
This article is approximately 11,000 words, recommended reading 10+minutes This article attempts to summarize and review the latest trends in computer vision in MOT.
Paper link: https://arxiv.org/pdf/2209.04796.pdfFollow the WeChat public account“Data派THU”, reply in the background with“20221020” to obtain a review of single-object, multi-object, and learning-based methods!
Abstract
With the development of autonomous driving technology, multi-object tracking has become one of the hot research topics in the field of computer vision. MOT is a key visual task that can address different problems, such as occlusion in crowded scenes, similar appearances, difficulty in detecting small targets, ID switching, etc. To tackle these challenges, researchers have attempted to utilize the attention mechanism of transformers, use graph convolutional networks to obtain the correlation of trajectories, the appearance similarity of targets in different frames with Siamese networks, and have also tried CNN networks based on simple IOU matching and LSTM for motion prediction.To consolidate these dispersed technologies, the author reviewed over a hundred papers from the past three years, attempting to extract the techniques that researchers have focused on in recent years to solve the MOT problem. The author lists numerous applications and possible directions, as well as how MOT relates to real life. The review aims to present different perspectives on the technologies long used by researchers and provide potential researchers with some future directions. Additionally, the author includes popular benchmark datasets and metrics in this review.
Introduction
Object tracking is one of the very important tasks in computer vision. It occurs right after object detection. To complete the object tracking task, one must first locate the target in a frame. Then assign a unique ID to each target. Each identical target in consecutive frames will generate a trajectory. Here, a target can be any category, such as pedestrians, vehicles, athletes in motion, birds in the sky, etc. If the author wants to track multiple targets in one frame, it is called multi-object tracking or MOT.In recent years, there have also been some review papers on MOT [1], [2], [3], [4]. However, they all have limitations. Some methods only include deep learning-based approaches, focus only on data association, analyze problems without well categorizing the papers, and lack introductions to real-world applications.Therefore, in summary, the author organizes this work as follows:
- Identify the main challenges of MOT
- List various commonly used MOT methods
- Introduce MOT benchmark datasets
- Summarize MOT metrics
- Explore various application scenarios
Main Challenges of MOT
Occlusion
Occlusion occurs when the target you want to see is completely or partially hidden or occluded by another target in the same frame. Most MOT methods are based solely on camera data without sensor data. This is why it becomes somewhat difficult for the tracker to track the target’s location when the targets occlude each other. Moreover, in crowded scenes, occlusion becomes more severe to model interactions between people [5]. Over time, using bounding boxes to locate targets has become very popular in the MOT community. However, in crowded scenes, [6] occlusion is difficult to handle because ground truth bounding boxes often overlap. This problem can be partially addressed by jointly handling object tracking and segmentation tasks [7].In the literature, the author can see appearance information and graphical information used to find global properties to solve the occlusion problem [8], [9], [10], [11]. However, frequent occlusions have a significant impact on lower precision in MOT problems. Therefore, researchers have attempted to solve this problem without any hints. In the following figure, (a) illustrates occlusion. In figure (b), the woman in red is almost covered by the lamp post. This is an example of occlusion.

Lightweight Architecture
Although most of the latest solutions to problems rely on heavyweight architectures, they are very resource-intensive. Therefore, in MOT, heavyweight architectures are very unfavorable for real-time object tracking. As a result, researchers have focused on lightweight architectures. There are some additional challenges to consider for lightweight structures in MOT [12]. Bin et al. mentioned three challenges faced by lightweight architectures, such as: object tracking architectures need pre-trained weights for good initialization and fine-tuning on tracking data. Because NAS algorithms require guidance from the target task, they also need reliable initialization. NAS algorithms need to focus on both the backbone network and feature extraction so that the final structure can fully fit the object tracking task. The final architecture needs to compile compact and low-latency building blocks.
Other Common Challenges
MOT architectures are often affected by inaccurate object detection. If the target is not correctly detected, all efforts to track the target will be in vain. Sometimes, the speed of object detection becomes a major factor for MOT architectures. For background distortion, object detection can sometimes become very difficult. Illumination plays a crucial role in object detection and recognition. Therefore, all these factors become more important in object tracking. Motion blur due to the movement of the camera or target makes MOT more challenging. Many times, MOT architectures find it difficult to determine whether a target is a true input target. One of the challenges is the correct association between detection and tracklet.In many cases, incorrect and inaccurate object detection is also a result of low precision. There are also challenges such as similar appearances frequently confusing the model, the start and termination of trajectories being a critical task in MOT, interactions between multiple targets, and ID switching (the same target identified as different in consecutive frames). Due to non-rigid deformations of shape and other appearance characteristics and inter-class similarities, in many cases, people and vehicles pose some additional challenges [13]. For example, the shape and color of vehicles differ from the clothes of people. Finally, smaller targets can form various different visual elements. Liting et al. attempted to address this problem with higher resolution images and higher computational complexity. They also combined hierarchical feature maps with traditional multi-scale prediction techniques [14].
MOT Methods
The multi-object tracking task is typically divided into two steps: object detection and object association. Some focus on object detection, while others focus on data association. These methods are not completely independent, whether in the detection phase or the association phase.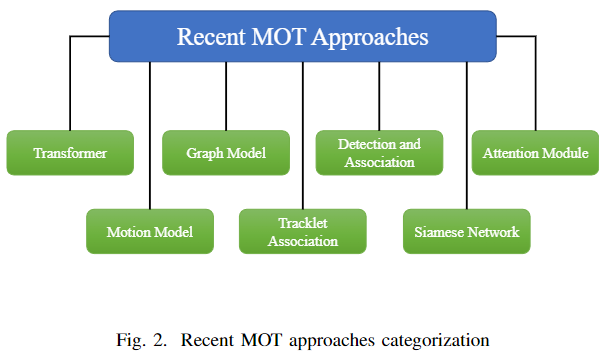
Transformer
Transformer is a deep learning model that, like other models, has two parts: the encoder and the decoder [16]. The encoder captures self-attention, while the decoder captures cross-attention. This attention mechanism helps to remember long-term contextual information. Based on the query-key method, the transformer predicts the output. Although it was previously used solely as a language model, in recent years, visual researchers have focused on it to leverage contextual memory. In most cases, in MOT, researchers attempt to predict the next frame’s position of the target based on previous information, and the author believes that the transformer is the best solution. Since transformers specifically handle sequential information, they can perfectly perform frame-by-frame processing. The following figure is an example of tracking using a transformer.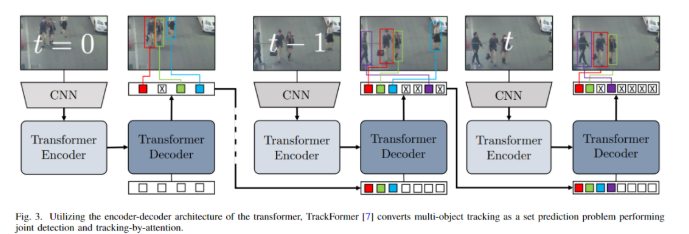 The following table provides a complete summary of transformer-based methods in MOT.
The following table provides a complete summary of transformer-based methods in MOT.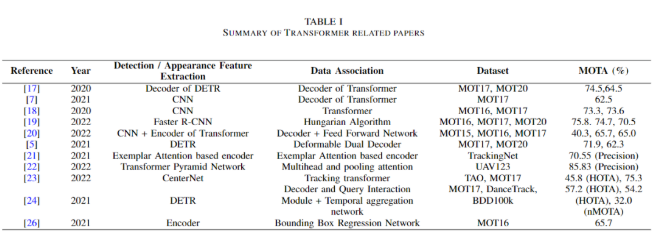
Graph Models
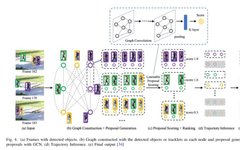
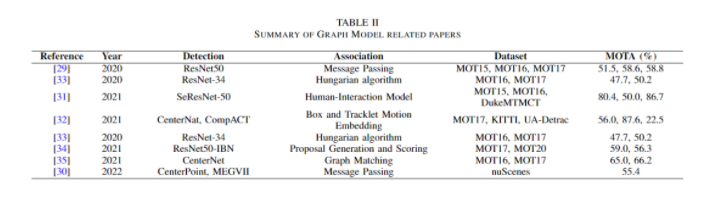
Graph Convolutional Networks (GCN) are a special type of convolutional network where neural networks are applied in a graphical form rather than linearly [27]. Additionally, a recent trend is to use graph models to solve MOT problems, where a set of detected targets from consecutive frames is treated as a node, and the links between two nodes are treated as an edge. Typically, data association is achieved by applying the Hungarian algorithm [28]. The following figure illustrates an example of target tracking based on GCN.
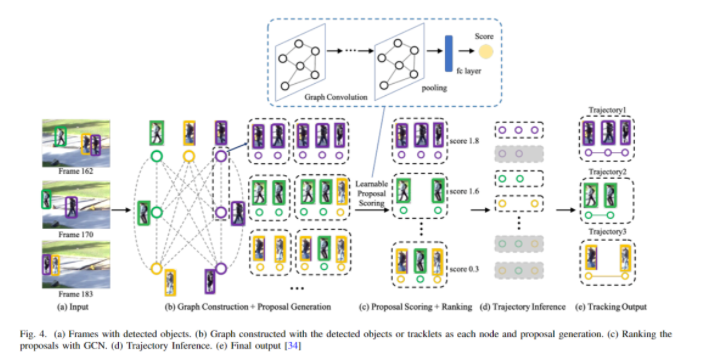
The following table provides an overview of solving MOT problems using graph models.
Detection and Object Association
In this approach, detection is accomplished through any deep learning model. However, the main challenge is associating targets, i.e., tracking the trajectories of the targets of interest [37]. In this regard, different papers follow different approaches.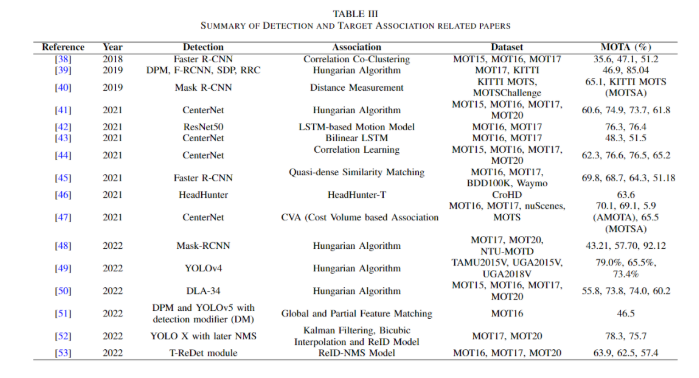 As shown in the table above, several schemes are primarily introduced. Margret et al. chose both bottom-up and top-down approaches [38]. In the bottom-up approach, point trajectories are determined. However, in the top-down approach, bounding boxes are determined. Then, by combining both, a complete trajectory of the target can be found. In [39], to address the association problem, Hasith et al. simply detected targets and used the well-known Hungarian algorithm to associate the information. In 2019, Paul et al. proposed Track-RCNN [40], which is an extension of R-CNN and is evidently a revolutionary task in the MOT field. By 2022, the author can see the diversity of the MOT problem statement. Oluaffunmilola et al. simultaneously performed target prediction while tracking targets [50]. They used FairMOT [54] to detect bounding boxes, then stacked a prediction network and created a Joint Learning Architecture (JLE). Zhi-hong et al. extracted new features for each frame to obtain global information and accumulated partial features for occlusion handling [51]. They fused these two features to accurately detect pedestrians.Except for [52], no paper has taken measures to retain important bounding boxes so that they are not eliminated during the data association phase. After detection, Hong et al. applied Non-Maskable Suppression (NMS) during the tracking phase to reduce the probability of important bounding boxes being removed [53]. Jian et al. also used NMS to reduce redundant bounding boxes from the detector. They re-detected trajectory localization by comparing features and using IoU to re-identify bounding boxes. The final result is a Joint Re-Detection and Re-Identification Tracker (JDI).
As shown in the table above, several schemes are primarily introduced. Margret et al. chose both bottom-up and top-down approaches [38]. In the bottom-up approach, point trajectories are determined. However, in the top-down approach, bounding boxes are determined. Then, by combining both, a complete trajectory of the target can be found. In [39], to address the association problem, Hasith et al. simply detected targets and used the well-known Hungarian algorithm to associate the information. In 2019, Paul et al. proposed Track-RCNN [40], which is an extension of R-CNN and is evidently a revolutionary task in the MOT field. By 2022, the author can see the diversity of the MOT problem statement. Oluaffunmilola et al. simultaneously performed target prediction while tracking targets [50]. They used FairMOT [54] to detect bounding boxes, then stacked a prediction network and created a Joint Learning Architecture (JLE). Zhi-hong et al. extracted new features for each frame to obtain global information and accumulated partial features for occlusion handling [51]. They fused these two features to accurately detect pedestrians.Except for [52], no paper has taken measures to retain important bounding boxes so that they are not eliminated during the data association phase. After detection, Hong et al. applied Non-Maskable Suppression (NMS) during the tracking phase to reduce the probability of important bounding boxes being removed [53]. Jian et al. also used NMS to reduce redundant bounding boxes from the detector. They re-detected trajectory localization by comparing features and using IoU to re-identify bounding boxes. The final result is a Joint Re-Detection and Re-Identification Tracker (JDI).
Attention Module
To re-identify occluded targets, attention is required. Attention means that the author only considers the target of interest, eliminating the background, allowing its features to be remembered for a long time, even after occlusion. An overview of the application of attention modules in the MOT field is shown in the following table. In [41], Yao Ye et al. introduced a bar attention module to re-identify pedestrians occluded by the background. This module is essentially a pooling layer that includes max and mean pooling, which can extract features from pedestrians more effectively so that when they are occluded, the model does not forget them and can further re-identify them. Song et al. aimed to use information from target localization in data association and vice versa. To link the two, they used two attention modules, one for the target and the other for distracting attention. They then applied a memory aggregation to create enhanced attention. Tian Yi et al. proposed a spatial attention mechanism [60], which forces the model to focus only on the foreground by implementing a Spatial Transformation Network (STN) in the appearance model.On the other hand, Lei et al. first proposed a Prototype Cross Attention Module (PCAM) to extract relevant features from past frames. They then used a Prototype Cross Attention Network (PCAN) to transmit contrastive features of the foreground and background throughout the frame [61]. Huiyuan et al. proposed a self-attention mechanism to detect vehicles [62]. This article [36] also features a self-attention module applied to dynamic graphs to combine internal and external information of cameras. Jia Xu et al. used cross-attention and self-attention in a lightweight way. As shown in the following figure, you can see the cross-attention head of this architecture. Using the self-attention module to extract robust features reduces background occlusion. The data is then passed to the cross-attention module for instance association.
In [41], Yao Ye et al. introduced a bar attention module to re-identify pedestrians occluded by the background. This module is essentially a pooling layer that includes max and mean pooling, which can extract features from pedestrians more effectively so that when they are occluded, the model does not forget them and can further re-identify them. Song et al. aimed to use information from target localization in data association and vice versa. To link the two, they used two attention modules, one for the target and the other for distracting attention. They then applied a memory aggregation to create enhanced attention. Tian Yi et al. proposed a spatial attention mechanism [60], which forces the model to focus only on the foreground by implementing a Spatial Transformation Network (STN) in the appearance model.On the other hand, Lei et al. first proposed a Prototype Cross Attention Module (PCAM) to extract relevant features from past frames. They then used a Prototype Cross Attention Network (PCAN) to transmit contrastive features of the foreground and background throughout the frame [61]. Huiyuan et al. proposed a self-attention mechanism to detect vehicles [62]. This article [36] also features a self-attention module applied to dynamic graphs to combine internal and external information of cameras. Jia Xu et al. used cross-attention and self-attention in a lightweight way. As shown in the following figure, you can see the cross-attention head of this architecture. Using the self-attention module to extract robust features reduces background occlusion. The data is then passed to the cross-attention module for instance association.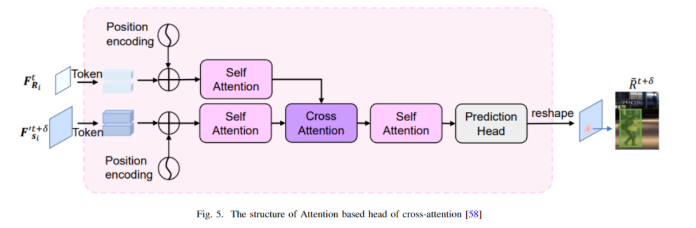
Motion Model
Motion is an inherent attribute of the target. Therefore, this feature can be used in the field of multi-object tracking, whether for detection or association. The motion of the target can be calculated by the difference in position of the target between two frames. Based on this measure, different decisions can be made, as shown in the following table.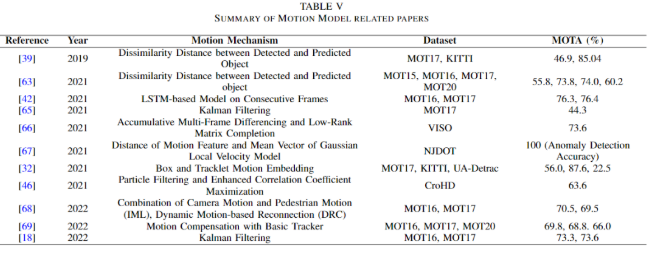 Hasith et al. and Oluaffunmilola et al. used motion to calculate the difference cost in [39] and [63]. Motion is calculated based on the difference between the actual position and the predicted position. To predict the position of occluded targets, Bisheng et al. used an LSTM-based motion model [42]. Wenyuan et al. combined the motion model with Deep Affinity Networks (DAN) [64], optimizing data association by eliminating positions where the target cannot be located [65]. Qian et al. also calculated motion by accumulating Multi-Frame Differences (AMFD) and Low-Rank Matrix Completion (LRMC) to measure distances of consecutive satellite frames, forming a Motion Model Baseline (MMB) to detect and reduce the number of false alarms. Han et al. used motion features to identify foreground targets in the field of vehicle driving [67]. They detected relevant targets by comparing motion features and the GLV model. Gaoang et al. proposed a Local-Global Motion (LGM) tracker that can identify the consistency of motion, thus associating trajectories [32]. In addition, Ramana et al. also used motion models to predict the motion of targets rather than data association, which has three modules: Integrated Motion Localization (IML), Dynamic Reconnect Context (DRC), and 3D Integral Image (3DII) [46]. In 2022, Shoudong et al. proposed a Motion-Aware Tracker (MAT), using motion models for motion prediction and target association. Zhibo et al. proposed a Compensation Tracker (CT) that can gain lost targets with a motion compensation module [69]. Xiaotong et al. used motion models to predict the bounding boxes of targets [18], just as done in [67], but created image patches as discussed in the transformer section.
Hasith et al. and Oluaffunmilola et al. used motion to calculate the difference cost in [39] and [63]. Motion is calculated based on the difference between the actual position and the predicted position. To predict the position of occluded targets, Bisheng et al. used an LSTM-based motion model [42]. Wenyuan et al. combined the motion model with Deep Affinity Networks (DAN) [64], optimizing data association by eliminating positions where the target cannot be located [65]. Qian et al. also calculated motion by accumulating Multi-Frame Differences (AMFD) and Low-Rank Matrix Completion (LRMC) to measure distances of consecutive satellite frames, forming a Motion Model Baseline (MMB) to detect and reduce the number of false alarms. Han et al. used motion features to identify foreground targets in the field of vehicle driving [67]. They detected relevant targets by comparing motion features and the GLV model. Gaoang et al. proposed a Local-Global Motion (LGM) tracker that can identify the consistency of motion, thus associating trajectories [32]. In addition, Ramana et al. also used motion models to predict the motion of targets rather than data association, which has three modules: Integrated Motion Localization (IML), Dynamic Reconnect Context (DRC), and 3D Integral Image (3DII) [46]. In 2022, Shoudong et al. proposed a Motion-Aware Tracker (MAT), using motion models for motion prediction and target association. Zhibo et al. proposed a Compensation Tracker (CT) that can gain lost targets with a motion compensation module [69]. Xiaotong et al. used motion models to predict the bounding boxes of targets [18], just as done in [67], but created image patches as discussed in the transformer section.
Siamese Network
The similarity information between two frames is very helpful for object tracking. Therefore, the Siamese network attempts to learn similarities and differentiate inputs. This network consists of two parallel sub-networks that share the same weights and parameter space. Finally, the parameters between the twin networks are bound on a certain loss function for training to measure the semantic similarity between the twin networks. The following table provides an overview of the application of Siamese networks in MOT tasks.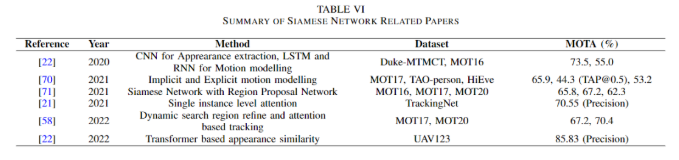 Dai Tao et al. proposed a pyramid network embedded with a lightweight transformer attention layer. The Siamese transformer pyramid network they proposed enhances the target features among the lateral cross-attention pyramid features. Thus, it produces robust target-specific appearance representations [22]. As shown in the figure below:
Dai Tao et al. proposed a pyramid network embedded with a lightweight transformer attention layer. The Siamese transformer pyramid network they proposed enhances the target features among the lateral cross-attention pyramid features. Thus, it produces robust target-specific appearance representations [22]. As shown in the figure below: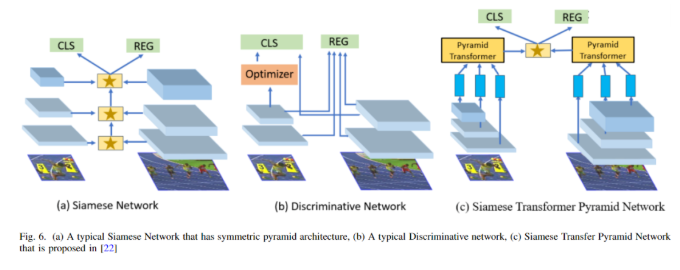 Bing et al. attempted to enhance region-based multi-object tracking networks by combining motion modeling. They embedded the Siamese network tracking framework into a faster R-CNN, achieving fast tracking through lightweight tracking and shared network parameters. Cong et al. proposed a network using Siamese Bidirectional GRU (SiaBiGRU) to post-process trajectories to eliminate trajectory damage. They then established a reconnection network to link these trajectories and create trajectories [31]. In a typical MOT network, there are prediction and detection modules. The prediction module attempts to predict the appearance of the target in the next frame, while the detection module detects the target. The results of these two modules are used for feature matching and updating target trajectories. Xinwen et al. proposed a Siamese RPN (Region Proposal Network) structure as a predictive factor. They also proposed a method for adaptive threshold determination of the data association module [71]. Thus, the overall stability of the Siamese network has improved. In contrast to transformer models, Jia Xu et al. proposed a lightweight tracking head based on attention under the structure of the Siamese network, enhancing the location of foreground targets within the target box [58]. On the other hand, Philippe et al. have integrated their effective transformer layer into the Siamese tracking network, replacing convolutional layers with transformer layers [21].
Bing et al. attempted to enhance region-based multi-object tracking networks by combining motion modeling. They embedded the Siamese network tracking framework into a faster R-CNN, achieving fast tracking through lightweight tracking and shared network parameters. Cong et al. proposed a network using Siamese Bidirectional GRU (SiaBiGRU) to post-process trajectories to eliminate trajectory damage. They then established a reconnection network to link these trajectories and create trajectories [31]. In a typical MOT network, there are prediction and detection modules. The prediction module attempts to predict the appearance of the target in the next frame, while the detection module detects the target. The results of these two modules are used for feature matching and updating target trajectories. Xinwen et al. proposed a Siamese RPN (Region Proposal Network) structure as a predictive factor. They also proposed a method for adaptive threshold determination of the data association module [71]. Thus, the overall stability of the Siamese network has improved. In contrast to transformer models, Jia Xu et al. proposed a lightweight tracking head based on attention under the structure of the Siamese network, enhancing the location of foreground targets within the target box [58]. On the other hand, Philippe et al. have integrated their effective transformer layer into the Siamese tracking network, replacing convolutional layers with transformer layers [21].
Tracklet Association
A set of consecutive frames of the target of interest is called a tracklet. When detecting and tracking targets, different algorithms are first used to identify trajectories. They are then linked together to establish a trajectory. Trajectory association is evidently a challenging task in the MOT problem. Some papers specifically focus on this issue. Different papers have taken different approaches. As shown in the following table. Jin Long et al. proposed Trajectory Plane Matching (TPM) [72], where short trajectories are first created from detected targets, and they are aligned in trajectory planes, where each trajectory is assigned a hyperplane based on its start and end times. This forms large trajectories. This process can also handle non-adjacent and overlapping tracklets. To improve this situation, they also proposed two schemes. Duy et al. first created tracklets using 3D geometric algorithms [73]. They formed trajectories from multiple cameras, and due to this, they optimized global association by formulating spatial and temporal information. In [31], Cong et al. proposed a Position Projection Network (PPN) to achieve trajectory transformation from local environments to global environments. Daniel et al. re-identified occluded targets by assigning newly arriving targets to previously discovered occluded targets based on motion. They then implemented further regression trajectories that have already been discovered using a by-regression approach. Additionally, they expanded their work by extracting temporal directions to improve performance.In [75], a different strategy from the former can be seen. Each trajectory is established as a center vector, creating a Trajectory Center Repository (TMB) that is dynamically updated and cost-calculated. This entire process is called Multi-View Trajectory Contrast Learning (MTCL). Furthermore, they created a learnable view sampling (LVS) that takes each detection as a key point, helping to view trajectories in a global context. They also proposed a Similarity-Guided Feature Fusion (SGFF) method to avoid ambiguous features. et al. have developed a Trajectory Booster (TBooster) [76] to mitigate errors that occur during the association process. TBooster has two components: a splitter and a connector. In the first module, tracklets are split where ID switches occur. Thus, the problem of assigning the same ID to multiple targets can be resolved. In the second module, tracklets of the same target are linked together. This can be completed through the connector.
Jin Long et al. proposed Trajectory Plane Matching (TPM) [72], where short trajectories are first created from detected targets, and they are aligned in trajectory planes, where each trajectory is assigned a hyperplane based on its start and end times. This forms large trajectories. This process can also handle non-adjacent and overlapping tracklets. To improve this situation, they also proposed two schemes. Duy et al. first created tracklets using 3D geometric algorithms [73]. They formed trajectories from multiple cameras, and due to this, they optimized global association by formulating spatial and temporal information. In [31], Cong et al. proposed a Position Projection Network (PPN) to achieve trajectory transformation from local environments to global environments. Daniel et al. re-identified occluded targets by assigning newly arriving targets to previously discovered occluded targets based on motion. They then implemented further regression trajectories that have already been discovered using a by-regression approach. Additionally, they expanded their work by extracting temporal directions to improve performance.In [75], a different strategy from the former can be seen. Each trajectory is established as a center vector, creating a Trajectory Center Repository (TMB) that is dynamically updated and cost-calculated. This entire process is called Multi-View Trajectory Contrast Learning (MTCL). Furthermore, they created a learnable view sampling (LVS) that takes each detection as a key point, helping to view trajectories in a global context. They also proposed a Similarity-Guided Feature Fusion (SGFF) method to avoid ambiguous features. et al. have developed a Trajectory Booster (TBooster) [76] to mitigate errors that occur during the association process. TBooster has two components: a splitter and a connector. In the first module, tracklets are split where ID switches occur. Thus, the problem of assigning the same ID to multiple targets can be resolved. In the second module, tracklets of the same target are linked together. This can be completed through the connector.
MOT Benchmarks
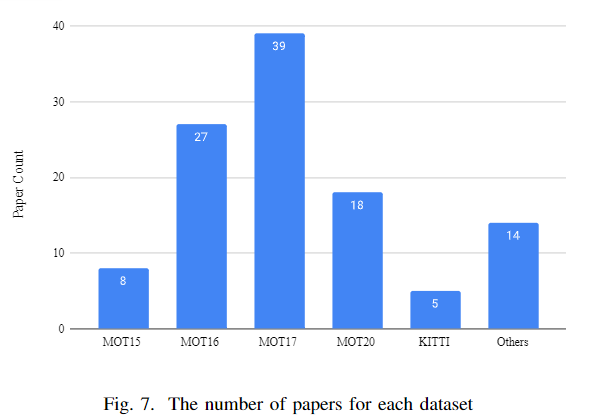
Typical MOT datasets consist of video sequences. In these sequences, each target is identified by a unique ID until it no longer appears. Once a new target enters a frame, it receives a new unique identifier. There are many benchmarks for MOT. Among them, the MOT Challenge benchmark has multiple versions. Since 2015, they have released a new benchmark with more variations almost every year. There are also some popular benchmarks, such as PETS, KITTI, STEPS, and DanceTrack. So far, the MOT Challenge has 17 object tracking datasets, including MOT15 [81], MOT16 [82], MOT20, [6] and others. The MOT15 benchmark contains datasets from Venice, KITTI, ADL-Rundle, eTH-Pescross, eTH-Sunnyday, PET, and TUd-cross. This benchmark was filmed in an unconstrained environment, with static and moving cameras. MOT16 and MOT17 are essentially updated benchmarks from MOT15, with higher ground truth accuracy and strictly followed protocols. MOT20 is a pedestrian detection challenge. This benchmark has 8 challenging video sequences (4 training, 4 testing) in an unconstrained environment [6]. Besides object tracking, the MOTS dataset also has segmentation tasks [40]. Generally, tracking datasets have a bounding box, and the targets within the box have a unique identifier.The TAO [83] dataset has a massive scale due to tracking every target in a frame. There is a dataset called Head Tracking 21. The task of this benchmark is to track each person’s head. The STEP dataset performs segmentation and tracking at each pixel. There are also some other datasets. The following figure shows the frequency of datasets used in the papers reviewed by the author. From the chart, it can be seen that the MOT17 dataset is used more frequently than other datasets.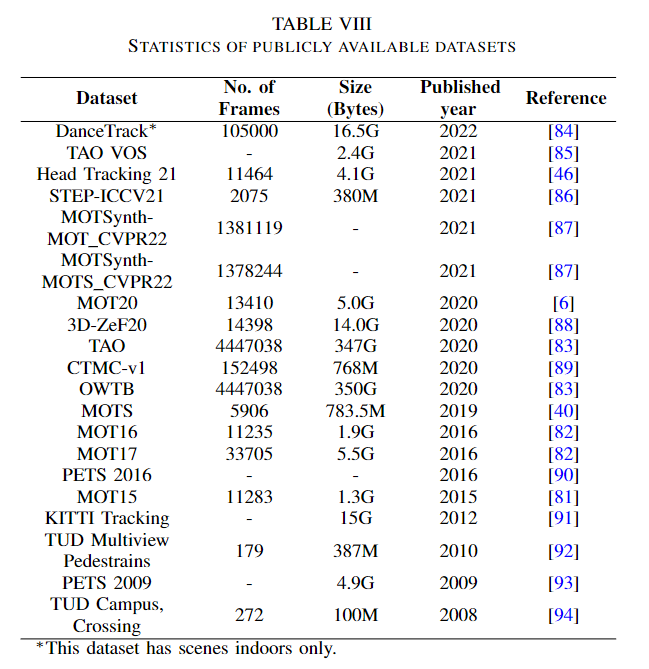
MOT Metrics
MOTP
Multi-Object Tracking Precision (MOTP). Regardless of whether the tracker can identify the shape of the target and maintain consistent trajectories, it is scored based on the accuracy of the tracker when looking for the target’s position. Since MOTP can only provide localization accuracy, it is often combined with MOTA (Multiple Object Tracking Accuracy), as MOTA cannot explain localization errors alone. Localization is one of the outputs of the MOT task. It lets everyone know the position of the target in this frame. Alone, it cannot provide a complete performance of the tracker.
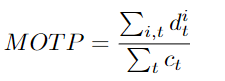
Dit: At time t, the distance between the actual target and its respective hypothesis within a single frame, for each target Oi in the set, the tracker assigns a hypothesis hi. Ct: The number of matches between targets and hypotheses at time t.
MOTA
Multi-Object Tracking Accuracy. This metric measures the ability of the tracker to detect targets and predict trajectories without considering accuracy. This metric considers three types of errors:
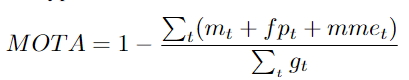
Mt: The number of losses at time t; fpt: The number of false detections; mmet: The number of ID switches; gt: The number of real targets appearing at time t.MOTA overemphasizes the effect of precise detection. It focuses on the matching between predicted and ground truth at the detection level and does not consider association. When considering MOTA without ID switches, the metric tends to be more influenced by poor precision. The above limitations may lead researchers to adjust their trackers to make them more precise and accurate at the detection level while neglecting other important aspects of tracking. MOTA can only consider short-term associations. It can only evaluate the effectiveness of the algorithm performing first-order associations and cannot assess the effectiveness of the algorithm in associations across the entire trajectory. Furthermore, it does not consider association accuracy/ID switching. In fact, if a tracker can correct any association errors, it will penalize it instead of rewarding it. The highest score for MOTA is 1, but there is no fixed minimum value, which can lead to negative MOTA scores.
IDF1
ID metric. It attempts to map the predicted trajectory to the actual trajectory, contrasting with metrics like MOTA that perform bijective mappings at the detection level. It is designed to measure “identification,” different from detection and association, it relates to trajectories.

IDTP: Represents ID true positives, the predicted target trajectory matches the ground truth target trajectory. IDFN: ID false negatives. Any unrecognized ground truth value whose trajectory has not been matched. IDFP: ID false positives. Any erroneous prediction.Due to the high dependency of MOTA on detection accuracy, some prefer IDF1, as this metric focuses more on associations. However, IDF1 also has some drawbacks. In IDF1, the best unique bijection does not lead to the best alignment between predicted and actual trajectories. The final result will leave room for better matching. Even if the detection is correct, the IDF1 score may decrease. If there are many unmatched trajectories, the score will also decrease. This encourages researchers to increase the total number of uniques rather than focus on making reasonable detections and associations.
Track-mAP
This metric matches GroundTruth trajectories and predicted trajectories. When the trajectory similarity score Str is greater than or equal to the threshold αtr, matches are made between trajectories. Additionally, the predicted trajectory must have the highest confidence score.
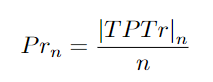
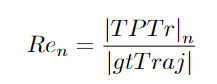
n: The total number of predicted trajectories. Predicted trajectories are sorted in descending order by confidence score. Prn: Measures the accuracy of the tracker. TPTr: True trajectories. Any matched predicted trajectory. |TPTr|n: The number of true trajectories among n predicted trajectories. Ren: Measures Recall. |gtTraj |: The ground truth of target trajectories, using precision and recall equations for further calculations to obtain the final Track−mAP score.
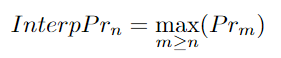
The author first interpolates the precision values to obtain InterpPr for each n value. The author then plots a graph of InterpPr against Ren for each n value. The author now has a precision-recall curve. The integral of this curve will give the Track-mAP score. Track-mAP also has some drawbacks. The tracking results of track-mAP are difficult to display intuitively. It has multiple outputs for a single track. The effect of low confidence score trajectories on the final score is ambiguous. There is a method to “black out” this metric. Researchers can achieve a higher score by creating several predictions with lower confidence scores. This will increase the chances of obtaining suitable matches, thus increasing the score. However, this is not a good tracking metric. Tracking mAP cannot indicate whether the tracker has better detection and association.
HOTA
Higher Order Tracking Accuracy. The original paper [96] describes HOTA as: “HOTA measures the degree of alignment of matched detections and tracks, averaging over overall matched detections while penalizing unmatched detections.” HOTA should be a single score that encompasses all elements of tracking evaluation. It should also be broken down into sub-metrics. HOTA compensates for the shortcomings of other commonly used metrics. While metrics like MOTA ignore associations and are heavily dependent on detection (MOTA) or vice versa (IDF1), the development of new concepts like TPA, FPA, and FNA allows associations to be measured similarly to how TP, FNs, and FP are used to measure detection.
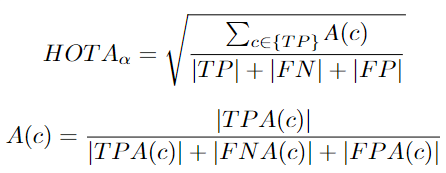
A(c): Measures the degree of similarity between predicted trajectories and ground truth trajectories. TP: True positives, matching ground truth detections with predicted detections under the condition S ≥ α. S is the localization similarity, α is the threshold. FN: False negatives. Missed ground truth detections. FP: False positives. A prediction that does not match any ground truth. TPA: True positive associations. The set of true positives that have the same ground truth ID and the same predicted ID as a given TPC.
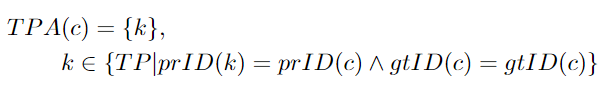
FNA: A set of ground truth detection targets with the same ground truth ID as a given TPC. However, these detection targets have been assigned a different predicted ID or none at all.
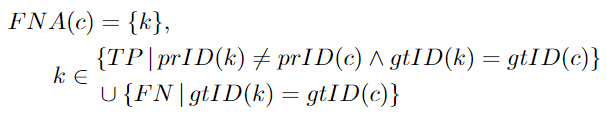
FPA: A set of predicted detections with the same predicted ID as a given TPc. However, these detection targets have been assigned a different ground truth ID or none at all.
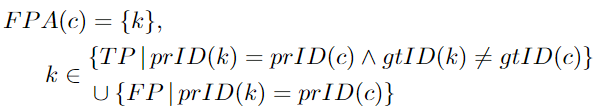
HOTAα is the calculation of HOTA for specific values of α. Further calculations are needed to obtain the final HOTA score. The author found the HOTA corresponding to different values of α, ranging from 0 to 1, and then averaged them.
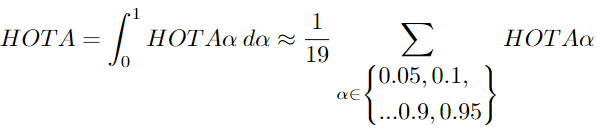
The author is able to break down HOTA into several sub-metrics. This is useful because different elements of tracking evaluation can be adopted and used for comparison. It can provide a better understanding of the errors being produced by the tracker. Common errors in tracking can be classified into five types: false negatives, false positives, fragmentation, merging, and bias. These can be measured respectively through detection recall, detection precision, association recall, association precision, and localization.
LocA
Localization Accuracy [96].
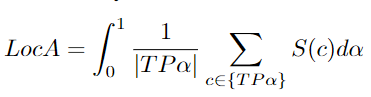
S(c): The spatial similarity score between predicted detections and ground truth. This sub-metric deals with the error type of bias or localization error. When predicted detections and ground truth are inconsistent, localization errors occur. This is similar to MOTP but differs in that it includes several localization thresholds. Common metrics like MOTA and IDF1 do not take localization into account.
AssA: Association Accuracy Score
According to the MOT benchmark: “The average Jaccard index of all matched detections exceeds the localization threshold” [96]. Association is part of the MOT task results, informing whether targets in different frames belong to the same or different targets. These targets share the same ID and are part of the same trajectory. Association accuracy provides the average alignment degree between matched trajectories. It primarily focuses on association errors. This occurs when a single target in ground truth is given two different predictions, or a single prediction is given two different ground truth targets.
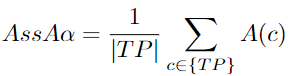
DetA: Detection Accuracy
According to the MOT benchmark: “The average detection Jaccard index exceeds the localization threshold” [96]. Detection is another output of the MOT task. It is simply the target within the frame. Detection accuracy is part of correct detections. When ground truth is overlooked or there are false detections, detection errors occur.
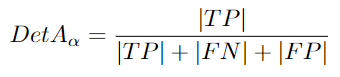
DetRe: Detection Recall
It provides a calculation equation for a localization threshold. It is necessary to average all localization thresholds [96]:
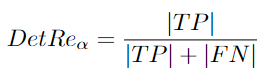
Detection recall errors are false negatives. They occur when the tracker misses a real target, and detection accuracy can be divided into detection recall and detection precision.
DetPr:
It provides a calculation equation for the localization threshold, needing to average all localization thresholds [96]:
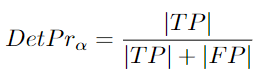
As mentioned earlier, detection precision is part of detection accuracy. Detection precision errors are false positives (false detections). They occur when the tracker makes predictions that do not exist in ground truth.
AssRe: Association Recall
It is necessary to calculate the formula below, then average the results of all matched detections. Finally, the average result should exceed the localization threshold [96]:
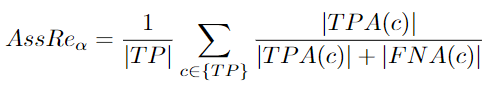
Association recall errors occur when the tracker assigns different predicted trajectories to the same ground truth trajectory. Association accuracy can be divided into association recall and association precision.
AssPr: Association Precision
The author needs to calculate the equation below, then average all matched detections. Finally, the average result should exceed the localization threshold [96]:
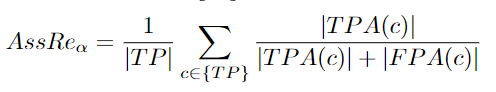
Association precision is part of association accuracy. Association errors occur when two different ground truth trajectories have the same predicted ID.
MOTSA: Multi Object Tracking and Segmentation Accuracy
This is a variant of the MOTA metric, thus it can also evaluate the performance of trackers in segmentation tasks.
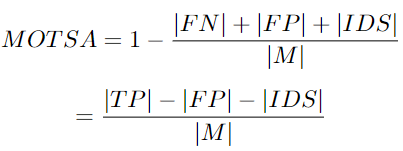
Here M is a set of N non-empty ground truth masks. Each mask is assigned a ground truth tracking ID. TP is a set of true positives. When a hypothesis mask maps to a ground truth mask, a true positive occurs. FP is a false positive, with no ground truth, and FN is a set of false negatives with ground truth but no corresponding detection results. IDS and ID switches are ground truth masks belonging to the same track but assigned different IDs. The disadvantages of the MOTSA algorithm include: making detection more important than association and being influenced by matching threshold selection.
AMOTA: Average Multiple Object Tracking Precision
This is calculated by averaging the MOTA values of all recalls:
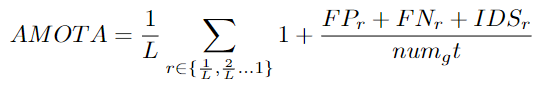
numg is the number of ground truth targets across all frames. For a specific recall value r, the number of FPs, FNs, and the number of ID switches are denoted as FPr, FNr, and IDSr. The number of recall values is denoted as L.
Applications
MOT has countless applications. Many works involve tracking various targets, including pedestrians, animals, fish, vehicles, athletes, etc. In fact, the field of multi-object tracking cannot be limited to just a few areas. However, to gain an idea from the application perspective, the author will cover papers based on specific applications.
Autonomous Driving
Autonomous driving can be said to be the most common task in multi-object tracking. It is a hot topic in the field of artificial intelligence in recent years. Gao et al. proposed a dual attention network for autonomous driving, integrating two attention modules [97]. Mr. Fu et al. first utilized the self-attention mechanism to detect vehicles, and then associated them using multidimensional information. They also addressed congestion issues by re-tracking missing vehicles [62]. Pang et al. combined vehicle detection with a Random Finite Set (RFS)-based multi-measurement model filter (RFS-M3) for 3D MOT [98]. Luo et al. also applied 3D MOT technology, proposing a simulation tracking technology that can detect and associate aircraft through point clouds captured by LiDAR. Mackenzie et al. conducted two studies: one on autonomous vehicles and the other on motion. They studied the overall performance of multi-object avoidance (MOA), a tool for measuring action attention in autonomous driving. Zou et al. proposed a lightweight framework for full-stack perception of 2D traffic scenes captured by roadside cameras. Cho et al. identified and tracked these vehicles using traffic monitoring cameras with YOLOv4 and DeepSORT after projecting images from local to global coordinate systems [101].
Others
Pedestrian tracking: is one of the most common tasks in multi-object tracking systems. Since videos from street cameras are easily captured, much work has been done on human or pedestrian tracking.Vehicle monitoring: Like autonomous driving, it is also a very important task. MOT technology can be applied to monitor vehicle activities.Athlete tracking: In the era of AI, rigorous analysis of any athlete in motion is one of the most important tactics. Therefore, MOT is used in many ways to track athletes.Wildlife tracking: A potential application case for MOT is wildlife tracking. It can help wildlife researchers avoid expensive sensors that may not be reliable in certain cases. MOT also plays a crucial role in tracking underwater creatures like fish. In [118], Li et al. proposed CMFTNet, which achieves feature extraction and association by applying joint detection and embedding. In complex backgrounds, the deformable convolution method further enhances the feature sharpening ability, achieving precise tracking of fish through weighted balanced loss.In the field of visual surveillance, Ahmed et al. proposed a collaborative robot framework based on SSD and YOLO for detection and a combination of tracking algorithms [120].MOT can also be seen implemented in agriculture. To track tomato planting, Ge et al. used a YOLO-based shufflenetv2 as the baseline, CBAM as the attention mechanism, BiFPN as the multi-scale fusion structure, and DeepSORT as tracking [125]. Tan et al. also used YOLOv4 as a detector for cotton seedlings and a flow-based tracking method to track the seedlings [49].MOT can also be applied to various real-life applications such as security monitoring, social distancing monitoring, radar tracking, activity recognition, smart elderly care, crime tracking, person re-identification, behavior analysis, etc.
Future Directions
Since MOT has been a research hotspot for many years, considerable efforts have been made on it. However, there is still significant room for development in this field. Here, the author wants to point out some potential directions for MOT:
- Multi-object tracking under multiple cameras is somewhat challenging. The main challenge is how to fuse these scenes. However, if the scenes of non-overlapping cameras are fused together and projected into a virtual world, then MOT can continuously track targets over a longer area. Similar efforts can be seen in [31]. A relatively new dataset for multi-camera multi-person tracking is also available [126]. Xindi et al. proposed a real-time online tracking system for multi-target multi-camera tracking [127].
- Class-based tracking systems can be combined with multi-object tracking. MOT algorithms attempt to track almost all moving targets in a frame. If class-based tracking can be performed, it will be better applied in real-world scenarios. For example, a bird tracking MOT system is very useful at airports, as some artificial preventive mechanisms are currently used to prevent birds from colliding with aircraft on runways. It can be fully automated using a class-based MOT system. Class-based tracking helps monitor effectively as it aids in tracking specific types of targets.
- MOT has extensive applications in two-dimensional scenes. While this is somewhat challenging, utilizing MOT to analyze 3D videos would be a great research topic. Three-dimensional tracking can provide more accurate tracking and occlusion handling. As depth information is preserved in three-dimensional scenes, it helps overcome a major challenge, the occlusion issue in MOT.
- So far, most transformers have been used as black boxes. However, transformers can be more specifically used to address different MOT tasks. Some methods are entirely detection-based and further regression is employed to predict the bounding box for the next frame [128]. In this case, DETR [25] can be used for detection as it is very efficient in detecting targets.
- In any application, lightweight architectures are very important for practical applications. Because lightweight architectures are resource-efficient, and in practical scenarios, resources are limited. In MOT, if a model is to be deployed on IoT embedded devices, lightweight architectures are also crucial. Additionally, lightweight architectures play a very important role in real-time tracking. Therefore, if more fps can be achieved without compromising accuracy, it can be implemented in practical applications, where lightweight architectures are very necessary.
- In real life, online multi-object tracking is the only feasible solution. Therefore, inference time plays a crucial role. The author has observed a trend of gaining more accuracy from researchers in recent years. However, if inference times exceeding 30 fps can be achieved, then MOT can be used for real-time tracking. Since real-time tracking is key to monitoring, it is one of the main directions for future MOT research.
- In recent years, the application of quantum computing in computer vision has shown a trend. Quantum computing can also be used for MOT. Zaech et al. published the first paper on the use of adiabatic quantum computing (AQC) for MOT with the help of the Ising model [129]. They expect AQC to accelerate the NP-hard assignment problem in future association processes. As quantum computing has great potential in the near future, this may be a very promising research area.
Conclusion
This article attempts to summarize and review the latest trends in computer vision in MOT. The author tries to analyze its limitations and significant challenges. At the same time, the author finds that besides some major challenges such as occlusion and ID switching, there are also some minor challenges. This research includes a brief theory related to each method, attempting to equally focus on each method. The author also added some popular benchmark datasets along with their insights.Based on recent trends in MOT, some possible future directions for MOT are envisioned. The author finds that researchers have recently focused more on transformer-based structures due to the contextual information storage capability of transformers. Since lightweight architectures of transformers are still resource-intensive, developing new modules is also necessary. Finally, it is hoped that this research can supplement researchers in the field of multi-object tracking and open a new chapter in multi-object tracking research.Follow the WeChat public account“Data派THU”, reply in the background with“20221020” to obtain a review of single-object, multi-object, and learning-based methods!Editor: Huang Jiyan