Click on "Xiaobai Learns Vision" above, select "Star" or "Top"
Heavyweight content delivered first
Editor’s Recommendation
Recently, I saw an interesting article discussing the question, ‘Why hasn’t batch attention been done?’ I would like to share it with everyone, hoping it will be helpful.
Reprinted from丨NewBeeNLP
© Author | Hou Zhi
Institution | University of Sydney

Current deep neural networks, despite achieving great success, still face various challenges from data scarcity, such as data imbalance, zero-shot distribution, domain adaptation, etc. Various methods have been proposed to address these issues by leveraging the relationships between samples. However, these methods do not exploit the inherent network structure to model relationships. Inspired by this, we propose a simple, effective, and plug-and-play Transformer module, Batch TransFormer (BatchFormer), that allows the network to learn sample relationships from training batches (min-batch). Specifically, BatchFormer is applied to the batch dimension of each training batch data to implicitly explore sample relationships. BatchFormer enables samples within each batch to mutually enhance learning. For instance, in long-tail recognition, it utilizes frequent category data to promote the learning of samples from rare categories. Furthermore, since the Transformer is referenced in the batch dimension during training, the data distribution during training and testing is no longer consistent. Therefore, we propose a shared classifier strategy to eliminate the distribution bias between training and testing, achieving batch-invariant learning, allowing us to remove BatchFormer during testing without adding any computational burden. No additional strategies are needed; BatchFormer has demonstrated stable improvements across more than 10 datasets, including long-tail distribution, compositional zero-shot learning, domain generalization, domain adaptation, and contrastive learning. Last but not least, based on DETR, we further extend BatchFormer to pixel-level tasks, including object detection, panoptic segmentation, and image classification.The improved version of BatchFormer can be seamlessly integrated into DETR, Deformable DETR, Conditional DETR, SMCA, and DeiT.

Paper Title:
BatchFormer: Learning to Explore Sample Relationships for Robust Representation Learning
Paper Source:
CVPR 2022
Paper Link:
https://arxiv.org/pdf/2203.01522.pdf (CVPR 2022)
https://arxiv.org/pdf/2204.01254.pdf (V2)
Code Link (V1 & V2):https://github.com/zhihou7/BatchFormer

Introduction
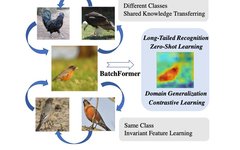
Although deep learning has achieved great success, it heavily relies on large amounts of data. This dependency on extensive training data limits the practical application of deep models. Therefore, how to improve the generalization ability of deep models in data-scarce scenarios has received widespread attention, such as long-tail learning, few-shot learning, zero-shot learning, and domain generalization. However, there is still a lack of a simple, unified framework to explore sample relationships to address various sample scarcity issues. An intuitive example can be seen in Figure 1, where we can use the similarity and shared parts of different samples to enhance the network’s generalization.
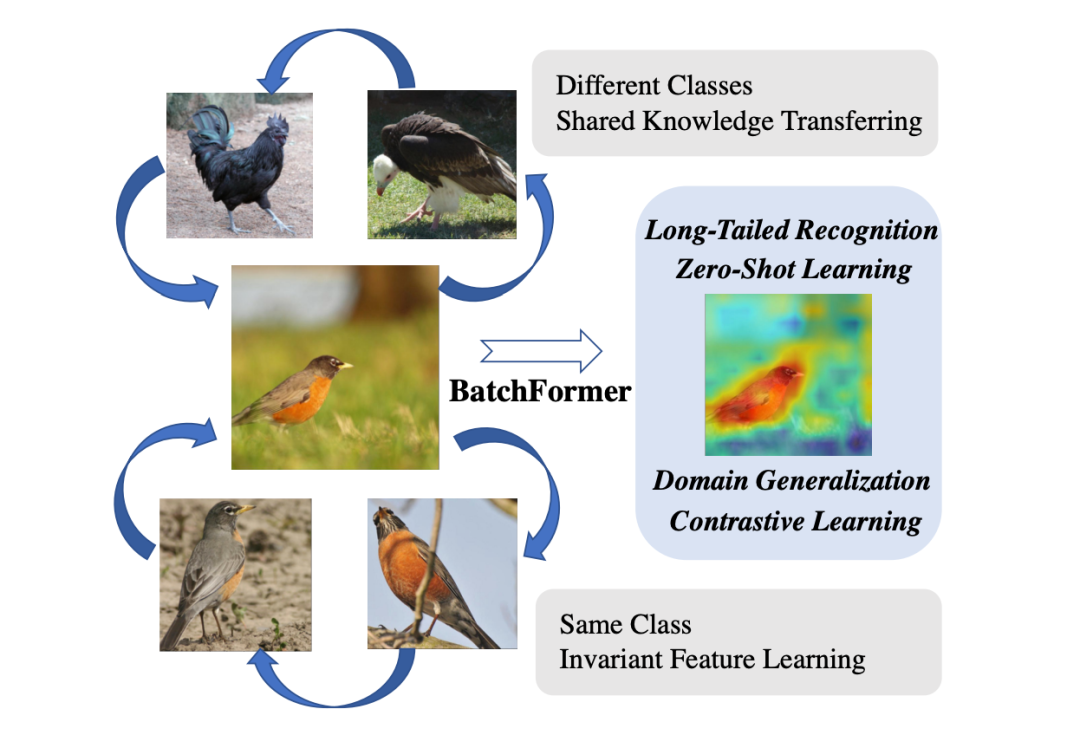
▲ Figure 1: Example of sample relationships. Birds and chickens have shape similarities and share the characteristic of having two legs.
Although sample relationships have not been explicitly articulated, recent works have explored sample relationships inherently through constraints or knowledge transfer. Some common examples include mixup [3], copy-paste [4], crossgrad [5], and compositional learning [6]. These methods inherently utilize the existing similarities and shared parts between samples to enhance the data-constrained model. Another approach is knowledge transfer, such as 1) between frequent and rare categories [7], 2) from seen to unseen categories [8], 3) known domains and unknown domains [9]. However, these methods explore relationships from the input or output of the network without designing the internal structure of the network to learn sample relationships, let alone collaborative learning in the batch dimension. In this article, we introduce a network module that operates on the batch dimension to explore sample relationships. However, the inconsistency between training and testing (during testing, there may not always be a sample) makes it difficult for the network to learn sample relationships in the batch dimension. Because we often encounter data without a batch during testing. A classic example is Batch Normalization. Batch Normalization always retains the mean and variance computed from mini-batch statistics to normalize test samples. Another approach is to use a memory bank of features to retain the centers of categories to help discriminate rare and zero-shot categories. Unlike the above methods, we introduce a new, simple, and effective module to explore the benefits of structural advantages in sample relationships for representation learning. Specifically, we attempt to introduce the Transformer structure along the batch dimension to model sample relationships. Here, we are primarily inspired by graph structures; without positional embedding, the Transformer can also be viewed as a fully connected graph network. We call this module Batch Transformer or BatchFormer. In implementation, we insert BatchFormer between the classifier and feature extractor. Moreover, to reduce the bias between testing and training, unlike Batch Normalization and Memory Feature Bank, we introduce a new strategy: shared classifiers. We introduce shared classifiers before and after BatchFormer. Compared to statistical mean-variance and Feature back, the shared strategy allows us to avoid adding any computational or memory burden during testing. Although adding a shared classifier can effectively improve the classification problems of data scarcity, this is not very applicable for pixel-level tasks. Therefore, we further generalize BatchFormer to general tasks such as object detection and segmentation. We apply BatchFormer to general Transformer structures like DETR and DeiT, inserting it between two layers of spatial Transformers while improving the shared classifier to a dual-stream structure to ensure batch invariance during training and testing. We call this method BatchFormerV2. A simple comparison of Channel Attention [10], Visual Transformer [11] and BatchFormer can be seen in Figure 2. We generalize the Attention structure from channel and spatial dimensions to the batch dimension, demonstrating a new possible model structure.
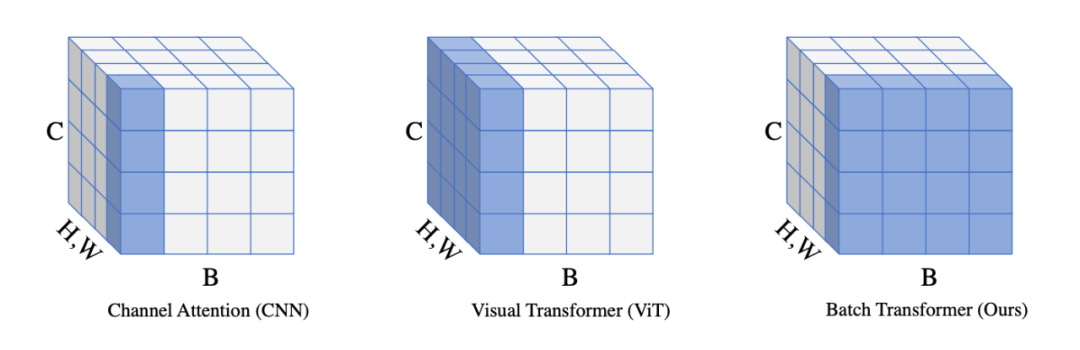
▲ Figure 2: Channel Attention does attention in the channel, Visual Transformer does attention in the spatial dimension, while our BatchFormer does attention in the batch dimension.
In summary, we introduce a simple and effective Transformer module for data scarcity, named BatchFormer. We demonstrate the effectiveness of the method across more than 10 data-scarce datasets and 5 tasks. Furthermore, we propose a BatchFormerV2 version that generalizes BatchFormer to general object detection and segmentation tasks, significantly improving the effectiveness of DETR, Deformable-DETR, Conditional DETR, and SMCA.

Methods
2.1 BatchFormer
BatchFormer is a plug-and-play module that promotes representation learning by exploring sample relationships. As shown in Figure 3, we insert the Transformer module behind the feature extractor. Specifically, our Transformer operates along the batch dimension, meaning we treat the entire batch as a sequence. Here, we remove the positional embedding of the Transformer to achieve position-invariant learning. At the same time, we add a classifier before and after the Transformer. Note that these two classifiers are shared, and through this shared classifier, we can maintain batch invariance during training and testing.
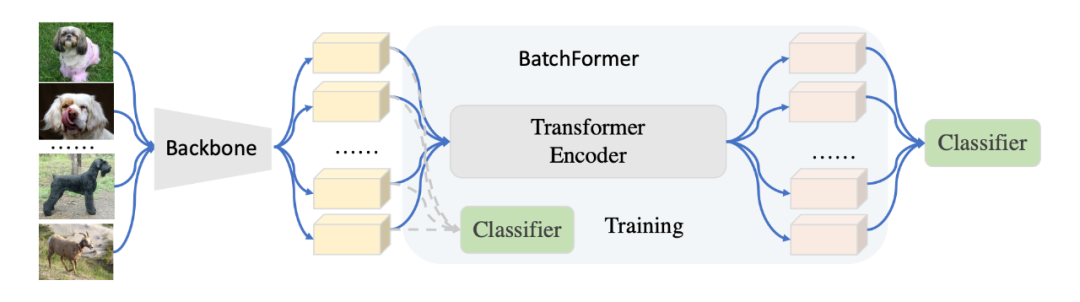
▲ Figure 3: Module schematic diagram, where we insert a Transformer Encoder module before the classifier. This module operates on the batch dimension rather than the spatial dimension. Meanwhile, shared classifiers are present before and after the Transformer.
BatchFormer can be implemented with just a few lines of code, as shown below:

2.2 BatchFormerV2
We generalize BatchFormer into a more universal module to promote general computer vision tasks, such as object detection and segmentation, image classification. Specifically, we insert BatchFormer between two layers of the Visual Transformer, performing Batch Transformer operations on each spatial pixel point. At the same time, we share BatchFormer across each spatial position, as shown in the figure below.
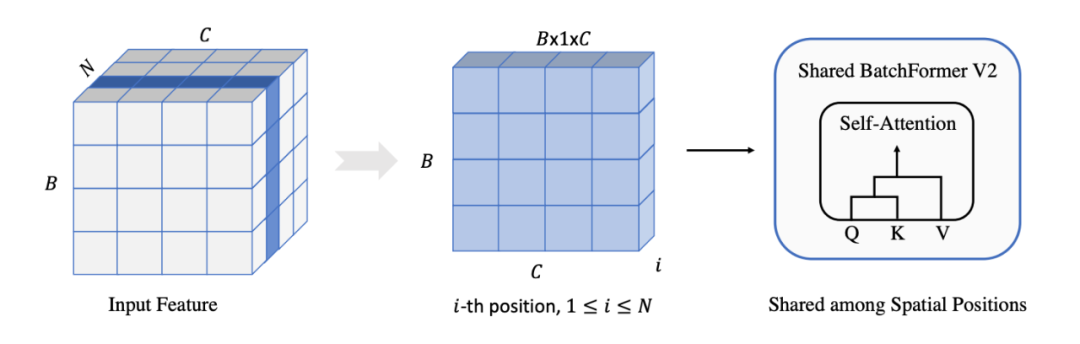
▲ Figure 4: Spatial dimension sharing diagram of BatchFormerV2 At the same time, we introduce a new dual-branch model, starting from BatchFormer, where each batch is duplicated, allowing one batch of data to pass through the original network module while the other batch of data goes through the BatchFormer branch. Aside from the BatchFormerV2 module, all other module parameters are shared across both branches. The purpose here is the same as the shared classifier: to enable the model to learn a batch-invariant feature. The model framework is as follows:
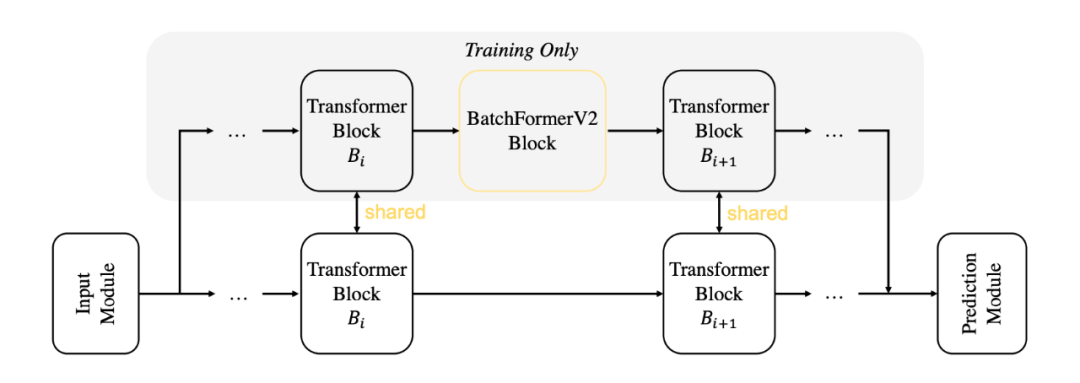
▲ Figure 5: BatchFormerV2 dual-branch framework diagram. The BatchFormerV2 branch adds the BatchFormer module, while the original branch remains unchanged. The data input to both branches is the same.
BatchFormerV2 can also be implemented with just a few lines of code as shown below:

2.3 Gradient Analysis
From the perspective of model optimization, the BatchFormer structure changes the direction of gradient propagation, allowing the features of any sample to contribute to the loss calculation of all other samples. Therefore, the gradient computed from any loss will be backpropagated to the gradients computed based on all other samples. From the perspective of sample enhancement, BatchFormer can be seen as implicitly increasing data. Each sample feature can be viewed as a virtual feature of other samples [3]. Thus, BatchFormer greatly enhances the samples, effectively addressing data scarcity issues.
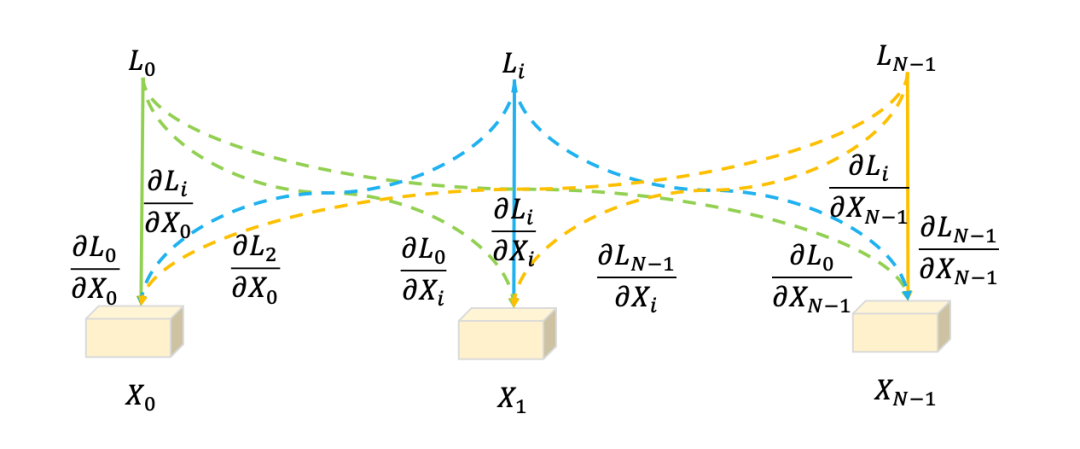
▲ Figure 6: Gradient backpropagation analysis diagram of BatchFormer

Experimental Results
Here we mainly showcase our core experimental results, such as object detection, panoptic segmentation, long-tail recognition, contrastive learning, domain generalization, etc. For more experimental tasks and elimination analyses, please refer to our paper and appendix.
3.1 Object Detection

We found that BatchFormer can be seamlessly integrated into DETR and various methods derived from DETR, achieving consistent improvements of over one point.
3.2 Panoptic Segmentation

We improved DETR by 1.7% in panoptic segmentation. We noted that BatchFormerV2 primarily enhanced the categories of stuff. Our visualization experiments also found that BatchFormerV2 could pay more attention to objects.
3.3 Long-tail Distribution
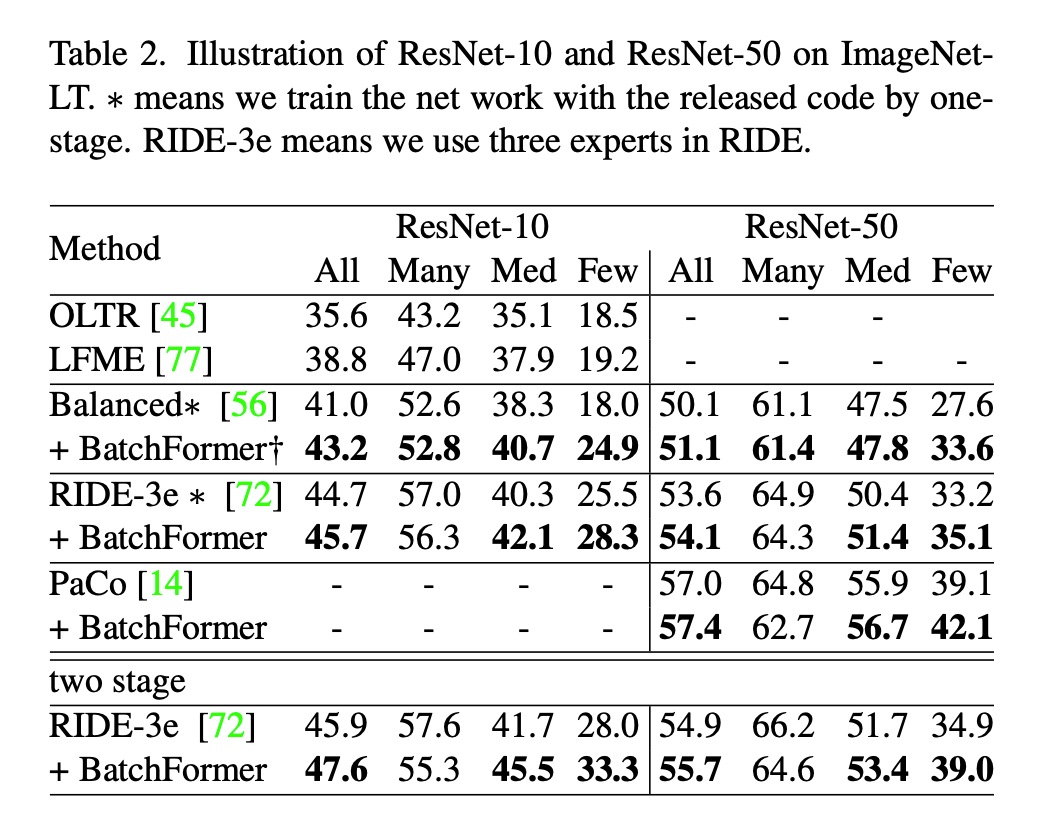
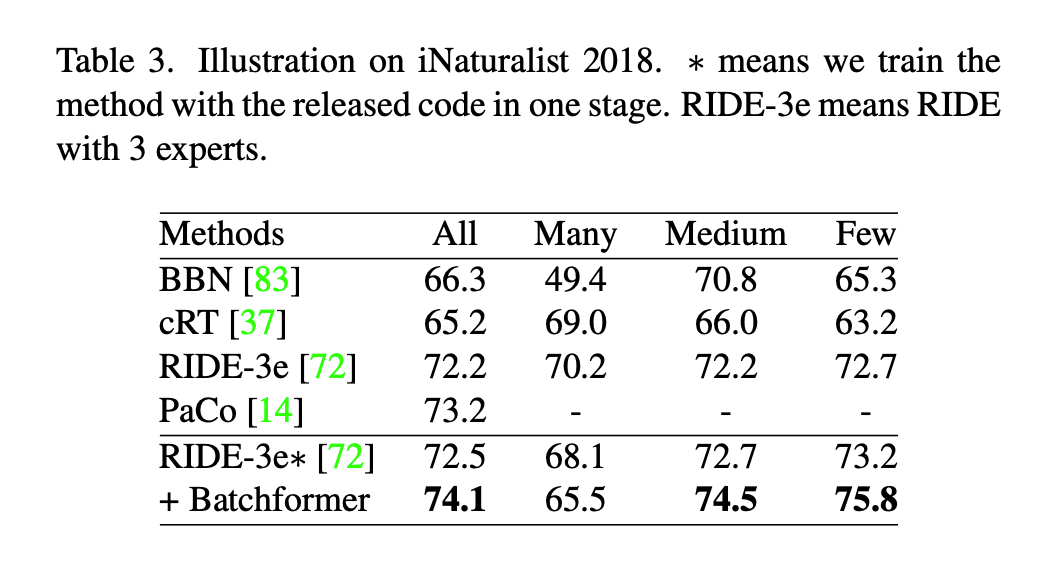
From the experimental results, BatchFormer primarily enhances the few-shot categories. In long-tail distribution, we believe BatchFormer balances the data.
3.4 Self-supervised Learning

BatchFormer consistently improves MoCo-V2 and V3.
3.5 Compositional Zero-shot Learning
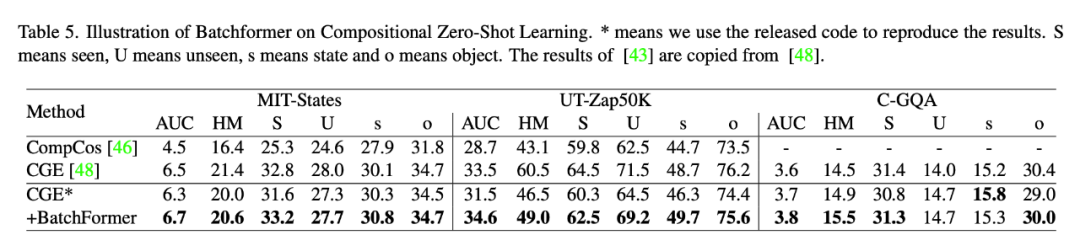
3.6 Domain Generalization

3.7 Image Classification
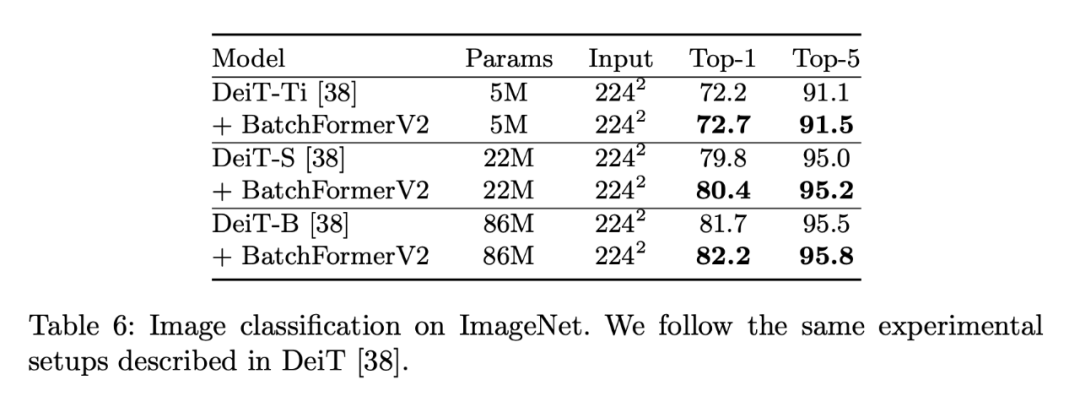
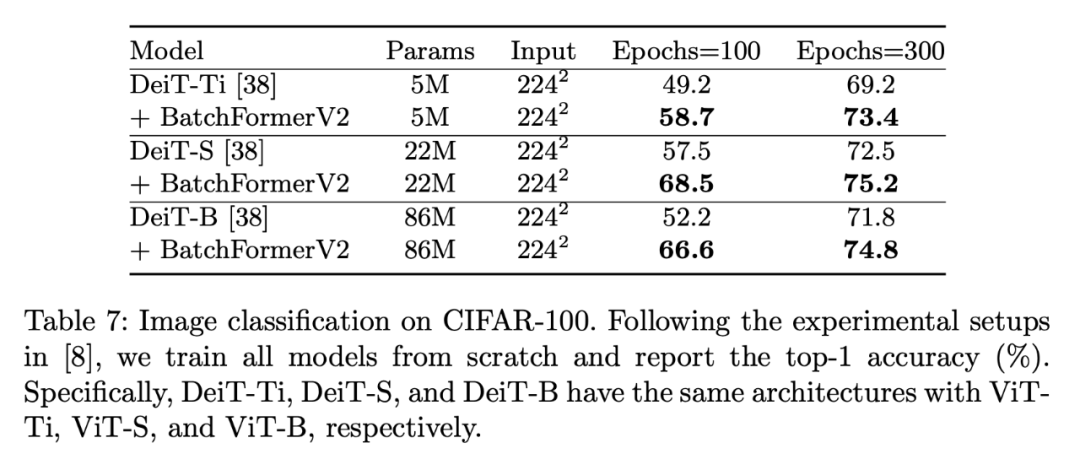
3.8 Ablation Experiments
Batch Size
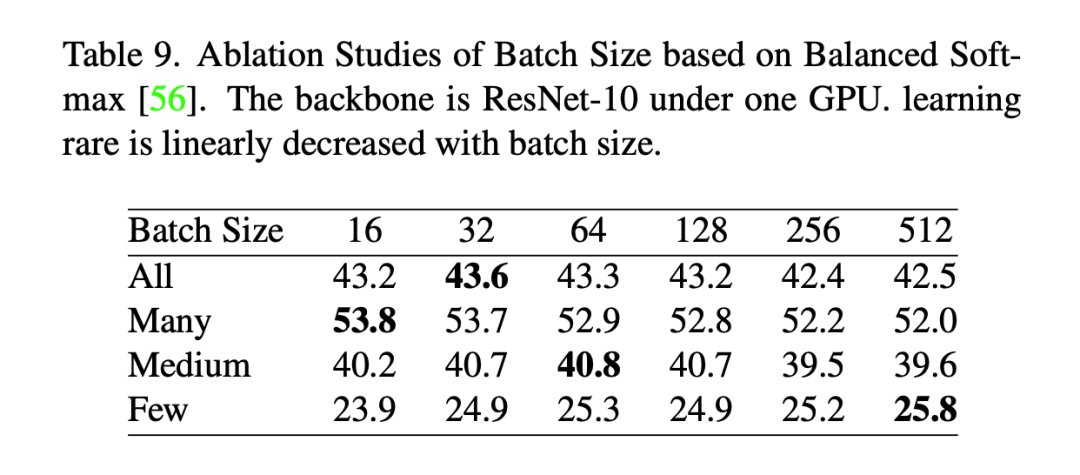
We conducted ablation experiments based on the long-tail recognition dataset (ImageNet-LT). In the experiments, we found that the batch size has a minimal impact on model performance.
3.9 Gradient Analysis
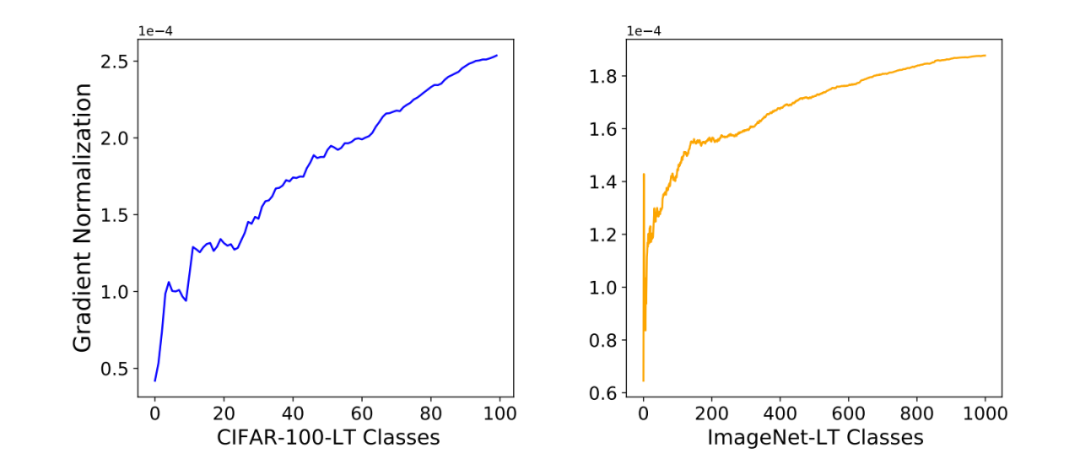
We extracted the mean gradients of each category in the training samples in descending order of instance frequency. We found that the gradients of rare categories are significantly larger for other samples. This experiment indicates that BatchFormer improves the model’s learning of imbalanced data through gradient propagation.

Visualization Analysis
4.1 Grad-CAM Visualization

We visualized the feature map based on Grad-CAM. The second row is our baseline, and the third row is the result after adding the Transformer module. We found that in rare samples of long-tail classification, when the scene is simple, the model pays attention to more detailed parts of the object. When the scene is complex, the model learns to ignore noisy pixels and focus on specific objects.
4.2 Panoptic Segmentation

The second row is our baseline (DETR), and the third row is the result of DETR plus our proposed method. We noted that BatchFormerV2 significantly improves the details of object segmentation. For example, in the image above, the legs of the table, the wheels of the airplane, and the edges of the bathtub. The last image shows that BatchFormerV2 can segment small objects, such as grass.

Conclusion and Outlook
In this article, we introduce a simple and effective plug-and-play Transformer module, which we call BatchFormer. BatchFormer applies the Transformer to the batch dimension before the network classifier to mine relationships between samples, such as similarity and partial sharing. At the same time, we introduce a shared classifier strategy to achieve batch invariance, allowing us to remove BatchFormer during testing without increasing any computational or memory burden on the network. Furthermore, we present a more generalized version, BatchFormerV2. BatchFormerV2 is a plug-and-play method for the Transformer structure. Our experiments demonstrate that BatchFormer achieves the best results in long-tail recognition, compositional zero-shot learning, and domain generalization. We have shown the effectiveness of BatchFormer across more than 15 datasets and 7 tasks. In the future, we will continue to explore feature representation learning and model architecture based on sample relationships.
References

1. Hou, Zhi, Baosheng Yu, and Dacheng Tao. “BatchFormer: Learning to Explore Sample Relationships for Robust Representation Learning”. CVPR2022
2. Hou, Zhi, et al. “BatchFormerV2: Exploring Sample Relationships for Dense Representation Learning.” arXiv preprint arXiv:2204.01254 (2022).
3. Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. ICLR2018
4. Golnaz Ghiasi, Yin Cui, Aravind Srinivas, Rui Qian, Tsung- Yi Lin, Ekin D Cubuk, Quoc V Le, and Barret Zoph. Simple copy-paste is a strong data augmentation method for instance segmentation CVPR2021
5. Shiv Shankar, Vihari Piratla, Soumen Chakrabarti, Siddhartha Chaudhuri, Preethi Jyothi, and Sunita Sarawagi. Generalizing across domains via cross-gradient training. In ICLR2018
6. Zhi Hou, Xiaojiang Peng, Yu Qiao, and Dacheng Tao. Visual compositional learning for human-object interaction detection. ECCV2020
7. Ziwei Liu, Zhongqi Miao, Xiaohang Zhan, Jiayun Wang, Boqing Gong, and Stella X. Yu. Large-scale long-tailed recognition in an open world. In CVPR2019
8. MF Naeem, Y Xian, F Tombari, and Zeynep Akata. Learning graph embeddings for compositional zero-shot learning. In CVPR2021
9. Martin Arjovsky, Le ́on Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization.
10. Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. CVPR2018
11. Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16×16 words: Transformers for image recognition at scale. ICLR2020
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the backend of the "Xiaobai Learns Vision" public account to download the first Chinese version of the OpenCV extension module tutorial, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the backend of the "Xiaobai Learns Vision" public account to download 31 practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and face recognition, to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the backend of the "Xiaobai Learns Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (which will be gradually subdivided in the future). Please scan the WeChat ID below to join the group, noting: "Nickname + School/Company + Research Direction". For example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format when noting; otherwise, it will not be approved. After successful addition, you will be invited to the relevant WeChat group based on your research direction. Please do not send advertisements in the group, or you will be removed. Thank you for your understanding~