
Click on the above“Beginner Learning Vision”, select to add “Star” or “Top”
Heavyweight content delivered in real-time
For academic sharing only, does not represent the position of this public account. Contact for deletion in case of infringement.Reprinted from: Specialized Knowledge

Industrial defect detection methods based on deep learning can reduce the costs of traditional manual quality inspection, improve detection accuracy and efficiency, thus playing an important role in smart manufacturing and gradually becoming one of the emerging research hotspots in the field of computer vision. They are widely applied in various production and operation scenarios such as unmanned quality inspection, intelligent patrol inspection, and quality control. This overview aims to comprehensively summarize the task definitions, difficulties, challenges, mainstream methods, public datasets, and evaluation metrics of industrial defect detection to help researchers quickly understand the field. Specifically, this article first introduces the background and characteristics of industrial defect detection. Next, based on the actual data labeling situation, three research task settings are divided: known defect patterns, unknown defect patterns, and few defect labels. Further categorization and analysis are conducted based on method types, discussing the performance advantages and applicable scenarios of each method, clarifying the relevance of methods to actual application needs. In addition, this article summarizes key auxiliary technologies in method deployment and highlights the limitations of existing methods in practical industrial applications. Finally, this article looks forward to the future development trends and potential research directions in this field.
http://scis.scichina.com/ssi2022.html#526
Introduction
From large aircraft wings to small chip grains, industrial products are ubiquitous in modern society. Industrial defect detection aims to identify various visible defects in industrial products and is one of the important technologies for ensuring product quality and maintaining production stability. Traditional defect detection required manual screening, which is costly and inefficient, making it difficult to cover large-scale quality inspection needs. In recent years, with the emergence of new technologies in industrial imaging, computer vision, and deep learning, vision-based industrial defect detection technology has made significant progress and has become an effective solution for product appearance quality inspection, attracting strong attention from both academia and industry. Industrial defect detection can be used not only for detecting various industrial products, such as metals, textiles, and semiconductors, but also boasts excellent detection accuracy and efficiency, providing a simple and safe operating environment. Therefore, industrial defect detection has become an important foundational research and technology in the field of smart manufacturing and is widely applied in scenarios such as unmanned quality inspection, intelligent patrol inspection, production control, and anomaly tracing. The “Made in China 2025” action plan points out that building a manufacturing powerhouse is a daunting and urgent task that requires accelerating the deep integration of information technology and industrialization and promoting the intelligence of production processes. Thus, vision-based industrial defect detection not only has significant research value but also broad application prospects. However, compared to general object detection tasks, industrial defect detection faces many challenges, such as a shortage of defect samples, low visibility of defects, irregular shapes, and unknown types, leading to many existing methods struggling to meet the demands for high precision and speed, thus leaving many issues to be resolved on the path to practical application.
Since industrial defects can be viewed as “anomalies” in the appearance of industrial products, some industrial defect detection methods have adopted anomaly detection approaches. However, the definitions of anomaly detection and industrial defect detection differ. Specifically, the concept of anomaly detection is broader and more abstract, where image anomaly detection primarily focuses on whether the input image is an anomaly instance, while industrial defect detection is more concerned with pixel-level detection tasks. At the pixel level, the differences between anomalies and normal patterns are more subtle, significantly increasing detection difficulty. Therefore, directly using anomaly detection methods is often insufficient to meet the task requirements of industrial defect detection.
In recent years, deep learning methods have gradually dominated this field due to their exceptional performance in handling complex backgrounds and subtle defects in industrial images. In light of this, this article reviews deep learning-based industrial defect detection methods, aiming to help researchers quickly gain a systematic understanding of task settings, mainstream methods, evaluation systems, and other aspects of this field. Given that this task has strong application-driven characteristics, this article categorizes three task settings based on the actual situation of data sample labeling and usage: known defect patterns, unknown defect patterns, and few defect labels. In particular, this article also summarizes key auxiliary technologies that facilitate method deployment, which help enhance the practicality of methods. This article focuses on the commonalities and differences between methods, gradually analyzing their development context in a problem-oriented manner, and combining the current state of research in the field to look forward to future development trends, hoping to help researchers broaden their thinking.
Currently, most reviews at home and abroad [1∼5] discuss methods in the broad field of anomaly detection, attempting to cover various data forms such as images, videos, tables, and sequences. Literature [2, 3] provides a comprehensive summary and analysis of deep learning-based anomaly detection methods, but lacks discussions specific to industrial scenarios. Literature [6, 7] reviews methods with an industrial production background but primarily focuses on traditional methods and system control. Literature [8] systematically summarizes deep learning-based surface defect detection methods but mainly organizes supervised methods. Recently, many new results have emerged from studies based on unsupervised and semi-supervised settings, but there is currently no comprehensive and detailed review literature specifically for the field of industrial defect detection. Therefore, this review aims to fill this gap and emphasizes the introduction and summary of such new methods. The organization of the subsequent content in this article is as follows: Section 2 introduces the definition of the industrial defect detection problem, analyzes research difficulties and challenges; Section 3 introduces mainstream industrial defect detection methods based on three task settings, further categorizing and analyzing methods according to their design principles; Section 4 reviews key auxiliary technologies for practical deployment; Section 5 introduces commonly used public datasets and evaluation metrics and compares the performance of typical methods; finally, Section 6 summarizes the current state and limitations of research and looks forward to future development trends and potential research directions.
2 Problem Definition and Research Status
2.1 Problem Definition
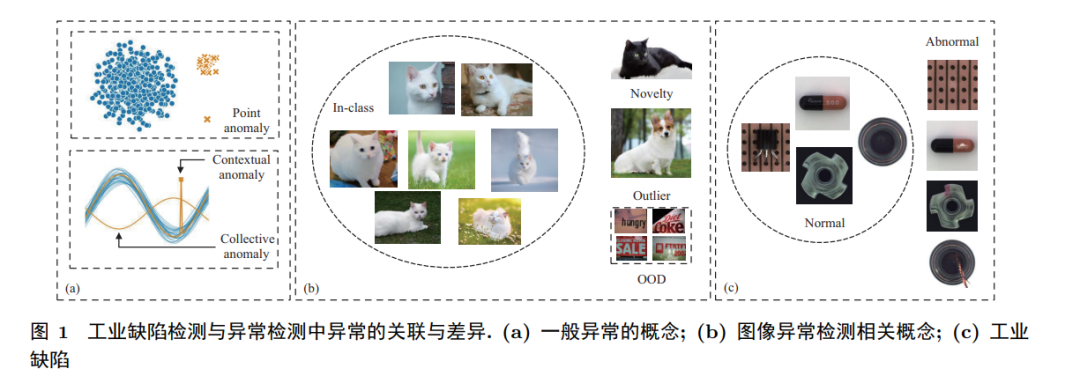
Vision-based industrial defect detection aims to discover visible defects in various industrial products such as textiles, chips, pharmaceuticals, and even construction materials. Although these defects may be small, they can severely compromise the normal function of the product. They can occur at any stage of the industrial product’s lifecycle, such as during production, transportation, and usage. The concept of defect can be likened to anomaly. Anomaly refers to data that exceeds the expected pattern range [1], and a large number of works have defined and categorized it [1∼5, 9, 10]. Scholars often categorize anomalies based on whether there are contextual relationships between data into point anomalies, contextual anomalies, and cluster anomalies [1, 5, 10]. As shown in Figure 1(a), point anomalies, also known as outliers [9], describe independent data that deviates numerically from normal samples; contextual anomalies also describe data points whose values fall within the normal range but do not conform to local contextual rules; cluster anomalies describe a collection of related data, where each instance’s value in the collection is within the normal range when examined individually, but the overall characteristics of the collection do not conform to the normal pattern. Specifically for image data, literature [5] divides image anomalies into low-level texture anomalies and high-level semantic anomalies based on whether obvious semantics are present. Related concepts include novelty and out-of-distribution (OOD) data [4]. In the image classification task shown in Figure 1(b), the definition of the cat class is based on white cat samples. A white dog, despite its similar color, is considered an outlier due to its different semantic category; a black cat belongs to the cat class, sharing the same semantic category, but its color attribute did not appear in the training set, making it a novelty; OOD focuses on the distribution differences of data sets, where the distribution of text data sets and natural scene data sets of cats shows significant differences. Similarly, in industrial defect detection, normal samples include multiple product types, and defects can be viewed as “anomalies” in their appearance. The difference is that industrial defects often appear in small areas of the image, are less pronounced, and have ambiguous semantic concepts. Therefore, general image anomaly detection often only needs to distinguish between normal and abnormal samples, while industrial defect detection focuses more on detecting anomalous pixels within the image. In practical industrial scenarios, the definition of defects is more subjective, prompting scholars to seek its relationship with anomaly detection. Considering the similarities among the aforementioned tasks, some defect detection methods also adopt the ideas of anomaly detection, novelty detection, and OOD detection. For example, considering only the pixel values of defects can be likened to novelties or outliers; when considering the relationships between pixels, it can be compared to contextual anomalies or cluster anomalies.
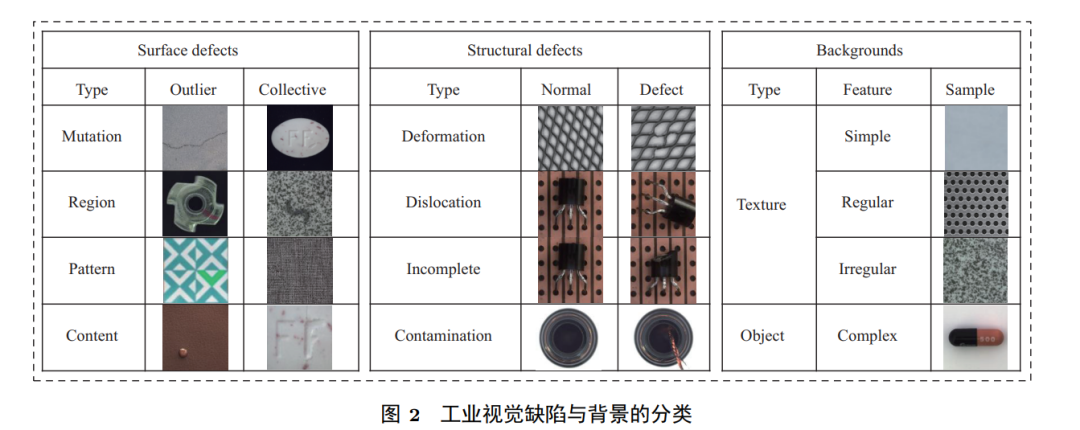
Although defects typically belong to unknown patterns, certain commonalities can still be discovered from existing defect samples. Therefore, summarizing the types of defects and backgrounds helps in designing targeted detection methods. As shown in Figure 2, this article categorizes industrial defects into surface defects and structural defects based on their occurrence location and manifestation. Surface defects primarily occur in local areas of the product’s surface, usually manifested as texture mutations, anomalous areas, irregular patterns, or erroneous designs. Examples include surface cracks, color blocks, sparse weaving of fabrics, and printing errors in trademarks. Based on the differences in pixel values between the defect area and the surrounding background, they can be likened to outliers or cluster anomalies: outlier-type defects typically exhibit significant differences in pixel values compared to normal images; cluster anomaly-type defects have pixel values within the same range as the surrounding normal areas, making them harder to detect. Structural defects are primarily caused by overall structural errors in the product, including deformation, misalignment, loss, and contamination. Examples include bending of wires, edge defects of diodes, or being in the wrong position. Accordingly, backgrounds can be categorized into texture and object classes based on whether they contain the overall product structure. The texture class focuses on the local surface of the product and is categorized into simple textures, regular textures, and irregular textures based on complexity. The object class includes the entire product, with a more complex structure and background interference outside the product. At this point, not only surface defects need to be considered but also structural defects. It is evident that different types of defects exhibit varying levels of subtlety against different backgrounds. Even between different instances of the same type of defect, visibility may vary significantly.
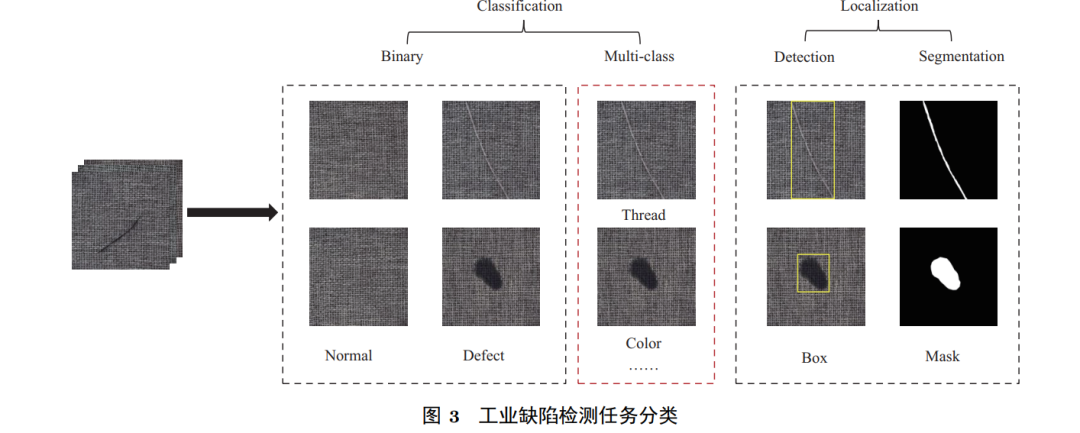
Depending on the granularity of the output results, industrial vision defect detection tasks generally include classification and localization. As shown in Figure 3, for an image instance to be tested, the classification task first categorizes it into either normal or defect samples; when the types of defects are known, it can further discriminate defect types, for example, there may be multiple defects such as threading, discoloration, etc., on the fabric. The goal of the localization task is to find the specific area of the defect within the image, which can be divided into detection (bounding box) and segmentation (pixel-level) based on how the defect area is described. In fact, these tasks can sometimes be performed simultaneously; for example, using visualization methods on a classification model [11∼13] can achieve pixel-level localization, and segmentation results can also be used to determine the overall classification of the image. Due to the irregular shapes and varying sizes of industrial defects, bounding boxes may not accurately represent the location of defects and are likely to introduce a significant amount of irrelevant background information, complicating the evaluation of defect detection performance. Therefore, in practical defect localization tasks, researchers focus more on defect segmentation methods. In light of this, this article will focus on the work of classification and segmentation tasks.
2.2 Research Overview
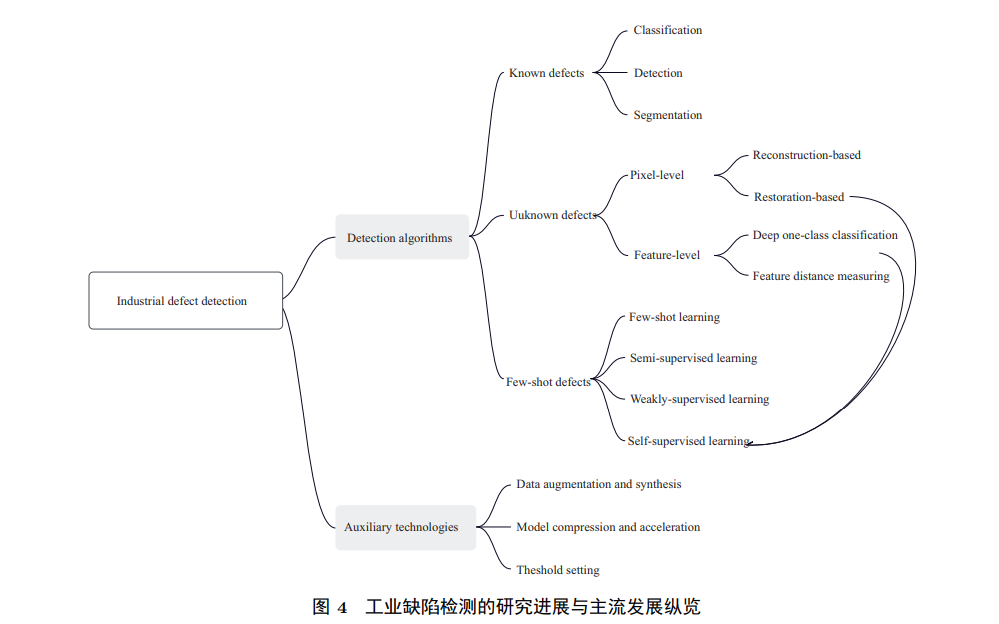
Industrial defect detection has long been one of the most important research areas in industrial vision. In recent years, with the popularity of deep learning in computer vision tasks, deep learning-based industrial defect detection methods have developed rapidly and gradually become mainstream. Thanks to the powerful feature extraction capabilities of convolutional neural networks (CNNs) and their ability to represent high-dimensional data, deep learning-based methods can automatically learn features that are difficult to design manually, not only saving the cost of manually designed features but also significantly improving detection accuracy. Compared to traditional methods based on image processing and statistical learning, it is better at handling complex industrial image data. This article organizes recent hot research progress in the field of industrial defect detection at home and abroad into the structure shown in Figure 4. Detection algorithms are classified into three settings based on the actual data situation in industrial scenarios: known defect patterns, unknown defect patterns, and few defect labels. When the defect patterns are known, supervised deep learning methods are generally employed, requiring sufficient and accurate sample labeling, and methods can be designed from the perspectives of classification, detection, and segmentation. When the defect patterns are unknown, unsupervised deep learning methods are usually employed to construct comparative objects. Depending on the dimensions of the comparative objects, methods can be categorized into image dimension and feature dimension similarity comparisons, and further subdivided based on method principles. The few defect label scenario closely resembles actual industrial situations, where the training set contains imbalanced positive and negative samples, and only a few defect samples have accurate or inaccurate labels. At this point, depending on specific data labeling situations, emerging methods such as small sample, semi-supervised, and weakly supervised methods are employed to address these issues, which have gradually gained high attention in both academia and industry. Self-supervised learning, a type of unsupervised learning, extracts self-supervisory information from unlabeled data and has recently been widely applied in industrial defect detection. Therefore, this article summarizes self-supervised methods from the perspective of constructing supervisory information. Auxiliary technologies are primarily used to enhance the practicality of detection methods; this article discusses them from three angles. Data augmentation and synthesis provide sufficient training sets for data-hungry detection models; model compression and acceleration technologies address low storage overhead and real-time requirements during deployment; threshold settings aim to find the most suitable classification boundaries during the inference phase.
3 Detection Algorithms
3.1 Known Defect Patterns
In many practical industrial scenarios, most defect types have been statistically and inductively analyzed in advance, allowing for the direct detection of defects using their features or the collection and labeling of datasets using prior knowledge to train models. Supervised deep learning methods based on known defect patterns have achieved relatively mature development and application in many visual tasks. When the defect types are known and sufficient labeled samples are available, or when solving multi-class classification problems of defect types, industrial defect detection often employs supervised methods. Most of these methods apply existing general object classification, detection, and segmentation models to industrial scenarios and fine-tune them based on the subtlety of defects and the speed requirements of the models. Supervised methods can address multi-class classification issues, suitable for situations where most defect types are known or where defect characteristics are prominent. Although they require high labeling costs, these methods demonstrate excellent performance when sufficient samples are available and have tested the effectiveness of methods in some practical applications. Existing methods are relatively mature in simple and rule-based industrial scenarios, but there is still room for development in detecting complex backgrounds and irregular subtle defects. However, when faced with insufficient samples and unknown defect patterns, supervised methods still have limitations.
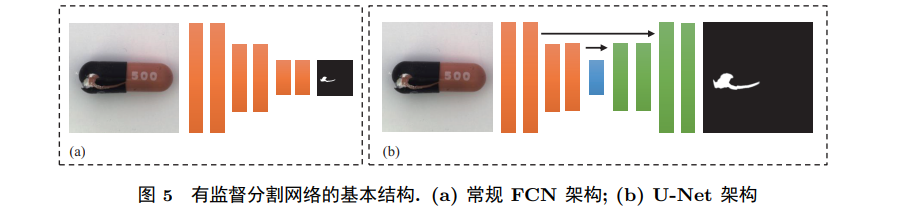
3.2 Unknown Defect Patterns
In practical situations, it is extremely difficult to obtain samples containing defects. Given the unknown and irregular nature of defects, methods based on prior knowledge of defects have significant limitations. Therefore, unsupervised settings have garnered widespread attention. Most of these methods draw on anomaly detection ideas, modeling easily obtainable and describable normal samples. Defects are defined as patterns outside the normal range. The objective of tasks in unsupervised settings is usually to determine whether the sample being tested contains defects or to locate defect areas, with the output of localization results generally being pixel-level segmentation results. Deep learning methods based on unsupervised settings only require easily obtainable normal samples for model training, without the need for real defect samples. They not only solve the problem of supervised deep learning methods failing to detect unknown defects but also possess stronger image feature representation capabilities than traditional methods, making them a current research hotspot. The core idea of such methods is to construct a “template” that is closest to the sample being tested for comparison, achieving defect detection and localization based on pixel or feature differences. Depending on the dimensions of comparison, this article categorizes methods into those based on image similarity and those based on feature similarity.
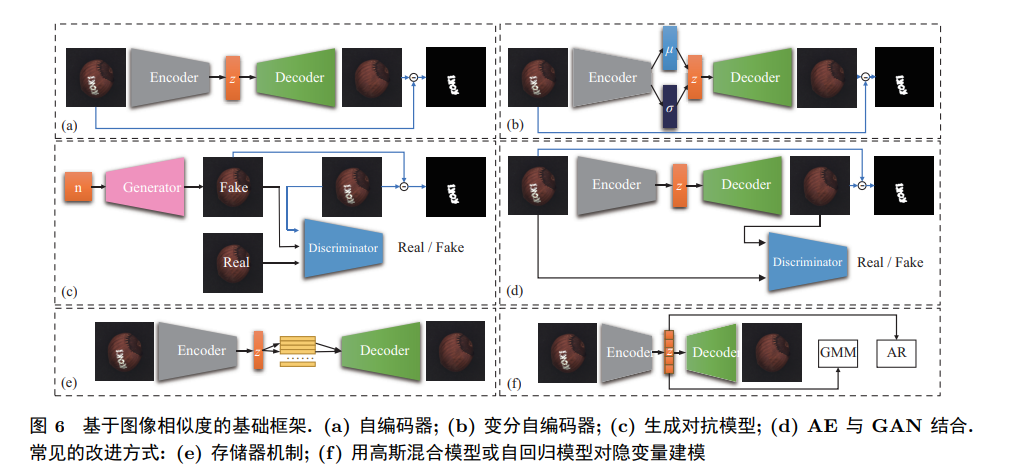
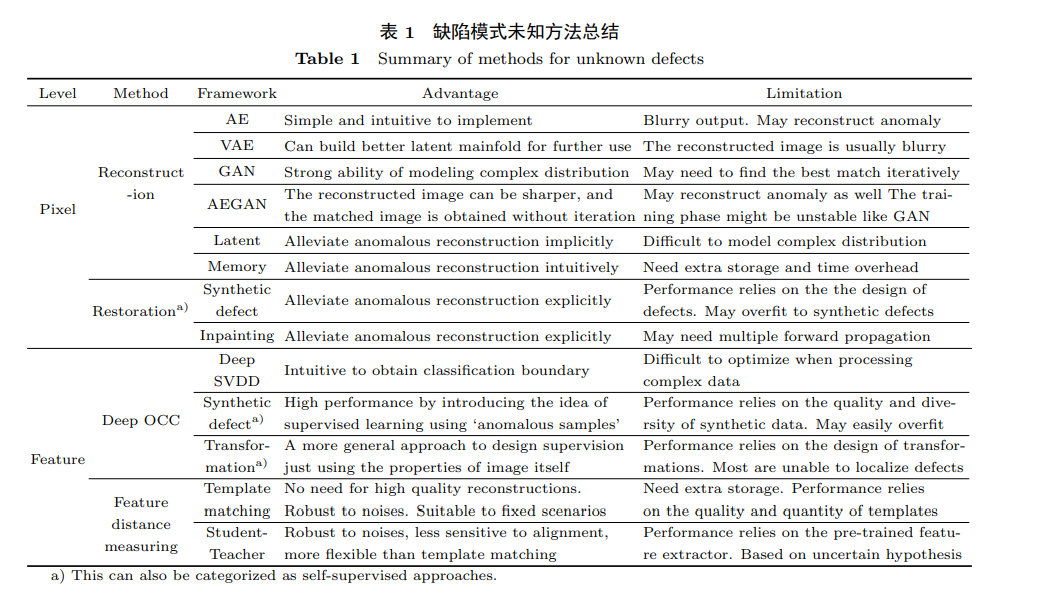
3.3 Few Defect Labels
In actual industrial scenarios, the situation often lies between the two settings mentioned above. It is possible to obtain relatively sufficient normal samples while also collecting a small number of defect samples in advance for labeling. Even if defect samples only have coarse-grained labeling, they can still enhance detection performance. Therefore, purely supervised and unsupervised methods struggle to fully utilize the available data, making them suboptimal solutions. At this point, researchers have attempted to design more reasonable methods based on small sample, semi-supervised, and weakly supervised settings to address issues such as sparse samples, data imbalance, and imprecise labeling.
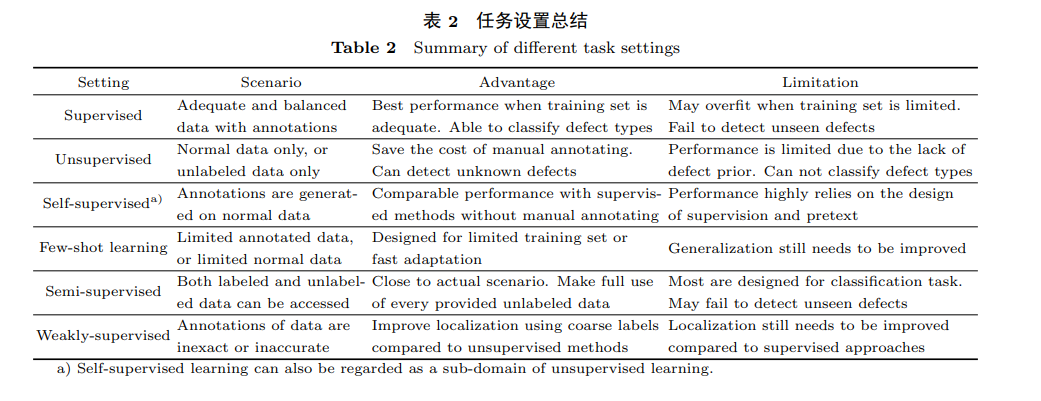
4 Auxiliary Technologies
Detection method design must consider not only the detection accuracy of the method itself but also utilize auxiliary technologies to assist its industrial application based on practical situations. This article mainly reviews three key auxiliary technologies: data augmentation aims to increase the diversity of samples using synthesis and other means to enhance the performance of supervised and self-supervised methods; lightweight technology focuses on the time and space complexity of models during practical deployment, helping models achieve real-time detection levels on low-power devices; threshold settings are crucial for distinguishing between normal and abnormal samples, and suitable and controllable threshold settings help methods achieve high practical performance.
5 Datasets and Performance Evaluation
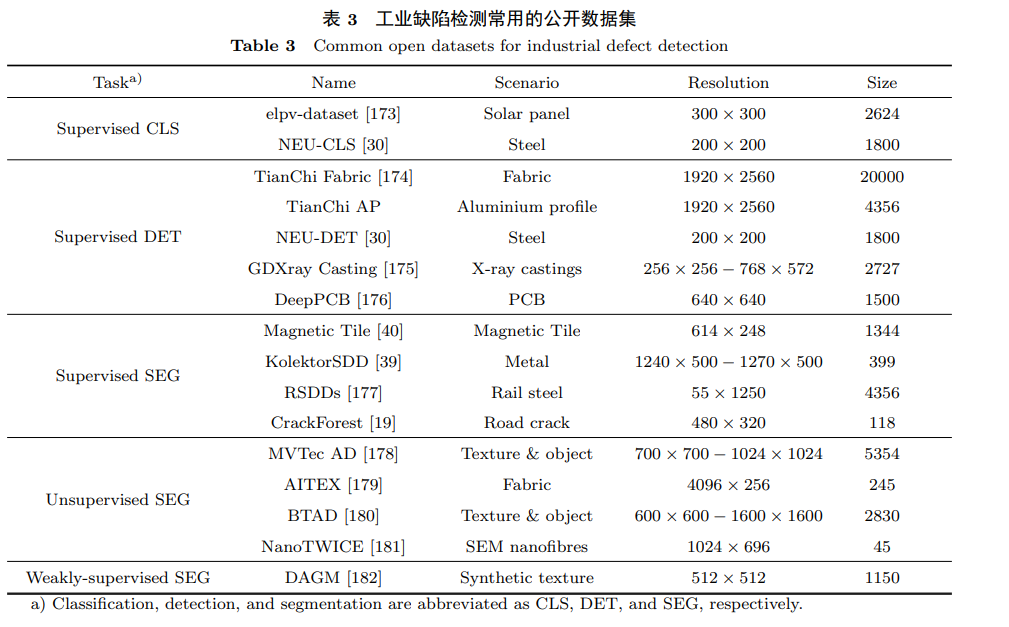
5.1 Commonly Used Datasets
The datasets currently commonly used for industrial defect detection research are shown in Table 3 [19, 30, 39, 173∼182]. This article specifically introduces typical datasets proposed in recent years that fit different task settings.
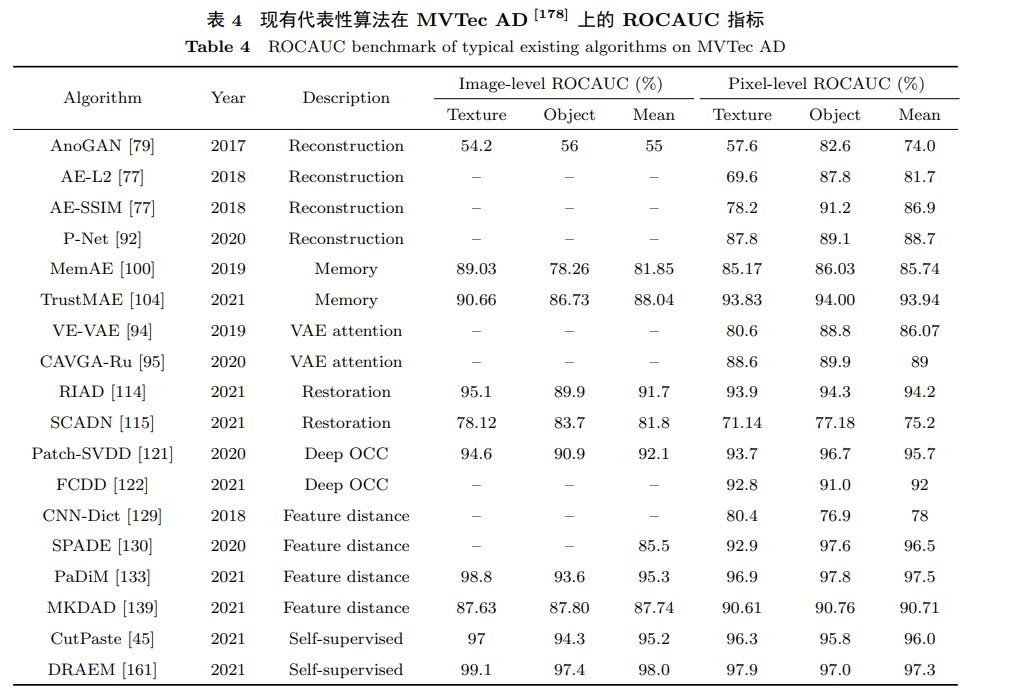
5.2 Evaluation Metrics
Since classification and segmentation typically have significant practical value in industrial defect detection, this article mainly introduces evaluation metrics for these two types of tasks. Classification performance is usually evaluated using accuracy, precision, and recall. Accuracy refers to the proportion of all correctly predicted classes to the total; precision, also known as positive predictive value, indicates the proportion of correct predictions among samples predicted as defects; recall, also known as sensitivity or true positive rate (TPR), indicates the proportion of all defects that are correctly detected. In practical applications, the false positive rate (FPR) and false negative rate (FNR) are often of concern as they measure the shortcomings of the model. Pixel-level defect localization tasks can be viewed as two-class segmentation problems between foreground and background. When the output abnormal score map represents the probability of corresponding pixels being defects, it is necessary to set corresponding thresholds to obtain binary segmentation results. Therefore, segmentation metrics can also be divided into fixed threshold metrics and threshold-independent metrics.
6 Summary and Outlook
6.1 Summary
As a core technology in industrial vision, vision-based industrial defect detection is gradually becoming one of the hottest emerging research issues due to its wide and important application value. In recent years, a large number of new theories and methods have emerged and have gradually been applied in practical industries. This article comprehensively organizes the task definitions, research difficulties, detection methods, auxiliary technologies, commonly used public datasets, evaluation metrics, and typical method performances in this field, with a focus on reviewing the significant progress of deep learning methods. However, despite the fact that industrial defect detection methods have demonstrated high performance on some industrial data, existing research still has significant limitations that restrict further research and implementation of related methods.
6.1.1 Task Settings Closer to Reality
Supervised defect detection methods have gradually matured, exhibiting superior performance. However, supervised methods depend on the support of large-scale datasets with precise annotations, and the cost of data collection and labeling is high, making it impossible to perfectly align with actual industrial scenarios. At the same time, supervised methods cannot address the detection of new category defects. Although unsupervised methods significantly reduce the need for data labeling and can detect unknown defects, they still cannot replace supervised methods in terms of localization performance and interpretability. In practical production environments, the scenario of few defect labels is more common. Users can not only provide a large number of normal samples but also provide a small number of defect samples with precise or rough annotations. Compared to the aforementioned two settings, small sample, semi-supervised, and weakly supervised methods align more closely with industrial scenarios and can utilize resources more fully, thus garnering rapid attention. Currently, these methods are still in their early stages and require further research and development.
6.1.2 Lack of Comprehensive Datasets
Datasets are the foundation of research on deep learning methods. Currently, the datasets commonly used for industrial defect detection tasks mainly suffer from limitations such as single background types and single defect types, making it impossible to simulate the complex detection scenarios in reality. In actual industrial production processes, the product images captured may come from different imaging conditions, different shooting angles, or different processes, and different types of defects may appear on the same product. Constructing datasets that closely resemble actual industrial scenarios and task settings not only aids in the development of more practical algorithms but also facilitates the actual deployment of algorithms. For example, multi-imaging datasets can highlight defects that are difficult to detect under one imaging condition in another imaging condition, thus facilitating defect discovery. The performance of industrial defect detection methods in extended tasks such as unmanned patrol inspection and anomaly tracing also needs to be validated through corresponding datasets. Therefore, the establishment and improvement of new datasets are also very important; only by constructing suitable datasets can the development of methods under various new scenarios, tasks, and settings be supported.
6.2 Outlook
In addition to the shortcomings of current research summarized above, there are many highly promising research directions in this field that await further exploration.
6.2.1 Neural Architecture Search
Most existing deep learning methods rely on manually designed deep neural networks and empirically set hyperparameters. Therefore, the existing model structures may not be the optimal solution for industrial defect detection. Rippel et al. [132] compared the impact of various base networks on model performance, among which the EfficientNet [187] obtained through automated machine learning (AutoML) outperformed manually designed ResNet [188]. The efficient network structure of EfficientNet and the Swish activation function are considered the main reasons for performance improvement. Compared to other general visual detection tasks, most industrial vision usage scenarios are more specific, and using neural architecture search (NAS) methods to automatically search for the optimal model for specific task scenarios is a feasible solution that not only helps to compensate for the shortcomings of manual empirical settings but also enhances model efficiency. AutoOD [189] achieves detection performance superior to manual models by searching AE architecture model parameters based on NAS. However, the application of NAS in unsupervised and semi-supervised settings is still limited, and it may develop in related tasks in the field of industrial vision in the future.
6.2.2 Application of Transformers
In recent years, Transformer models [190] have been introduced into the field of computer vision and have demonstrated superior performance in various visual tasks [191∼195]. Compared to CNNs that focus on local feature relationships, visual Transformers utilize attention mechanisms to model long-distance relationships within images. Xie et al. [196] improved the efficient Swin Transformer [194] for supervised defect detection of solar panels. It enhances the extraction of global semantic features by adding inter-window attention and achieves high classification performance through multi-scale aggregation modules that combine features at different levels. However, the performance advantages of Transformer models typically require sufficient training data support, whereas most industrial defect detection scenarios struggle to obtain sufficient defect data. Therefore, researchers are attempting to introduce Transformers in unsupervised settings, generally using them in methods based on image similarity. Mishra et al. [180] replaced the encoder of image reconstruction models with Transformer structures to enhance the extraction ability of global features. At the same time, density estimation of the Transformer’s encoding results is performed using GMM. During the testing phase, defect localization is achieved based on the density estimation results of image blocks from GMM, combined with reconstruction errors for image-level classification. Pinaya et al. [197] argue that in defect detection methods based on image restoration tasks [114], long-distance information is beneficial for high-quality image restoration, thereby enhancing defect segmentation capabilities, and thus replaced CNNs with Transformers to restore image blocks based on surrounding information, ultimately performing defect segmentation based on reconstruction errors. Transformer models possess the capability of modeling global relationships and offer better interpretability [199]. However, their demand for computational resources also increases correspondingly, posing challenges to the low-cost requirements of industrial scenarios. Currently, related work continues to explore the application of efficient Transformer models [194, 195] with small datasets [199]. Although the practicality of Transformers in the field of industrial defect detection has yet to be fully explored, existing research has already pointed out their potential.
6.2.3 Multi-Image and Multi-Modal Approaches
Early industrial defect detection methods utilized optical methods to enhance the significance of defects, making them easier to detect. In fact, the types of industrial defects vary widely, and each may have its own suitable imaging methods; therefore, leveraging the differences produced by different imaging conditions to create distinctions is a promising approach. In practical scenarios, other imaging methods such as infrared and X-ray may be suitable for specific product quality inspection tasks; 3D information obtained from structured light and lasers can further enhance the expression of structural defects in products. Currently, most methods focus solely on single RGB, grayscale images, or other types of input imaging. To comprehensively utilize the perceptual capabilities of different imaging conditions, models can further consider integrating features from multi-modal data to enhance detection performance, addressing more complex scenarios.
6.2.4 More Interpretable Methods
Although deep learning has greatly promoted the development of industrial defect detection, emerging methods possess outstanding detection performance, many methods still lack comprehensive interpretability. Many unsupervised methods also rely on a large number of empirical assumptions. Research on model interpretability not only helps people understand the working mechanisms of models but also promotes the development of new methods. From the perspective of assisting human detection, establishing human-machine trust is crucial for advancing practical applications. Therefore, research on confidence prediction [200] and model visualization is significant not only in the field of industrial defect detection but also across the entire field of artificial intelligence.
6.2.5 Online Learning and Federated Learning
Existing methods mostly adopt offline learning, training models in advance based on corresponding datasets and then deploying them to production lines. However, due to the lack of labeled defect samples during the initial training phase, the actual performance of the model during deployment is often suboptimal. In practical applications, production lines can continuously provide new samples and may discover new types of defects. Therefore, utilizing online learning methods for rapid real-time adjustments to models will become one of the key areas of future research and application. Since certain products and their defects have common characteristics, combining samples from different production lines can help fully train and adjust models. Considering that industrial data often involves privacy issues, introducing a federated learning framework helps effectively combine samples from all parties while ensuring the privacy and security of each collaborator.
Download 1: OpenCV-Contrib Extension Module Chinese Tutorial
Reply "Extension Module Chinese Tutorial" in the "Beginner Learning Vision" public account backend to download the first Chinese version of the OpenCV extension module tutorial available online, covering installation of the extension module, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the "Beginner Learning Vision" public account backend to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, adding eyeliner, license plate recognition, character recognition, emotion detection, text content extraction, and facial recognition, to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the "Beginner Learning Vision" public account backend to download 20 practical projects based on OpenCV, achieving advanced learning in OpenCV.
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will gradually be subdivided). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format for the note; otherwise, it will not be approved. After successful addition, you will be invited to join relevant WeChat groups based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed from the group. Thank you for your understanding.~