Paper Information
Title: Efficient Vision Transformers with Partial Attention
Efficient Vision Transformers with Partial Attention
Authors: Xuan-Thuy Vo, Duy-Linh Nguyen, Adri Priadana, and Kang-Hyun Jo
Paper Link: https://eccv.ecva.net/virtual/2024/poster/1877
Innovations
- Novel Partial Attention Mechanism: The authors propose a new mechanism called Partial Attention, which enables the model to learn spatial interactions more efficiently by reducing redundant information in the attention map. Unlike traditional self-attention, Partial Attention allows each query to interact only with a small subset of relevant tokens, thereby reducing computational complexity.
- Efficient Vision Transformer Model PartialFormer: Based on Partial Attention, the authors propose an efficient and general vision transformer model called PartialFormer. This model significantly reduces computational costs while maintaining accuracy, achieving a good balance between accuracy and computational cost.
- Mixed Multi-Head Self-Attention (MMSA) and Single Query Attention (SQA): To further enhance efficiency, the authors design Mixed Multi-Head Self-Attention (MMSA) to handle foreground tokens and Single Query Attention (SQA) to handle background tokens.
- Efficient Information Exchange Mechanism: The authors introduce an efficient information exchange mechanism that adds a learnable abstract token as a query between the foreground and background sets, facilitating information exchange between the two groups.
Abstract
As the core of vision transformers (ViT), self-attention is highly flexible due to its ability to model long-range spatial interactions, as each query attends to all spatial locations. Despite ViT achieving promising performance in visual tasks, the complexity of self-attention scales quadratically with the length of tokens. This poses challenges when adapting ViT models to downstream tasks requiring high input resolutions. Previous work has addressed this issue by introducing sparse attention mechanisms, such as spatial reduction attention and window attention. A commonality among these methods is that all image/window tokens participate in computing attention weights. In this paper, the authors find a high similarity between attention weights, leading to computational redundancy. To solve this problem, the paper introduces a novel attention mechanism called Partial Attention, which learns spatial interactions more efficiently by reducing redundant information in the attention map. In our attention mechanism, each query interacts only with a small subset of relevant tokens. Based on Partial Attention, we propose an efficient and general vision transformer called PartialFormer, which achieves a good trade-off between accuracy and computational cost in visual tasks. For example, on ImageNet-1K, PartialFormer-B3 surpasses Swin-T by 1.7% in Top-1 accuracy while saving 25% in GFLOPs, and exceeds Focal-T by 0.8% while saving 30% in GFLOPs.
3 Partial Vision Transformer
3.1 Partial Transformer
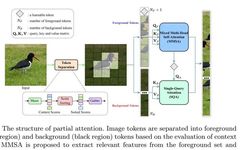
Partial Attention learns spatial interactions more efficiently by focusing on the foreground areas in the feature map and squeezing out most of the background token information. The design of Partial Attention is illustrated in Figure 4.
Token Separation
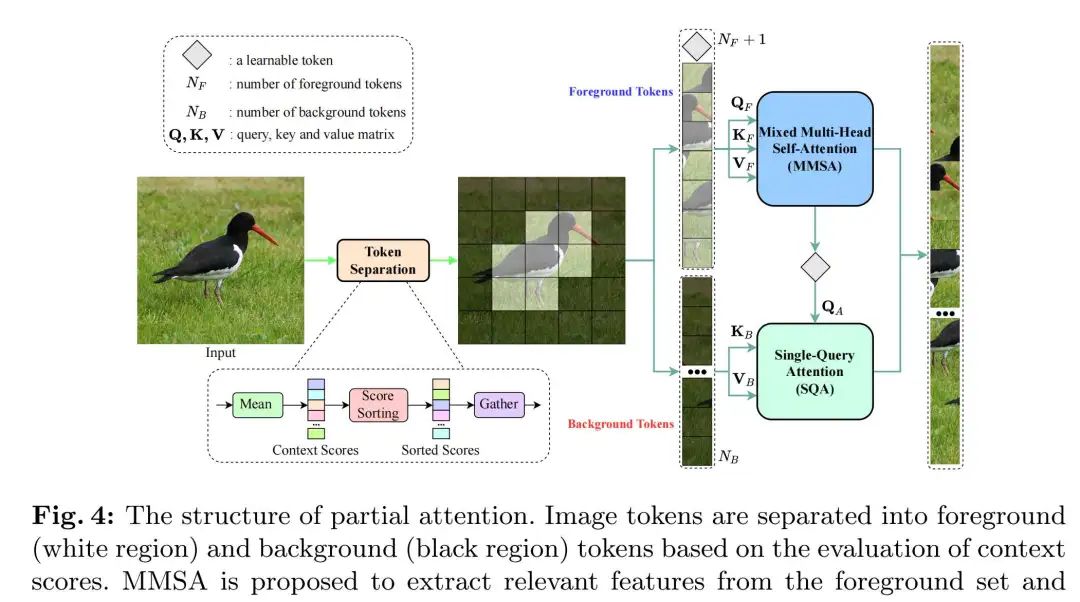
Given image tokens, the authors divide them into two groups: the foreground set and the background set. To achieve this, the authors evaluate context scoring for the input tokens. This is determined by creating spatial vectors using the Mean() operation along the channel dimension. The authors then sort the values of the context vector in descending order and store the sorted indices in a vector. Intuitively, the tokens and correspond to the most relevant and least important tokens, respectively. Therefore, based on the sorted vector, the authors collect the input tokens along the token dimension. In short, these processes are as follows:Where is the collected image token. The index vector is repeated along the channel dimension to maintain consistency of the collected information. By determining the collected image tokens, the authors directly separate them into foreground tokens and background tokens, where is the number of foreground and background tokens. The foreground set contains relevant tokens, and the background set contains less important tokens. Since most tokens contain background information, setting allows the input of foreground tokens into the global MSA to incur negligible costs while directly capturing relevant information in the foreground set. For the background set, a potential token interacting with the background tokens can encode the necessary information for that set, resulting in linear complexity. This is achieved through the authors’ Single Query Attention (SQA).
Mixed Multi-Head Self-Attention
After obtaining the foreground set, MSA is applied to capture global information among relevant tokens. To promote diversity among attention heads, this paper introduces Mixed Multi-Head Self-Attention (MMSA), which mixes head information at a higher dimension, modifying it to be smaller compared to MSA:Where is the foreground attention weight. is the foreground query and key. HeadMLP is the MLP Mixer applied between heads, consisting of two fully connected (FC) layers with an expansion ratio, with Softmax() inserted between the two FC layers. Thanks to HeadMLP, dependencies across attention heads are obtained. Finally, the mixed attention weights and values are aggregated through matrix multiplication, and all heads are connected and linearly projected to create the final output. The detailed architecture is shown in Figure 5(a).
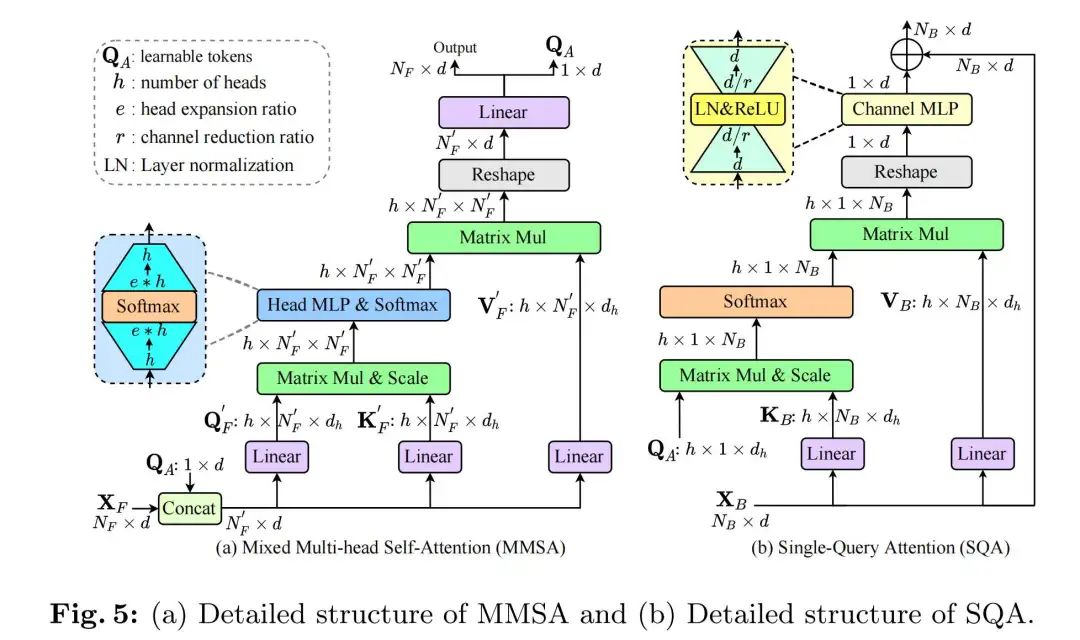
The core idea of MMSA is to directly split the set of image tokens into two groups: the foreground set and the background set, based on the evaluation of context scores. The foreground tokens are then fed into MMSA to learn relevant features, while the attention heads of the foreground set are mixed through a simple head MLP to increase the diversity of attention heads. Thus, the foreground queries focus only on important areas, allowing the model to capture informative features at a lower cost, as the number of foreground tokens is much smaller than the total number of image tokens. This modification of MSA is called Mixed Multi-Head Self-Attention (MMSA). For background tokens, since they contain less information, the authors introduce an efficient Single Query Attention (SQA), which forces a unique query to focus on the background set. SQA only incurs linear complexity with respect to the length of background tokens. Thus, a significant amount of computational cost is cut while still retaining the capability of ViT to model global interactions.
Single Query Attention
Due to the large number of tokens in the background set containing less important information, Single Query Attention (SQA) is proposed to efficiently capture attention among tokens. The detailed structure is illustrated in Figure 5(b). Formally, given background tokens, SQA is defined as:Where is the single query. is the background key and value tokens. Note that the weights in share with the MMSA branch to reduce costs. is the attention weight generated by a unique query focusing on the background set. Clearly, SQA still encodes all information of the background tokens while enjoying the benefit of linear complexity. This information is propagated to the values to generate features. In this paper, ChannelMLP is used instead of linear projection, where ChannelMLP consists of two FC layers with channel reduction and layer normalization + ReLU inserted between the two FC layers to stabilize training. The fused output is achieved through broadcasting element-wise addition between and the input.
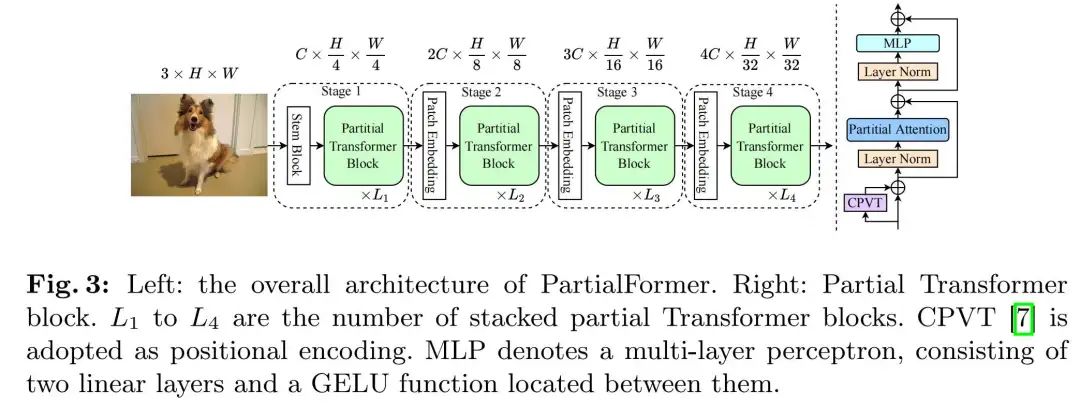
3.2 PartialFormer Model Configuration
Similar to the meta-design in ViT[13], the Partial Transformer block is illustrated in Figure 3. CPVT[7] is used for positional encoding[6, 12, 16, 35, 52] to learn local features and preserve the geometric information of 2D images. Based on the obtained blocks, we propose the PartialFormer model, which is efficient and general for vision transformers. As shown in Figure 3, the model consists of four stages, where the spatial dimensions are downsampled through convolution-based patch embeddings at ratios of {4, 8, 16, 32}. As the spatial dimensions are reduced, the number of channels doubles across the four stages to {C, 2C, 3C, 4C}. Global average pooling and classifier layers are used to predict class logits. Table 1 lists five models (B0-B4) with varying stack block counts Li (i ∈ {1, 2, 3, 4}) and base channels C. The model costs range from 0.4 GFLOPs to 6.8 GFLOPs.

4 Experiments and Results

Statement
The content of this article is a sharing of learning outcomes from the paper. Due to limitations in knowledge and capability, the understanding of the original text may have deviations, and the final content is subject to the original paper. The information in this article aims to disseminate and facilitate academic exchange, and its content is the responsibility of the authors, not representing the views of this account. If there are any issues regarding the text, images, or other content in this article, please contact the authors, and they will respond and address them promptly.
