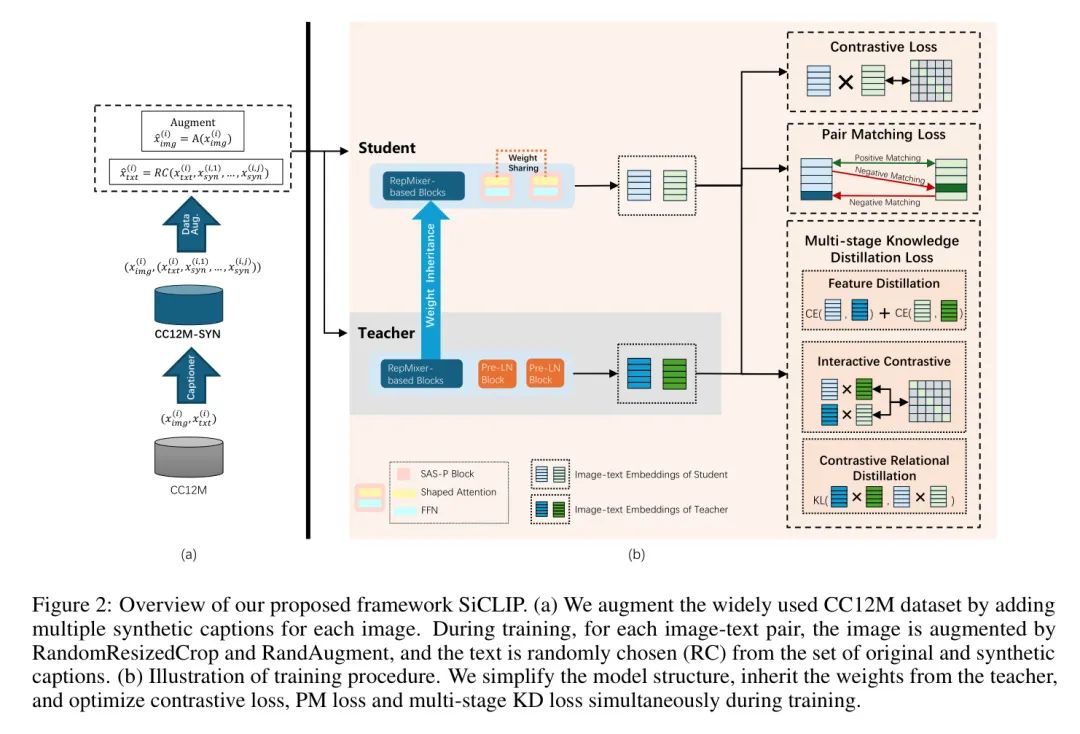
Simplifying Model Structure by Sharing Weights Among SAS-P Blocks
The authors build their architecture based on the latest MobileCLIP-S0 model [33] and enhance it in various ways. The MobileCLIP-S0 framework features a hybrid structure of image encoder and text encoder, which includes a collaborative arrangement of convolution-based and MHSA (Mobile Hyperspectral-to-Spatial Augmentation) blocks. However, for each MHSA-based block, MobileCLIP-S0 only adopts the standard Pre-LN block, where MHSA serves as a mixer [34], as shown in Figure 3 (left).
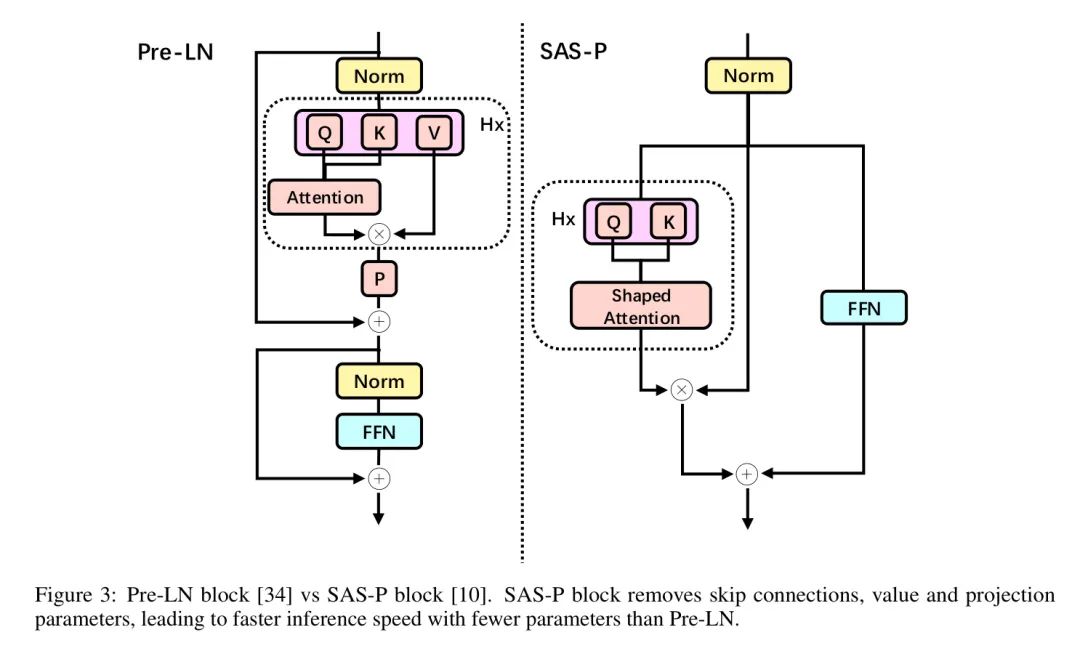
The authors first begin by reducing the Shortcut parameters within each pre-connected block. These connections create bottlenecks in memory access and inference speed, making it crucial to employ lightweight MHSA-based block designs. Furthermore, it has been demonstrated that the feedforward layers of attention modules can be seamlessly integrated into Transformer layers without degrading their performance [31; 24].
As illustrated on the right side of Figure 3, SAS-P (He and Hofmann, 2024) is a simplified parallel Transformer module that eliminates shortcut connections while also removing value and projection parameters. It employs shape attention [25] as its token mixer to prevent signal degradation after eliminating shortcut connections, making the attention matrix more identifiable and thus maintaining good signal propagation. The attention matrix of shape attention is given by:
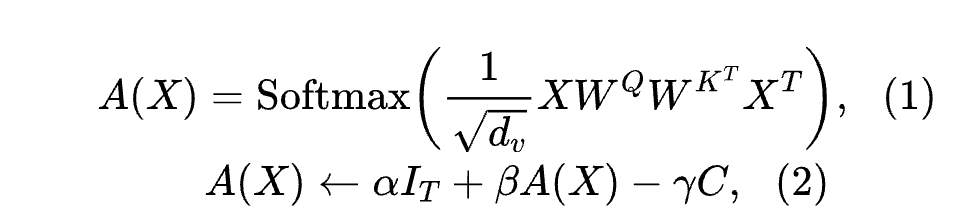
where denotes the SAS-P input, and are the query and key matrices, respectively, is the model dimension, is the identity matrix, and , , , are learnable parameters. is the center matrix, where each element is set to . During initialization, , , , are set to , leading to and , which are effective for good signal propagation. SAS-P demonstrates impressive performance on multiple linguistic tasks while achieving faster inference speeds than Pre-LN and using fewer parameters. To further simplify the model structure, the authors evaluate the Jensen-Shannon (JS) divergence between adjacent MHSA-based blocks (see Figure 4). Low JS divergence indicates that sharing weights between these matrices will not degrade performance. Therefore, before applying KD during training, the authors’ “student” model replaces all Pre-LN blocks with SAS-P blocks and shares weights between these blocks. As a result, the authors’ model’s image encoder has approximately 14% fewer parameters compared to MobileCLIP-S0, and only 11% in OpenAI-B/16 [28]. To benefit from small datasets, a widely used approach is to utilize a task-relevant pre-trained Backbone network and add some task-specific layers [15]. Inspired by the idea of using a Backbone network, the authors employ WI [36] to train CLIP on small datasets. In practical applications, since the authors modified the MHSA-based modules of the MobileCLIP-S0 structure while keeping the RepMixer-based modules unchanged (which are already efficient), the authors can directly inherit the weights of these modules from the well-pretrained MobileCLIP-S0 on large datasets. In this case, the inherited modules can be viewed as a “Backbone.” The authors then freeze these inherited layers and train only on the newly added SAS-P blocks using a very small dataset. The application of the above methods reduces gradient storage, allowing the authors to use a larger batch size to maintain the performance of contrastive learning. Furthermore, the authors consider their model a mobile model of MobileCLIP-S0 and perform multi-stage knowledge distillation during training, thus further enhancing performance. Specifically, the authors apply knowledge distillation in the unimodal feature space (Stage 1), contrastive relation space (Stage 2), and interactive contrastive relation space (Stage 3). For a batch of image-text pairs, the student model first simulates the distribution of the teacher’s image and text feature distributions by optimizing the feature distillation loss ():
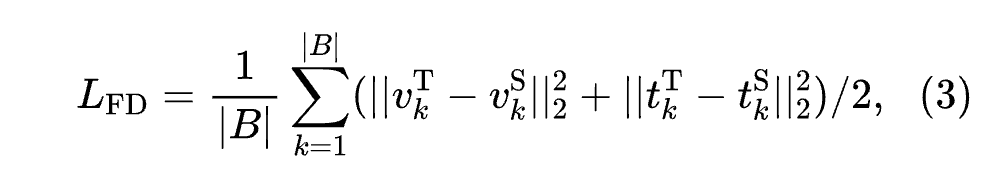
where and represent the (image, text) features of the teacher and student models, respectively, where is the batch size. Then, it computes the contrastive relation distillation loss () and interactive contrastive relation loss () to simulate the distribution of the similarity matrices of image-text pairs in the contrastive relation space and interactive contrastive relation space, defined as follows:
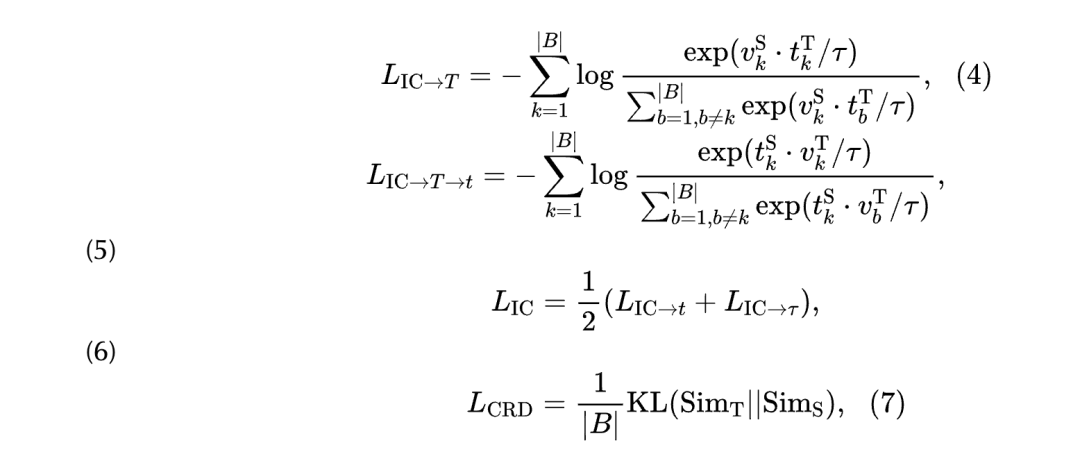
The authors’ final distillation loss is defined as:
where is a learnable temperature parameter, and Sim denotes the similarity matrix between image features and text features.
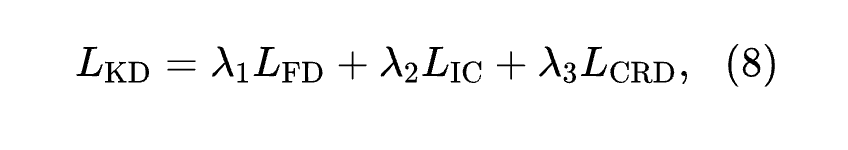
λ1, λ2, λ3 are hyperparameters.
Pair Matching (PM) Loss
CLIP models trained on small datasets often perform poorly in zero-shot performance [38]. The authors believe that one possible reason for this phenomenon is that models trained with less data have greater difficulty in distinguishing semantically similar image-text pairs. Therefore, the authors propose constructing an auxiliary hyperplane to help the model determine whether image-text pairs match. See Figure 5.
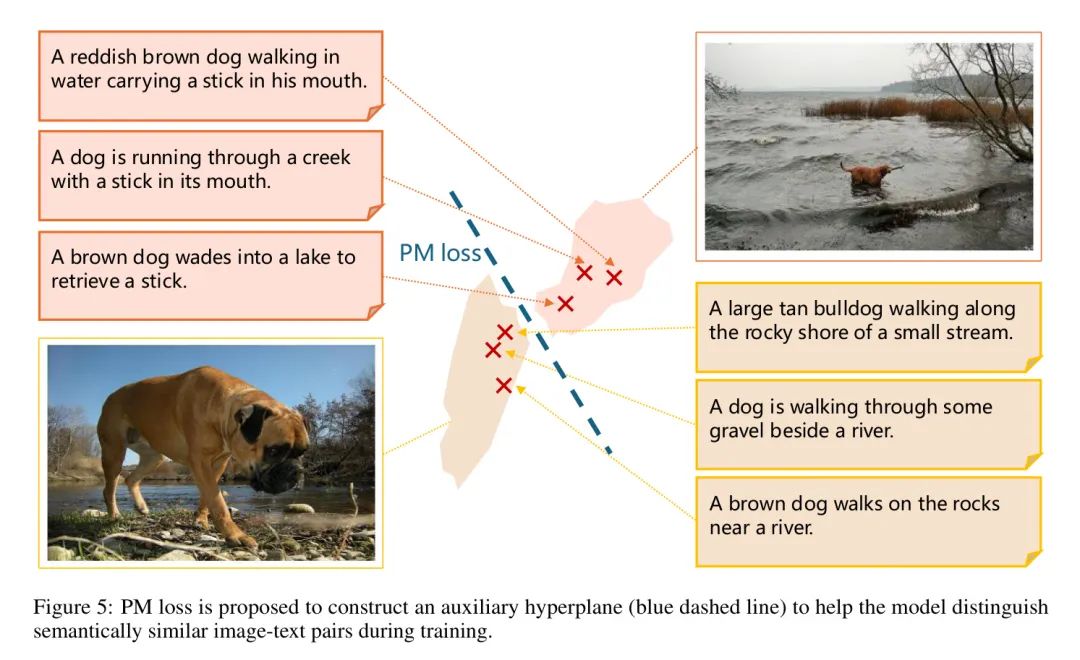
Specifically, the authors add an additional binary matching task. Given a set of image-text pairs, the authors first extract positive image-text pairs and calculate their matching pairs and , with the following formula:
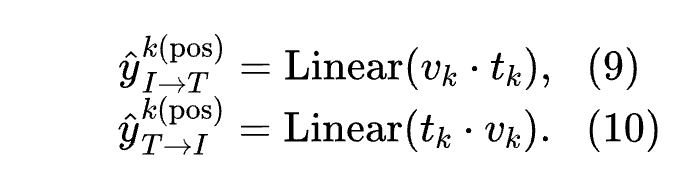
For negative sample pairs, for each image, the authors select a negative text based on the image-to-text similarity matrix (if their embeddings are similar, a negative text is chosen with higher probability). Similarly, this process is also applied to each text. Thus, the negative matching logits are defined as:
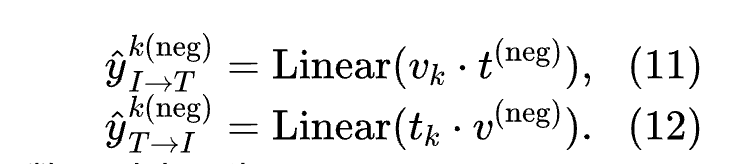
Therefore, the PM loss function proposed by the authors can be expressed as:
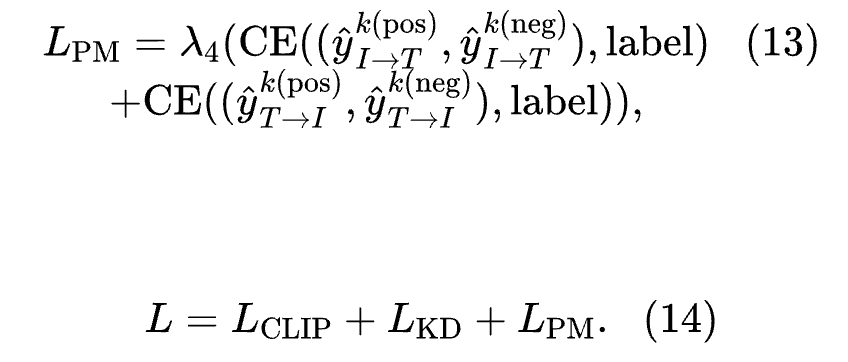
CC12M-SYN Dataset
The image-text datasets used for training CLIP models predominantly originate from the internet, which inherently contains noisy samples with insufficient descriptiveness. When using small datasets, the diversity and quality of data become particularly important. Adding synthetic captions is a cost-effective and efficient way to enhance diversity and quality. The authors utilize the widely used CC12M [1] dataset and generate multiple synthetic captions for each image in the dataset using coca [43], resulting in CC12M-SYN. Figure 6 showcases some examples from CC12M-SYN with synthetic captions. During training, the authors randomly select one text from either the original or synthetic captions. Thus, a sample in CC12M-SYN comprises an image and either a synthetic or original description.

4 Experiments
Implementation Details
The authors adopted a Warm-up strategy during the first ten thousand training iterations. They used the AdamW optimizer with a batch size set to 1536 and a weight decay of 0.1. The model was trained for 32 epochs on Nvidia RTX 3090, with a learning rate set to 0.001. In the ablation study, the authors set the number of epochs to 9. The authors used MobileCLIP-S0 as the teacher for WIKD. For hyperparameters, they set λ1=4000, λ2=λ3=1, λ4=0.1. Other settings follow CLIP-KD [38].
The authors evaluated zero-shot performance on multiple datasets. Specifically, they used ImageNet-1k [4], ImageNet-V2 [29], ImageNet-R [11], and ImageNet-S [35] to assess zero-shot image classification performance. For zero-shot image-text retrieval, the authors used MSCOCO [21] and Flickr30k [27]. The default metrics are Top-1 accuracy (acc1) in image classification and R@1 in image-text retrieval.
4.1.1 Data Augmentation.
The authors applied random scaling (RandomResizedCrop) and random cropping (RandAugment) for image enhancement. In RandomResizedCrop, the authors set the scaling ratio to (0.08, 1.0) to perform robust augmentation on the original images. Then, they applied RandAugment on the processed images, further increasing the diversity of images by randomly adopting the default 31 augmentation methods ([2]).
Main Results
4.2.1 Zero-shot image-text retrieval.
Table 1 reports the zero-shot image-text retrieval performance on MSCOCO and Flickr30k. Compared to models trained on similar-sized datasets (up to 20 million samples), the authors’ model outperformed all other works on MSCOCO. For Flickr30k, the authors’ model achieved the performance of the current state-of-the-art model TinyCLIP while using fewer parameters. Compared to models trained on large-scale datasets (400M-1B), the authors’ model performed well in competitive performance and surpassed many existing works. For instance, compared to the state-of-the-art MobileCLIP-S0, the authors’ model achieves T2I performance that is only about 1% lower while using approximately 3% of the training samples and 14% fewer image encoder parameters. Furthermore, the authors’ model outperformed DataComp-B/32, OpenAI-X (except B/16), and LAION-B/32 on both I2T and T2I metrics across the two datasets.

4.2.2 Zero-shot image classification on ImageNet.
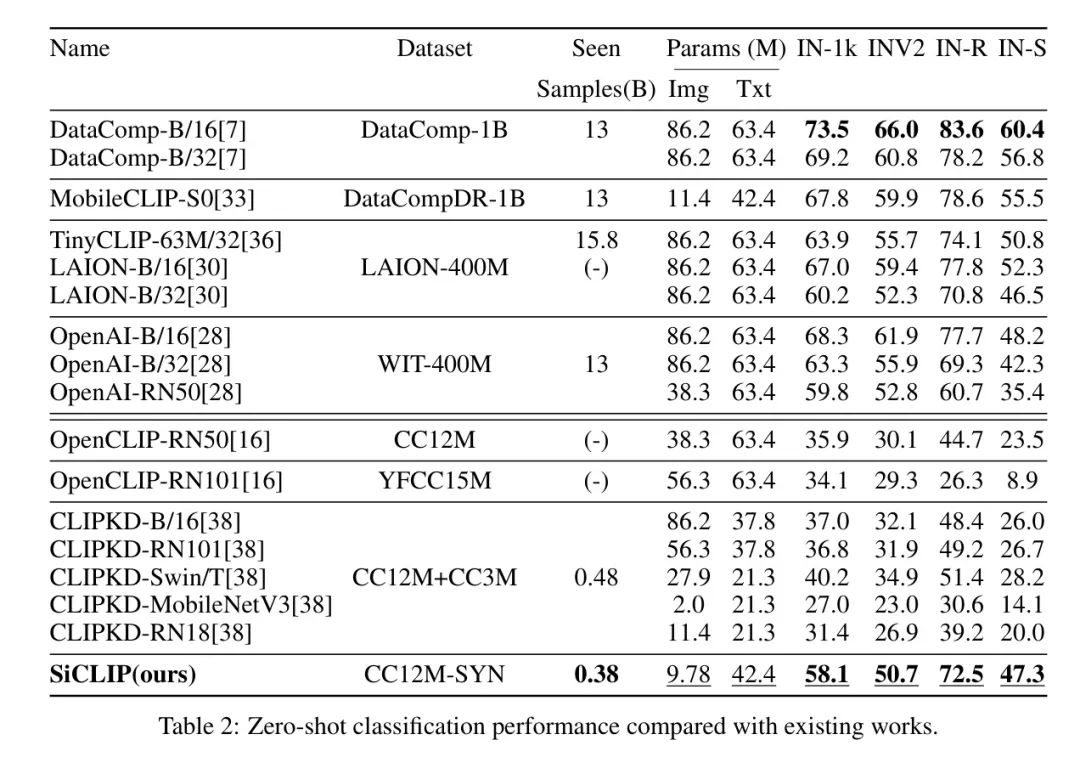
Table 2 reports zero-shot classification performance. Compared to other models trained on similar-sized datasets, the authors’ model outperformed all other works across all reported datasets, demonstrating the effectiveness of the authors’ method. For large-scale datasets, although not the best compared to the latest state-of-the-art DataComp-B/16, the authors still achieved some competitive results compared to several existing works.
4.2.3 Inference Speed.
To evaluate inference speed, the authors conducted simulation experiments on a CPU (Intel(R)-Xeon(R)[email protected]) and compared the average inference speed of the authors’ model with the state-of-the-art MobileCLIP series [33]. As shown in Table 3, when the input sequence contains 1000 images, the authors’ model achieved a processing speed of 39.5 images/second, slightly higher than the state-of-the-art MobileCLIP-S0 (38.2 images/second). This indicates the benefits of adopting SAS-P blocks.
Ablation Studies
4.3.1 Training Efficiency of CC12M-SYN.
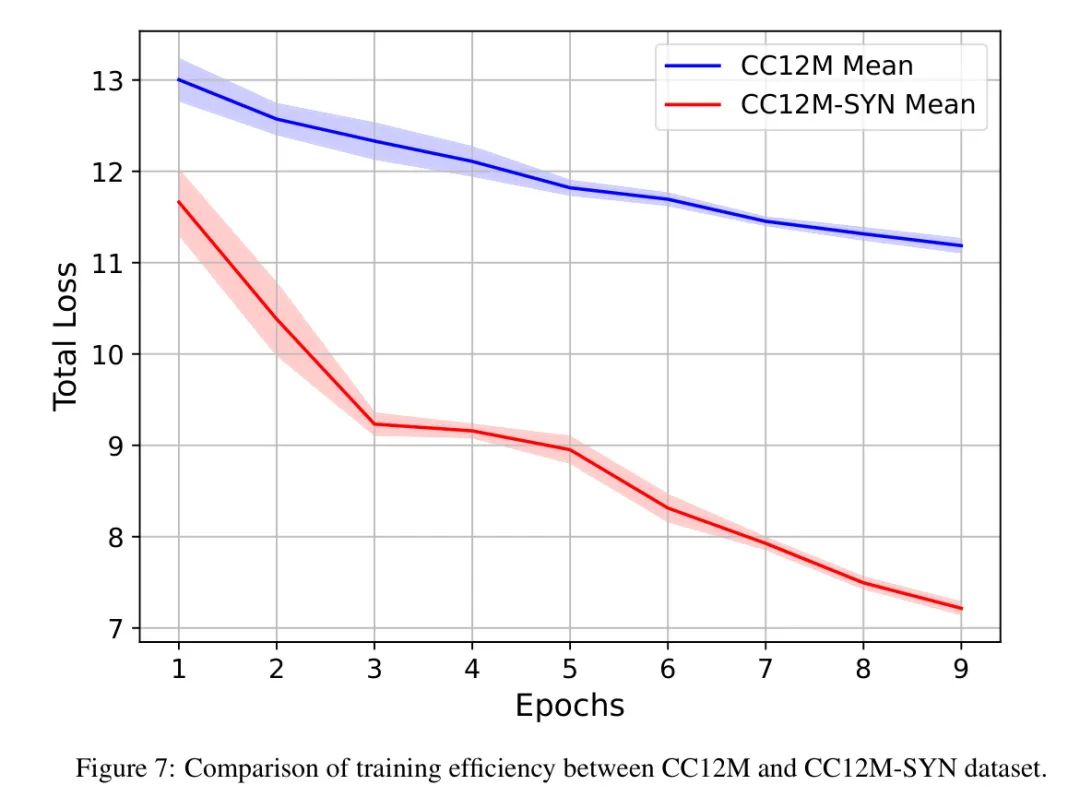
To demonstrate the training efficiency improvement of CC12M-SYN, the authors trained their model for 20 epochs on both CC12M-SYN and CC12M. They reported the average loss curves for the first 9 epochs, along with the zero-shot performance on IN-1k and Flickr30k for the final epoch. Figure 7 reports the loss curves for CC12M and CC12M-SYN, showing that training on CC12M-SYN leads to faster loss reduction. Table 4 indicates that models trained on CC12M-SYN exhibit better performance in zero-shot classification and zero-shot image-text retrieval. These results demonstrate the benefits of synthetic labels for enhancing data diversity and quality.

4.3.2 Analysis of WIKD and PM loss.
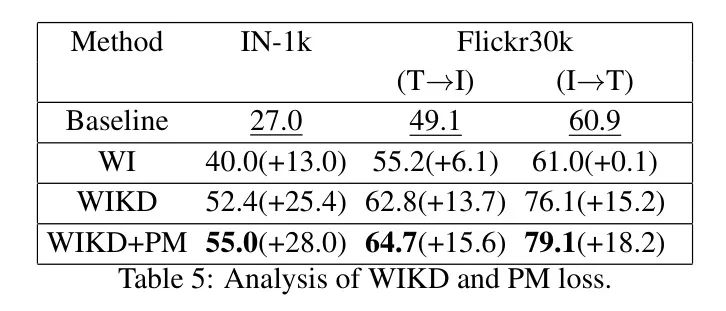
The authors explore the effectiveness of WIKD and PM loss by comparing training with and without WIKD and PM loss (Baseline), as well as training with only WI, only WIKD, and both WIKD and PM loss. The results are shown in Table 5. It indicates that training with only WI can improve zero-shot classification (+13.0 and +6.1/+0.1 in classification accuracy acc1) and image-text retrieval (R@1 retrieval rate +15.9/+15.2). When training with only WIKD, performance is even higher (+25.4 and +15.9/+15.2, respectively). When training with both WIKD and PM loss simultaneously, the model achieves the highest performance. These results clearly demonstrate the effectiveness of WIKD and PM loss.
5 Conclusion
In this work, the authors propose a series of techniques that make training and inference of CLIP models on consumer-grade computers feasible while achieving competitive performance. This is crucial for bringing the outstanding results of foundation models to edge devices.
The authors reduced the model structure and improved inference speed.
Additionally, the authors introduced WIKD and PM loss functions, which contributed to performance improvements and can be utilized for simplifying models in other domains.
Finally, after training on the enhanced CC12M-SYN dataset, the authors’ model achieved competitive performance compared to existing works while using fewer parameters and a smaller training dataset.
References
[0]. Simplifying CLIP: Unleashing the Power of Large-Scale Models on Consumer-level Computers.
