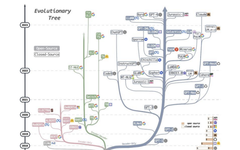

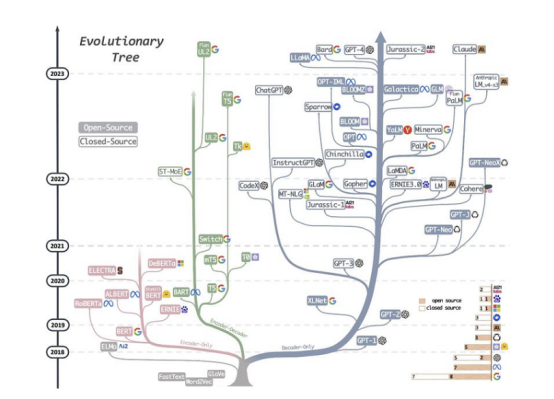
LLM evolution tree
Formally, a language model with only a decoder is simply a conditional distribution p(xi|x1···xi−1), which denotes the probability of the next token xi given the context x1···xi−1. This formula assumes that the process is a Markov process and has been studied in many use cases. This simple setup allows us to generate tokens one by one in an autoregressive manner.
Before delving deeper, it should first be pointed out that this formula has limitations in understanding Artificial General Intelligence (AGI): thinking is a nonlinear process, but our communication device—our mouth—can only speak linearly. For this reason, language is presented in the form of a linear sequence of words, which is a reasonable start for modeling language with a Markov process. However, I remain skeptical as to whether this formulation can fully capture the thought process (or AGI). On the other hand, thinking and language are interrelated, as demonstrated by GPT-4, where a sufficiently powerful language model can still exhibit some thinking capabilities. In the following content, let us explore the scientific breakthroughs that make Large Language Models (LLMs) intelligent.
Transformer
There are many ways to model/represent this conditional distribution p(xi|x1···xi−1). In LLMs, a neural network architecture called Transformer is used to estimate this conditional distribution. In fact, before the advent of Transformers, neural networks, especially various Recurrent Neural Networks (RNNs), were widely used in language modeling. RNNs process tokens sequentially, maintaining a state vector that contains the representation of data preceding the current token. To process the nth token, the model combines the sentence state from the beginning of the sentence to token n-1 with the information of the new token, creating a new state that represents the entire sentence from the beginning to token n. Theoretically, if the state at each point contains contextual information of the tokens, then information from the tokens can propagate arbitrarily far back into the sequence. However, the vanishing gradient problem causes the model to lack precise, extractable information about earlier tokens at the end of long sentences. The computation of tokens depends on the results of previous token computations, which also makes it difficult to compute in parallel on modern GPU hardware.
These issues are resolved through the self-attention mechanism in Transformers. Transformers rely entirely on attention mechanisms to draw global dependencies between inputs and outputs, avoiding repeated occurrences. Attention layers can access all previous states and measure them based on learned relevance metrics, providing relevant information for distant tokens. More importantly, Transformers use a non-RNN attention mechanism to process all tokens simultaneously and compute the attention weights between them across consecutive layers. Since the attention mechanism only uses information from lower layers, it can compute all tokens in parallel, thus improving training speed.

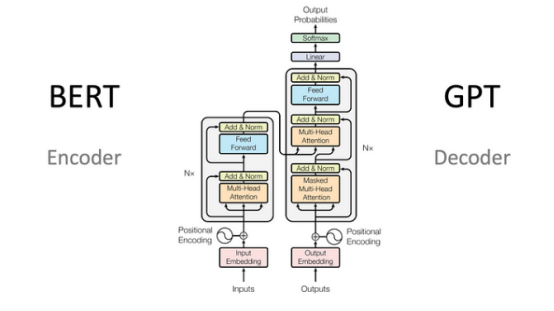
By using a byte pair tokenizer to parse the input text into tokens and converting the tokens into embedding vectors, positional information of the tokens is added during the embedding process. The building blocks of Transformers are scalable dot-product attention units. When a sentence is passed to the Transformer model, the model simultaneously computes the attention weights between the tokens. The attention unit generates embeddings for each token in context, which contain both the information of the token itself and a weighted combination of the attention weights of other relevant tokens.
For each attention unit, the Transformer model learns three weight matrices: query weight WQ, key value weight WK, and value weight WV. For each token i, the input word embedding is multiplied by each element in the three weight matrices to generate a query vector qi, a key value vector ki, and a value vector vi. The attention weight is the dot product between qi and kj, multiplied by the square root of the dimension of the key value vector, and normalized through softmax. The output of the attention unit for token i is the weighted sum of all token value vectors, weighted by the attention from token i to each token j. The attention calculations for all tokens can be expressed as a large matrix operation:

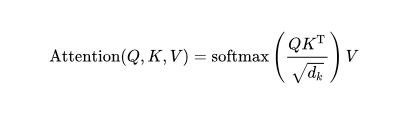
A set of (WQ, WK, WV) matrices is called an attention head, and each layer of the Transformer has multiple attention heads. By using multiple attention heads, the model can compute different relevances between tokens. The computations of multiple attention heads can be executed in parallel, and the outputs are connected and projected to the same dimension as the input through a WO matrix.
On the encoder side, after the self-attention mechanism, there is a fully connected multi-layer perceptron (MLP). The MLP block further processes each output encoding individually. In the encoder-decoder setup (e.g., for translation), an additional attention mechanism is inserted between the self-attention and the MLP to extract relevant information from the encoding generated by the encoder. In a decoder-only architecture, this is unnecessary. Whether in an encoder-decoder architecture or a decoder-only architecture, the decoder cannot use the current or future outputs to predict outputs, so it must partially mask the output information to truncate the backward information flow, achieving autoregressive text generation. To generate tokens one by one, a softmax layer follows the last decoder to produce various output probabilities across the entire vocabulary.
Supervised Fine-Tuning
The decoder-only GPT is essentially an unsupervised (or self-supervised) pre-training algorithm aimed at maximizing the likelihood of the following function:

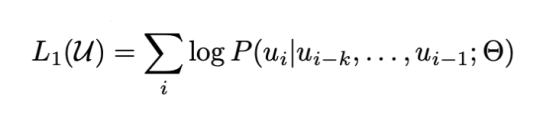
where k is the size of the context window. Although this architecture is task-agnostic, GPT shows that by performing generative pre-training of the language model on different unlabeled text corpora, followed by corpus-specific fine-tuning for each specific task, significant improvements can be achieved in various tasks such as natural language inference, question answering, semantic similarity, and text classification.
After pre-training the model using the above objective function, the above parameters can be used in supervised target tasks. Given a labeled dataset C, where each instance contains an input token sequence x1, …, xm and a label y, it is input into the pre-trained model to obtain the final activation hlm of the Transformer block, which is then input into a linear output layer parameterized by Wy to predict y:

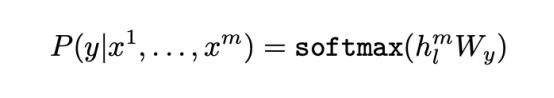
Accordingly, the following objective function is defined:

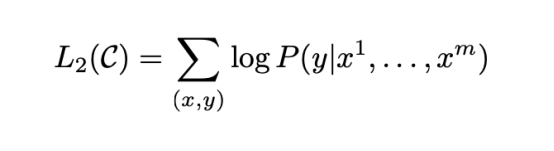
Moreover, treating language modeling as an auxiliary objective is beneficial as it improves the generalization of the supervised model and accelerates convergence. That is, optimizing the following objective:

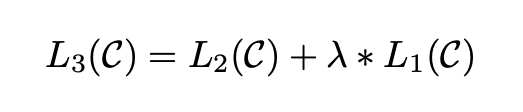
Text classification can be fine-tuned directly as described above. Other tasks, such as question answering or textual entailment, have structured inputs, such as ordered sentence pairs or three sets of documents, questions, and answers. Since the pre-trained model is trained on continuous text sequences, some modifications are required to apply it to these tasks.

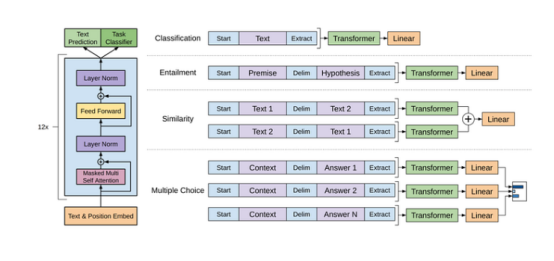
Textual entailment: Connect the premise p and hypothesis h token sequences with a separator token ($).
Similarity: The two sentences being compared do not have an inherent ordering. Thus, the input sequence contains two possible sentence orders (with a separator in between) and processes each sequence independently to generate two sequence representations. These two sequence representations are input to a linear output layer after being summed element-wise.
Question Answering and Commonsense Reasoning: Each sample has a context document z, a question q, and a set of possible answers {ak}. GPT connects the document context and question with each possible answer, adding a separator token in between to obtain the sequence [z; q; $; ak]. Each sequence is processed independently, and then normalized through a softmax layer to generate an output distribution of possible answers.
Zero-Shot Transfer (i.e., Meta-Learning)
While GPT shows that supervised fine-tuning on specific task datasets works well, achieving more robust performance on specific tasks usually requires fine-tuning on thousands to hundreds of thousands of examples for that specific task. Interestingly, GPT-2 demonstrated that language models can learn multiple tasks without any explicit supervision by relying on documents plus questions (also known as prompts).
Learning to perform a single task can be represented in a probabilistic framework as estimating a conditional distribution p(output|input). Since a general system should be able to perform multiple different tasks, even with the same input, it should not only rely on the input but also on the task to be performed. That is, it should be modeled as p(output|input, task). Previous task conditioning is often implemented at the architectural or algorithmic level. However, language models provide a flexible way to specify tasks, inputs, and outputs as symbolic sequences. For example, a translation training example can be written as the sequence (Translate to French, English text, French text). Specifically, GPT-2 is based on a formatted “English sentence = French sentence” context pair, then samples from the greedy decoding of the English sentence and uses the first generated sentence as the translation.
Similarly, to do inductive summarization, GPT-2 appends the text TL; DR at the end of the article and generates 100 tokens using k = 2 Top-k random sampling, reducing repetition and producing a more abstract summary than greedy decoding. Likewise, training examples for reading comprehension can be written as (Answer question, document, question, answer).
Note that zero-shot transfer is different from zero-shot learning in the next section. In zero-shot transfer, “zero-shot” refers to not performing gradient updates, but it typically involves providing demonstrations for the model during inference (e.g., the aforementioned translation example), so it is not truly learning from zero samples.
I find an interesting connection between this meta-learning approach and Montague semantics, which is a theory of natural language semantics and its relationship with syntax. In 1970, Montague articulated his view:
In my view, there is no important theoretical difference between natural languages and the artificial languages of logicians; indeed, I believe it is entirely possible to understand the grammar and semantics of both languages with a single natural and mathematically precise theory.
From a philosophical perspective, both zero-shot transfer and Montague semantics treat natural language as a programming language, with LLMs capturing tasks by embedding vectors in a black-box manner. But how it works is still not very clear. In contrast, the most important feature of Montague semantics is its adherence to the principle of compositionality—that is, the overall meaning is a function of the meanings of its parts and their syntactic combination patterns, which may become a method for improving LLMs.
Contextual Learning
GPT-3 shows that scaling up language models greatly improves task-agnostic, few-shot performance. GPT-3 further specializes this description as “zero-shot,” “one-shot,” or “few-shot,” depending on how many demonstrations can be provided at inference time: (a) “few-shot learning,” or contextual learning, allows as many demonstrations as possible to be provided in the model’s context window (usually 10 to 100), (b) “one-shot learning” allows only one demonstration to be provided in the model’s context window (usually 10 to 100), and (c) “zero-shot” learning does not allow any demonstrations to be provided in the model’s context window, only allowing a natural language instruction to be given to the model.


For few-shot learning, GPT-3 randomly samples K examples from the training set as conditions to evaluate each example in the dataset, separating samples with 1 or 2 line breaks depending on the task. K can be any value from 0 up to the maximum allowed in the model’s context window, which is nctx = 2048, usually accommodating 10 to 100 examples. Typically, the value of K tends to increase, but not always.
For certain specific tasks, GPT-3 also uses natural language prompts in addition to (or K = 0) demonstrations, selecting one correct answer from multiple options (multiple choice) to complete the task, with prompts including K contextual examples plus a correctly completed example, followed by an example containing only contextual examples, and the evaluation process comparing the likelihood of each completed model.
For tasks involving binary classification, GPT-3 provides more semantically meaningful option names (e.g., “True” or “False” instead of 0 or 1) and treats the task as a multiple-choice question.
In tasks involving free-form completions, GPT-3 uses beam search. The evaluation process uses F1 similarity scores, BLEU, or exact matching to score the model, depending on the different criteria of the dataset at hand.
Model Size Issues
The capacity of language models is crucial for the success of task-agnostic learning. Increasing model capacity can improve cross-task performance in a logarithmic-linear manner. GPT-2 directly expanded the generation based on GPT-1, increasing both the number of parameters and the dataset size by 10 times. It can perform downstream tasks in zero-shot transfer settings—without any parameter or architectural modifications.
GPT-3 uses the same model and architecture as GPT-2, with the only difference being the use of alternating dense and locally banded sparse attention patterns in the Transformer layers.


Model size
On TriviaQA, GPT-3’s performance steadily increases with model size, indicating that language models absorb more knowledge as their capacity increases. The performance of one-shot and few-shot is significantly better than that of zero-shot.


Data Quality Issues
Although this has not been discussed much, data quality is equally important. The size of language model datasets has rapidly expanded; for example, the CommonCrawl dataset contains nearly 1 trillion words, which is sufficient to train the largest models without needing to update the same sequence twice. However, studies have found that the quality of unfiltered or lightly filtered CommonCrawl datasets is often inferior to more curated datasets.
To address this, GPT-2 created a new web crawler that crawls all outbound links on Reddit with at least 3 Karma to improve document quality, using it as a heuristic indicator to show whether other users are genuinely interested in the link or just for fun. After deduplication and some heuristic-based cleaning, the final dataset contains slightly more than 8 million documents, totaling 40 GB of text.
Additionally, GPT-3 takes three steps to improve the average quality of the dataset: (1) filtering CommonCrawl based on similarity to a set of high-quality reference corpora, (2) performing fuzzy deduplication at the document level internally and across datasets to prevent redundant datasets and maintain the integrity of the validation set as an accurate overfitting, and (3) adding known high-quality reference corpora for mixed training to increase the diversity of CommonCrawl.
Similarly, GLaM developed a text quality classifier that generates a high-quality web corpus from a larger raw corpus. This classifier is trained to classify a set of curated texts (Wikipedia, books, and some selected websites) and other webpages. GLaM uses this classifier to estimate the quality of web content and then samples webpages using a Pareto distribution to prevent systematic biases in the classifier, allowing for the inclusion of some lower-quality webpages.

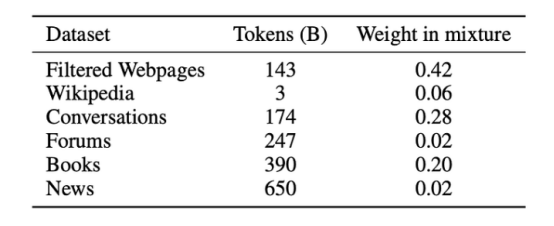
Data and composite weights in the GLaM training set
GLaM also set composite weights for each data in smaller models to prevent small data sources like Wikipedia from being over-sampled.
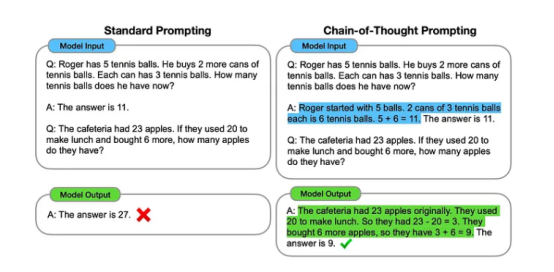
Chain of Thought
As mentioned earlier, different thought processes yield different predictions for the next token. Interestingly, the reasoning and arithmetic capabilities of LLMs can be unlocked through prompts for chain of thought. A chain of thought is a series of intermediate natural language reasoning steps leading to the final output result. If demonstrations of reasoning chains are provided in examples, a sufficiently large language model can generate a chain of thought: input, chain of thought, output. However, the exact workings of this are still not very clear.

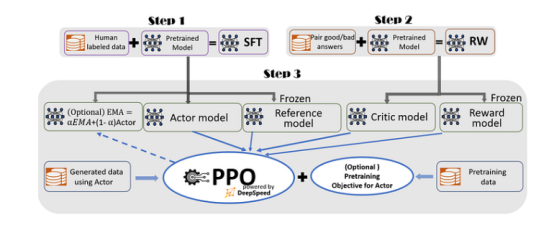
Reinforcement Learning from Human Feedback (RLHF)
The goal of modeling with LLMs is to predict the next token, which contradicts the goal of “beneficially and safely following user instructions,” thus creating inconsistencies in the objective of language modeling.
InstructGPT fine-tunes the language model using Reinforcement Learning from Human Feedback (RLHF) to align the language model with user intentions on general tasks. This technique utilizes human preferences as reward signals to fine-tune the model.
Step 1: Collect demonstration data and train a supervised policy. Labelers provide demonstrations of the desired behavior based on the distribution of input prompts, and then use supervised learning to fine-tune the GPT-3 model on this data.
Step 2: Collect comparison data and train a reward model. A comparison dataset is collected between model outputs, marking the preferred output for a given input. A reward model is then trained to predict the human-preferred output.
Step 3: Use PPO to optimize the policy for the reward model. The output of the RM is used as a scalar reward, and the PPO algorithm fine-tunes the supervised policy to optimize the reward.
Steps 2 and 3 can be iterated continuously; more comparison data is collected based on the current best policy to train a new RM, which is then used to train a new policy.

Instruction Fine-Tuning
Supervised fine-tuning introduced in GPT-1 focuses on adjustments for specific tasks, while T5 employs a maximum likelihood objective (using “teacher forcing”) for training, regardless of the task. Essentially, T5 leverages the same idea as zero-shot transfer (zero-shot transfer), where NLP tasks can be described using natural language instructions, such as “Is the sentiment of this movie review positive or negative?” or “Translate ‘How are you?’ into Chinese.” To specify which task the model should perform, T5 adds a task-related (text) prefix to the model before the original input sequence. Furthermore, FLAN also explores instruction fine-tuning, particularly focusing on (1) expanding the number of tasks, (2) increasing the model size, and (3) fine-tuning on chain of thought data.
For the dataset, FLAN manually composed 10 unique templates that use natural language instructions to describe the tasks in the dataset. While most templates describe the original tasks, FLAN also includes three additional templates for “twisting tasks” (for example, for sentiment classification, including a template asking to generate a movie review) to enrich the diversity of the templates. We then mixed all datasets and fine-tuned them into a pre-trained language model, formatting examples in each dataset according to randomly selected instruction templates.
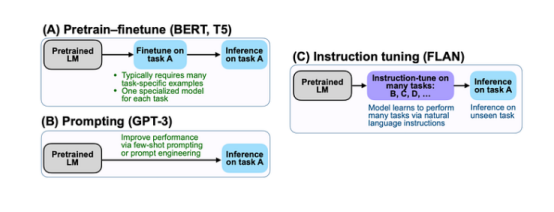

What is known as prompt engineering is essentially a form of reverse engineering, which is how to prepare training data for instruction fine-tuning and contextual learning.
Retrieval-Augmented Generation (RAG)
Due to cost and time reasons, using LLMs often lags in the freshness of training data. To address this issue, LLMs can be used in a retrieval-augmented generation (RAG) manner. In this example, we do not want LLMs to generate text solely based on the data they were trained on, but rather to incorporate other external data in some way. With RAG, LLMs can also answer (private) domain-specific questions. Thus, RAG can also be referred to as “open-book” question answering. LLM + RAG can be an alternative to classic search engines. In other words, it has the capability of information retrieval with hallucinated information.
Currently, the retrieval component of RAG is typically implemented on a vector embedding database containing external text data using k-nearest neighbor (similarity) search. For example, DPR defines the training of the encoder as a metric learning problem. However, it is worth noting that information retrieval is typically based on relevance, which differs from similarity. It is expected that there will be more improvements in this area in the future.
Conclusion
LLMs are an exciting field that is bound to experience rapid innovation. I hope this article helps in understanding how they work. Besides excitement, it should also be noted that LLMs learn language differently from humans—they lack the social and perceptual contexts that human language learners use to infer the relationship between language and speaker mental states, and they are trained in a way that differs from human thought processes, which may be an area for improving LLMs or inventing new learning algorithm paradigms.