
MLNLP community is a well-known machine learning and natural language processing community in China and abroad, covering NLP master’s and doctoral students, university teachers, and corporate researchers.The community’s vision is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning in China and abroad, especially for beginners. Reprinted from | Jishi Platform Author | Technology Beast1
Background and Motivation
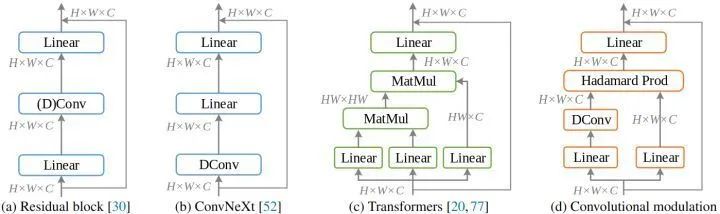
Convolutional neural networks (ConvNets) represented by VGGNet, Inception series, and ResNet series have made great strides in various visual tasks from 2010 to 2020. Their common feature is the sequential stacking of multiple basic modules (Basic Building Block) and the use of pyramid network architecture, but they neglect the importance of explicitly modeling global contextual information. The SENet module series models break through the traditional CNN design ideas by introducing the attention mechanism into CNNs to capture long-range dependencies, achieving better performance. Since 2020, visual Transformers (ViTs) have further promoted the development of visual recognition models, showing better results than state-of-the-art ConvNets in ImageNet image classification and downstream tasks. This is because the self-attention mechanism in Transformers can model global pairwise dependencies, providing a more effective spatial information encoding method compared to convolution operations that only perform local modeling. However, the computational cost caused by the self-attention mechanism is considerable when processing high-resolution images. To address this issue, some classic works in 2022 attempted to answer: How to leverage convolution operations to create a Transformer-style convolutional network visual baseline model? For example, ConvNeXt[1]: modernizing the standard ResNet architecture and using design and training strategies similar to Transformers, ConvNeXt can outperform some Transformers. A detailed explanation of FAIR’s stunning work last year: the brand new pure convolution model ConvNeXt Another example is HorNet[2]: by modeling higher-order interactions, pure convolution models can achieve second-order or even higher interactions like Transformers. Accuracy surpassing the new CNN beyond ConvNeXt! HorNet: Achieving efficient high-order spatial information interaction through recursive gated convolutions. Another example is RepLKNet[3], SLaK[4]: through convolutions with large kernels of 31×31 or 51×51, pure convolution models can model longer distances. Another attack on ConvNets! A detailed explanation of SLaK: extending convolution kernels to 51×51 from the perspective of sparsity. So far, how to more effectively use convolution to build powerful ConvNet architectures remains a hot research topic.2
Convolution Modulation Module
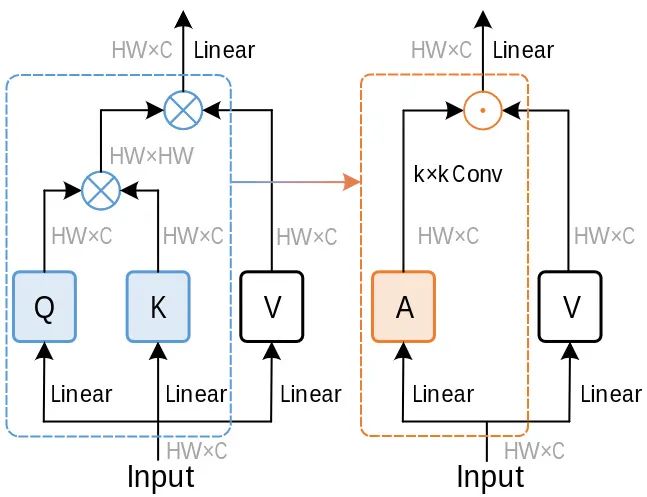
The key to this paper is the convolution modulation module introduced in this section. As shown in Figure 1, for traditional Self-attention, given an input sequence of length N, the self-attention module first obtains the key, query, and value through a linear layer, where C is the number of channels, and H and W are the spatial sizes of the input. The output is the attention matrix (essentially the similarity score matrix):

In this equation, the relationship between each pair of input tokens is measured, and can be written as:

For simplicity, the scale factor is omitted here. The computational complexity of the self-attention module increases quadratically with the sequence length N, resulting in higher computational costs. In the convolution modulation module, the similarity score matrix is not calculated through Equation 2. Specifically, given the input X, the author uses a depth-wise convolution of size K and the Hadamard product to compute the output:
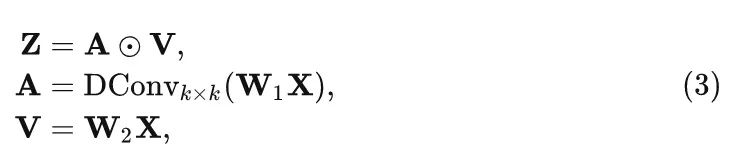
In this equation, ⊙ is the Hadamard product, and θ1 and θ2 are the parameters of the two linear layers. The above convolution modulation operation relates each spatial position X with all pixels in a square region centered at X, and the information exchange between channels can be achieved through linear layers. The output for each spatial position is the weighted sum of all pixels within the square region.Advantages: The convolution modulation module utilizes convolution to establish relationships, which is more efficient than the attention mechanism when processing high-resolution images.
ConvNeXt shows that increasing the kernel size of ConvNets from 3 to 7 can improve classification performance. However, further increasing the kernel size provides little performance improvement and adds computational burden without re-parameterization. The authors believe that the reason ConvNeXt benefits little from kernels larger than 7×7 is due to the use of spatial convolution. For Conv2Former, when the kernel size increases from 5×5 to 21×21, consistent performance improvements can be observed. This phenomenon occurs not only in Conv2Former-T (82.8→83.4) but also in the parameterized Conv2Former-B (84.1→84.5) with 80M+ parameters. Considering model efficiency, the default kernel size can be set to 11×11.
Optimization of Weight Strategy: Note that the authors directly use the output of depth convolution as weights to modulate the features after linear projection. There is no activation layer or normalization layer (e.g., Sigmoid or LN layer) used before the Hadamard product; adding a Sigmoid function like in the SE module would reduce performance by more than 0.5%.3
Overall Architecture of Conv2Former
As shown in Figure 3, similar to ConvNeXt and Swin Transformer, the author’s Conv2Former also adopts a pyramid architecture. There are a total of 4 stages, with the feature resolution decreasing sequentially at each stage. Based on model size, five variants are designed: Conv2Former-N, Conv2Former-T, Conv2Former-S, Conv2Former-B, and Conv2Former-L.
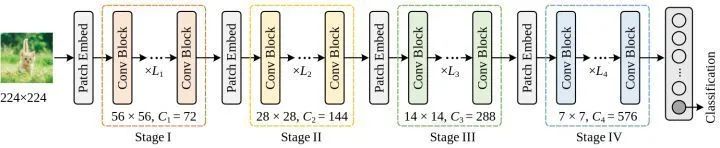
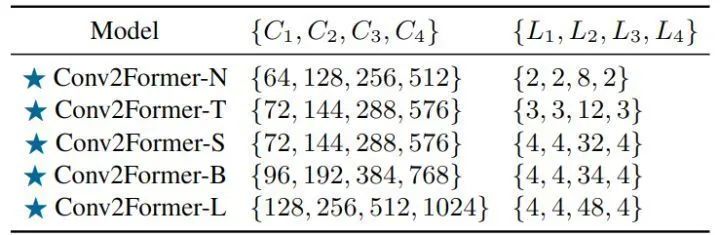
When the number of learnable parameters is fixed, how to arrange the width and depth of the network affects model performance. The original ResNet-50 sets the number of blocks for each stage to (3,4,6,3). ConvNeXt-T changes the block number ratio to (3,3,9,3) following the pattern of Swin-T, and for larger models, it changes the block number ratio to (1,1,9,1). The settings for Conv2Former are shown in Figure 4. It can be observed that for a small model (with less than 30M parameters), deeper networks perform better.
4
Experimental Results
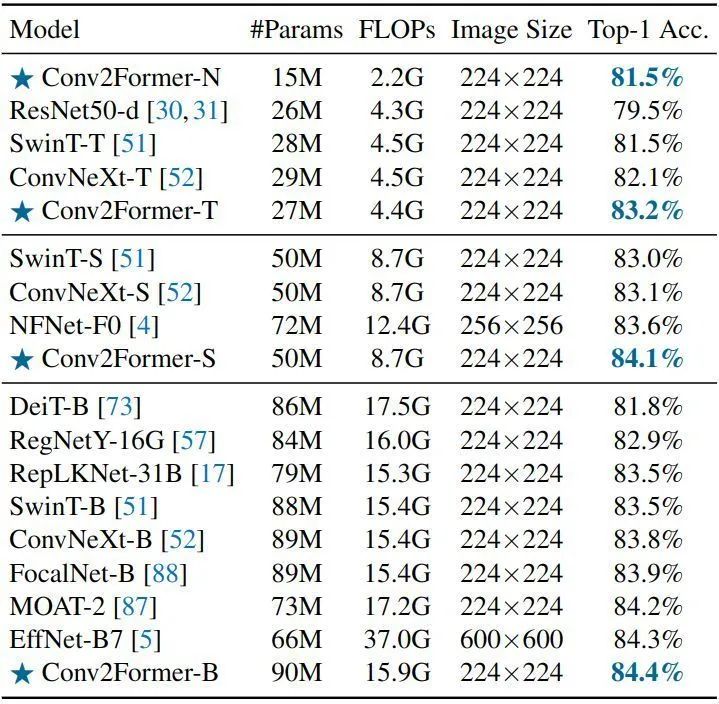
ImageNet-1K experiments are divided into two types, one is training and validating directly on ImageNet-1K, and the other is pre-training on ImageNet-22K followed by fine-tuning and validating on ImageNet-1K.ImageNet-1K Experiment SettingsDataset: ImageNet-1K training for 300 epochs, ImageNet-1K validation.Optimizer: AdamW, lr, batch_size: 1024, weight decay, data augmentation: MixUp, CutMix, Stochastic Depth, Random Erasing, Label Smoothing, RandAug.ImageNet-22K Experiment SettingsDataset: ImageNet-22K pre-training for 90 epochs, ImageNet-1K fine-tuning for 30 epochs, ImageNet-1K validation.As shown in Figure 5, the results of the ImageNet-1K experiment show that for small models (< 30M), Conv2Former has performance improvements of 1.1% and 1.7% compared to ConvNeXt-T and Swin-T, respectively. Even Conv2Former-N, with only 15M parameters and 2.2G FLOPs, performs similarly to SwinT-T, which has 28M parameters and 4.5G FLOPs. For other popular models, Conv2Former also performs better than models of similar sizes. Conv2Former-B even outperforms EfficientNetB7 (84.4% vs. 84.3%), which has twice the computational load of Conv2Former (37G vs. 15G).
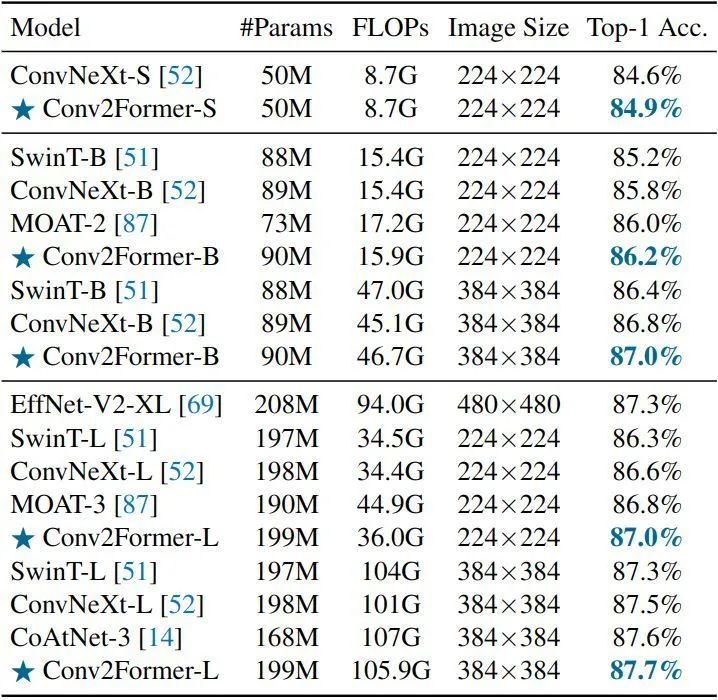
As shown in Figure 6, the results of the ImageNet-22K experiment show that the authors followed the settings used in ConvNeXt to train and fine-tune the models. Compared to different variants of ConvNeXt, Conv2Former consistently performs better when the model sizes are similar. Additionally, we can see that when fine-tuning at a larger resolution of 384×384, Conv2Former-L achieves better results than hybrid models (such as CoAtNet and MOAT), reaching a best result of 87.7%.
As shown in Figure 8, the results of the ablation experiment regarding kernel size indicate that the performance gain seems to saturate before the size increases to 21 × 21. This result contrasts sharply with the conclusion drawn by ConvNeXt, which found that using kernels larger than 7×7 does not yield significant performance improvements.
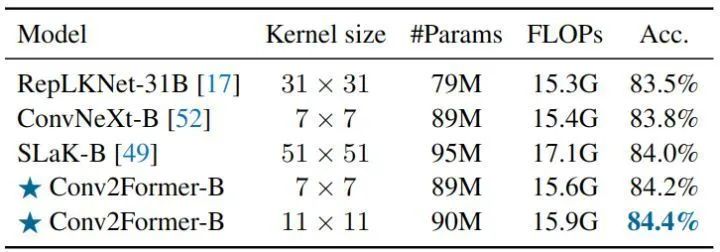
Ablation Experiment 1: Kernel SizeAs shown in Figure 8, the results of the ablation experiment regarding kernel size indicate that the performance gain has saturated before the kernel size increases to 21 × 21. This result contrasts sharply with the conclusion drawn by ConvNeXt, which found that using kernels larger than 7×7 does not yield significant performance improvements. This indicates that Conv2Former’s approach can utilize the advantages of large kernels more effectively than traditional methods.
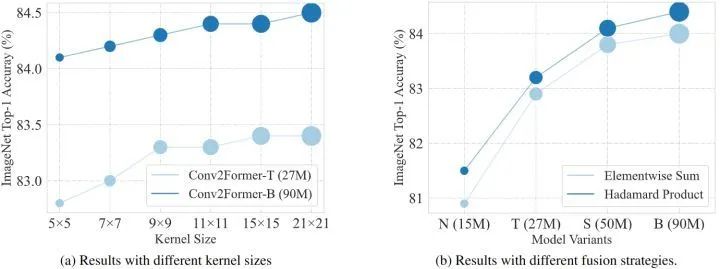
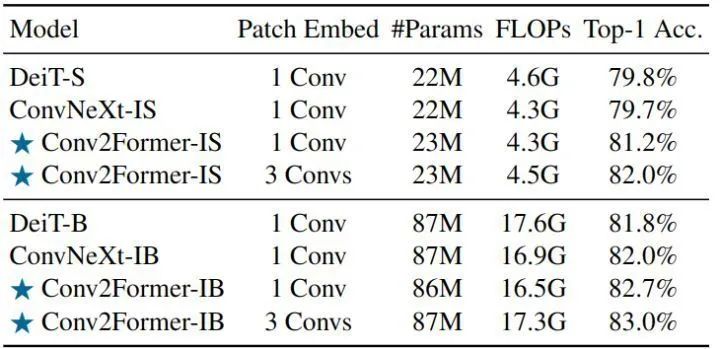
Ablation Experiment 2: Impact of Different Fusion StrategiesAs shown in Figures 8 and 9, the results of the ablation experiment regarding the impact of different fusion strategies indicate that besides the two aforementioned fusion strategies, the authors also tried other methods to fuse feature maps, including adding a Sigmoid function after the Hadamard product, normalizing the values of X, and linearly normalizing the values of X to (0,1]. It can be seen that the Hadamard product yields better results than other operations. The authors found that using a Sigmoid function or linearly normalizing the values of X would harm performance.Results of Isotropic Architecture ExperimentFollowing ConvNeXt’s approach, the authors also trained the isotropic architecture (Isotropic Models) version of Conv2Former, with results shown in Figure 9. The authors set the number of blocks for Conv2Former-IS and Conv2Former-IB to 18 and adjusted the number of channels to match the model size. The letter “I” indicates isotropic architecture, and it can be seen that for small models with around 22M parameters, Conv2Former-IS significantly outperforms DeiT-S. When the model size is increased to 80M+, Conv2Former-IB achieved a Top-1 Accuracy of 82.7%, which is also 0.7% higher than ConvNeXt-IB and 0.9% higher than DeiT-B.
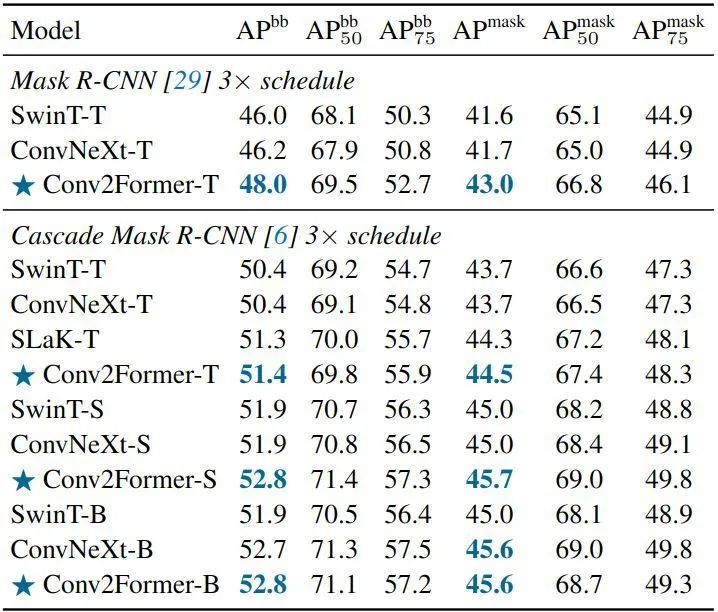
Object Detection Experiment ResultsAs shown in Figure 10, the results of the experiments on the COCO dataset using different backbone networks, with Mask R-CNN as the detection head and Cascade Mask R-CNN as the instance segmentation head, follow the training strategy of ConvNeXt. For small models, using the Mask R-CNN framework, Conv2Former-T achieved about 2% AP improvement over SwinT-T and ConvNeXt-T.
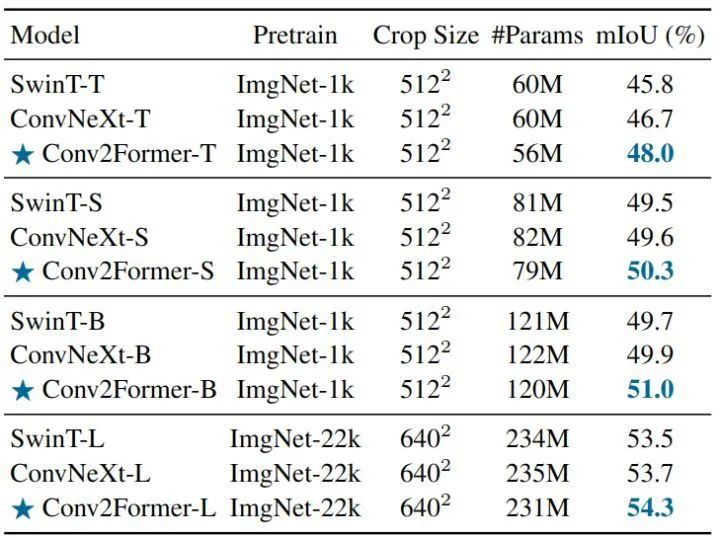
Semantic Segmentation Experiment ResultsAs shown in Figure 11, the results of the experiments using different backbone networks, with UperNet as the segmentation head on ADE20k, show that our Conv2Former outperforms both Swin Transformer and ConvNeXt across different scales of models.
5
Conclusion
This paper attempts to answer: How to leverage convolution operations to create a Transformer-style convolutional network visual baseline model. This paper proposes a convolution modulation module that utilizes convolution to establish relationships, which is more efficient than the attention mechanism when processing high-resolution images. The final model is called Conv2Former, which simplifies the attention mechanism by using only convolution and the Hadamard product. The convolution modulation operation is a more effective way to leverage the advantages of large kernel convolutions. The authors’ experiments in ImageNet classification, object detection, and semantic segmentation also indicate that Conv2Former outperforms previous CNN-based models and most Transformer-based models.