PanChuang AI Share
Source | Extreme City Platform
Author | whistle@Zhihu
Source | https://zhuanlan.zhihu.com/p/536489997
Reprinted from | Machine Learning Algorithms and Natural Language Processing
Introduction
Why Use Transformers on Graphs?
Briefly mention the benefits brought by Graph Transformers (GT):
- Can capture long-range dependencies
- Mitigates over-smoothing and over-squashing phenomena
- GT can even integrate GNN and frequency domain information (Laplacian PE), leading to stronger model expressiveness.
- Utilizes the [CLS] token effectively, no need for additional pooling functions.
- etc…
Article Summary
[Arxiv 2020] GRAPH-BERT: Only Attention is Needed for Learning Graph Representations
GNN overly relies on links in the graph, and due to the high memory consumption of large graphs, direct operations may not be feasible. This paper proposes a new graph network called Graph-BERT, which relies solely on the attention mechanism. The input to Graph-BERT is not the entire graph, but a collection of sampled subgraphs (without edges). The authors used two tasks, node attribute reconstruction and structure recovery, for pre-training, followed by fine-tuning on downstream datasets. This method achieved SOTA in node classification and graph clustering tasks.
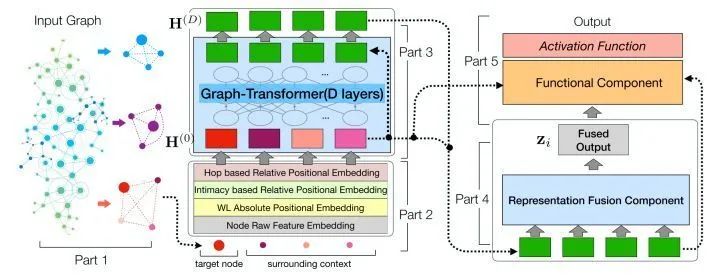
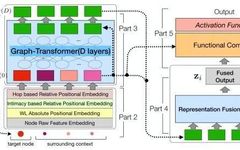
Unlike the previous BERT in NLP, the main difference lies in the position encoding. Graph-BERT uses three types of PE: WL absolute PE, intimacy-based relative PE, and Hop-based relative PE, all calculated based on the complete graph.
To facilitate operations, the authors sorted the subgraphs based on the graph intimacy matrix (https://zhuanlan.zhihu.com/p/272754714) to obtain a serialized result [i, j, …m], where S(i,j) > S(i,m).
The Weisfeiler-Lehman Absolute Role Embedding is as follows:
After WL, nodes with the same substructure will receive the same hash code. The 1-WL is somewhat like degree centrality (for undirected graphs). Therefore, WL PE can capture global node role information.Intimacy-based Relative Positional EmbeddingThis PE captures local information because the input has been sorted based on the graph intimacy matrix. Here, we only need to set a simple mapping, where nodes closer to i will have smaller values. The mapping formula is as follows:Hop-based Relative Distance EmbeddingThis PE captures information that lies between global and local:By adding node embeddings with these PEs, each node’s representation in the subgraph is obtained through the Transformer. Since there are many nodes in the subgraph, the authors aim to only obtain the representation of the target node, thus they designed a Fusion function, which averages all node representations in the original text. Outputs will be selected based on downstream tasks.Node Classification Effectiveness (No Pre-training Conducted)
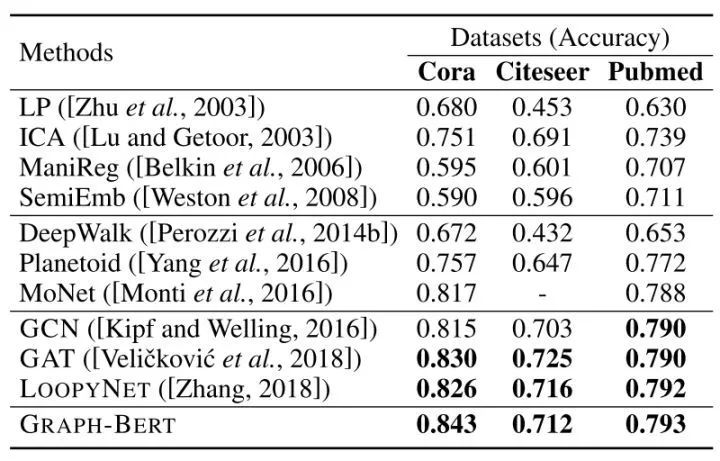
Overall, the novelty of this paper lies in proposing multiple PEs on graphs, and the effectiveness on subgraphs can reach the level of previous GNNs on the entire graph. However, the datasets used for experiments were too small, and no larger graph datasets were utilized, which did not showcase the pre-training effect well. Additionally, the sampled subgraphs only calculated loss based on the target node, leading to inefficient utilization and low inference efficiency.
[NIPS 2020] (GROVER) Self-Supervised Graph Transformer on Large-Scale Molecular Data
GNNs have been widely studied in the molecular domain, but there are two main issues: (1) there isn’t enough labeled data, and (2) they exhibit poor generalization on newly synthesized molecules. To address these two problems, this paper designs self-supervised tasks at the node, edge, and graph levels, hoping to capture rich semantic and structural information from large amounts of unlabeled data. The authors trained a GNN with 100M parameters on ten million unlabeled molecular graphs, followed by fine-tuning on eleven datasets, achieving SOTA (an average improvement of over 6 points).The model structure is as follows:
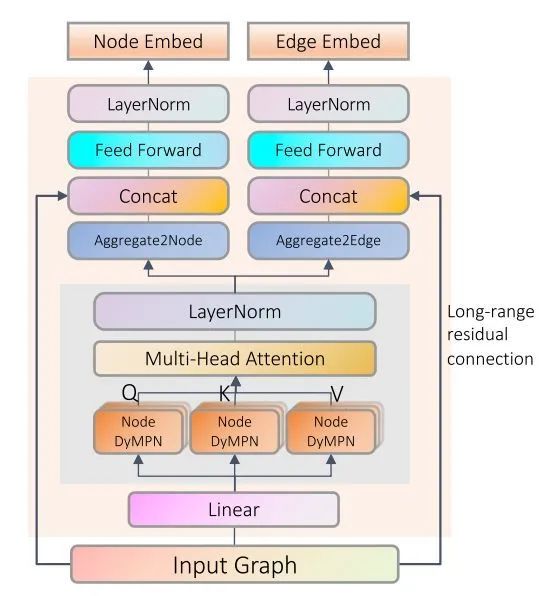
Because the message passing process can capture local structural information in the graph, the data is first passed through the GNN to obtain Q, K, and V, which allows each node representation to gain information about the local subgraph structure. Then, these representations can capture global information through self-attention. To prevent over-smoothing in message passing, the paper converts residual connections into long-range residual connections, directly linking the original features to the end.Furthermore, since the number of GNN layers directly affects the receptive field, it impacts the generalization of the message passing model. Different types of datasets may require different GNN layer counts, and pre-defining the number of GNN layers may affect model performance. During training, the authors randomly selected the number of layers and the number of hops in MPNN, where either or . This MPNN is termed Dynamic Message Passing Networks (dyMPN), and experiments demonstrate that this structure performs better than ordinary MPNN.Pre-training:The self-supervised tasks used in the paper mainly include two:(1) Contextual Property Prediction (Node/Edge Level Task)
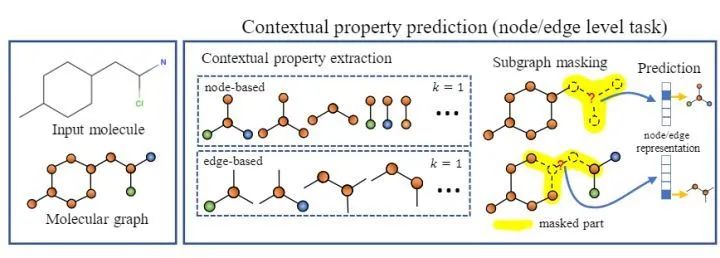
A good node-level self-supervised task should meet two properties:
- The prediction target is credible and easily obtainable.
- The prediction target should reflect the contextual information of nodes or edges. Based on these properties, the authors designed self-supervised tasks based on nodes and edges (predicting contextual properties of target nodes/edges through subgraphs).
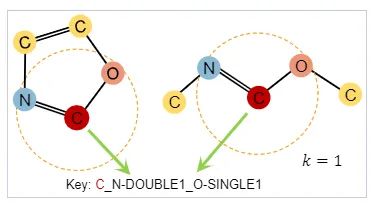
For example, given a target node C atom, we first obtain its k-hop neighbors as a subgraph. When k=1, N and O atoms will be included along with single and double bonds. Then we extract statistical features from this subgraph, counting the co-occurrence frequency of node-edge pairs for the center node, represented as node-edge-counts. All node-edge counts terms are sorted alphabetically; in this example, we can obtain C_N-DOUBLE1_O-SINGLE1. This step can be seen as a clustering process: based on the extracted features, subgraphs can be clustered together, where one feature (property) corresponds to a cluster of subgraphs with the same statistical attributes.Through this context-aware property definition, the global property prediction task can be divided into the following process:Input a molecular graph, and through the GROVER encoder, we can obtain embeddings for atoms and edges, randomly selecting an atom (its embedding being ). We do not predict the class of atom , but hope to encode some contextual information around node , achieving this by inputting into a very simple model (a single fully connected layer), then using its output to predict the contextual properties of node . This prediction is a multi-class classification (one class corresponds to one contextual property).(2) Graph-Level Motif Prediction
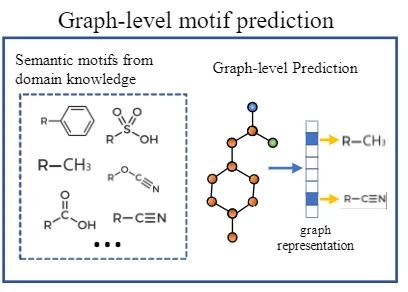
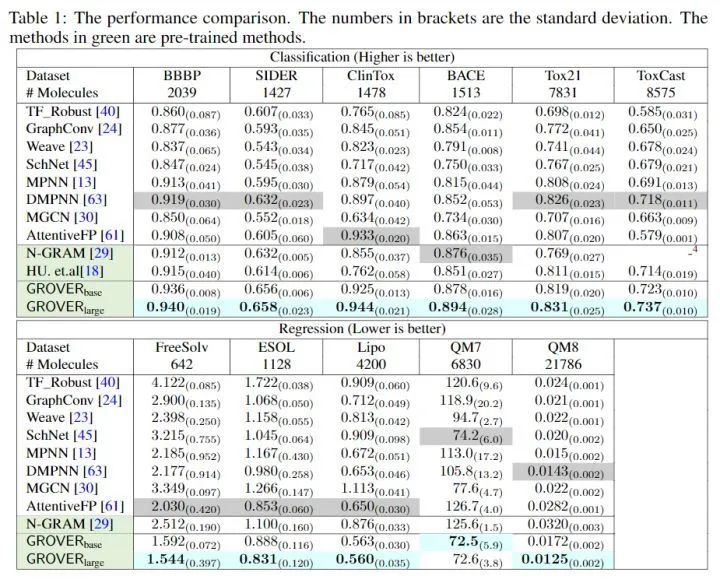
Graph-level self-supervised tasks also require credible and inexpensive labels, motifs are frequently occurring subgraphs in input graph data. One important type of motif is functional groups, which encode rich domain knowledge of molecules and can be detected by specialized software (e.g., RDKit). Therefore, we can formulate the motif prediction task as a multi-class problem, where each motif corresponds to a label. Assuming there are p motifs in the molecular dataset, for a specific molecule, we use RDKit to detect whether the motif appears in that molecule, then construct it as the target for the motif prediction task.Fine-tuning for Downstream Tasks:After completing pre-training on a vast amount of unlabeled data, we obtained a high-quality molecular encoder. For specific downstream tasks (e.g., node classification, link prediction, property prediction for molecules, etc.), we need to fine-tune the model. For graph-level downstream tasks, we also need an additional readout function to obtain the representation of the entire graph (node-level and edge-level tasks do not require a readout function), followed by an MLP for classification.Experiments:Note: Green indicates pre-training was conductedThe performance improvement is quite noticeable.
[AAAI 2020 Workshop] (GT) A Generalization of Transformer Networks to Graphs
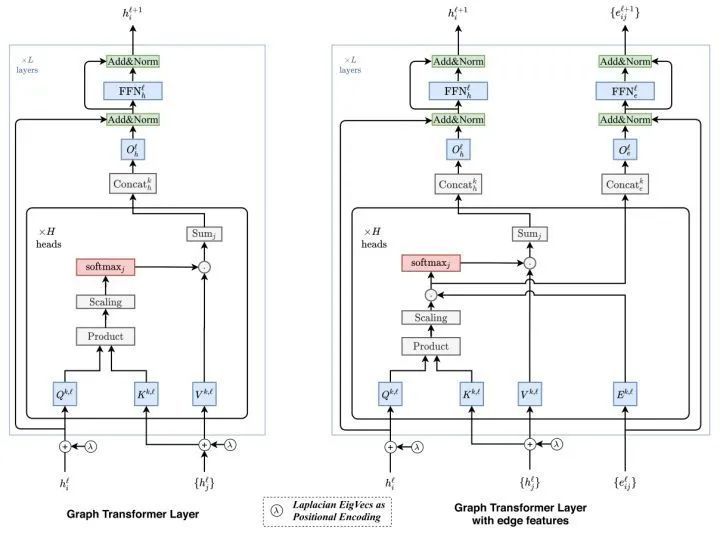
This primarily proposes using Laplacian eigenvectors as PE, which is better than the PE used in GraphBERT.
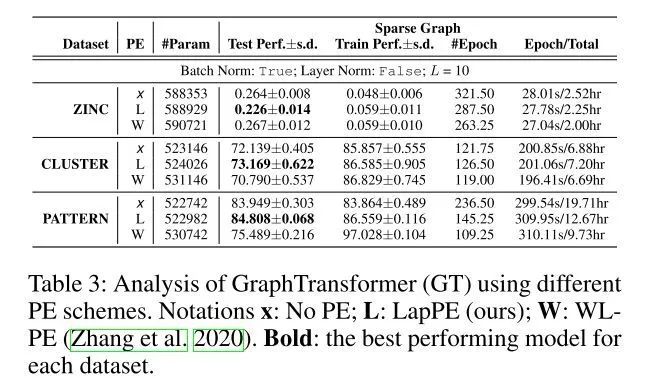
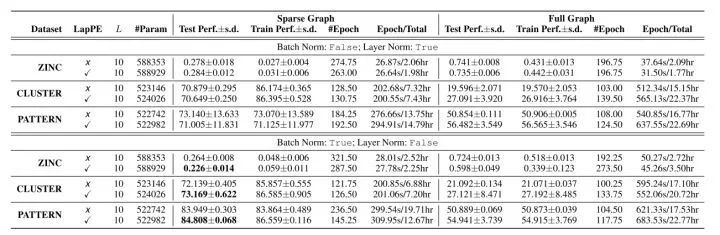
However, the model performs better when self-attention focuses only on neighbors. Rather than being a graph transformer, it is more like a GAT with PE. Sparse graph refers to self-attention calculating only neighbor nodes, while full graph means self-attention considers all nodes in the graph.
[Arxiv 2021] GraphiT: Encoding Graph Structure in Transformers
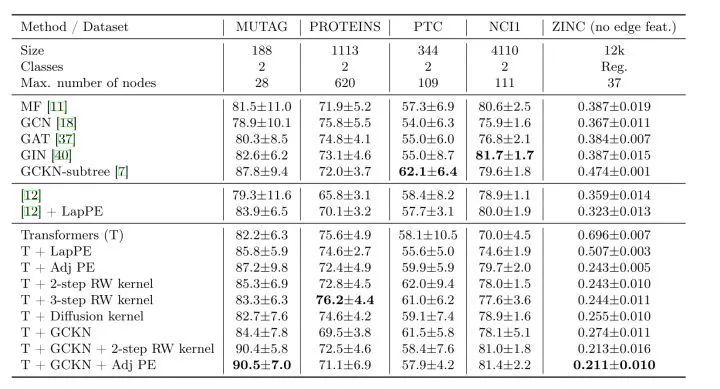
This work shows that merging structural and positional information into transformers can outperform existing classical GNNs.GraphiT: (1) uses relative position encoding based on kernel functions on graphs to influence attention scores, and (2) encodes local sub-structures for utilization. The implementation found that whether used alone or in combination, it achieved good results.
(i) leveraging relative positional encoding strategies in self-attention scores based on positive definite kernels on graphs, and (ii) enumerating and encoding local sub-structures such as paths of short length
Previously, GT found that self-attention performs well when focusing only on neighboring nodes, but not when considering all nodes. This paper discovered that transformers with global communication can also achieve good results.Thus, GraphiT encodes local graph structure into the model through some strategies: (1) relative position encoding strategies weighted by attention scores based on positive definite kernels, and (2) encoding small sub-structures (e.g., paths or subtree patterns) as transformer inputs through graph convolution kernel networks (GCKN).Transformer ArchitecturesEncoding Node PositionsRelative Position Encoding Strategies by Using Kernels on GraphsEncoding Topological StructuresGraph Convolutional Kernel Networks (GCKN)Experimental Results
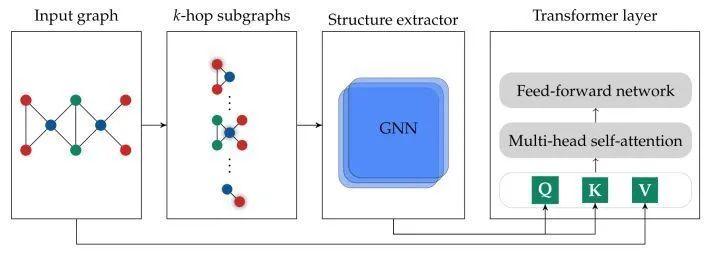
[NIPS 2021] (GraphTrans) Representing Long-Range Context for Graph Neural Networks with Global Attention
This paper proposes GraphTrans, adding transformers on top of standard GNN layers. It introduces a new readout mechanism (essentially the [CLS] token in NLP). For graphs, the aggregation for the target node should ideally be permutation-invariant, but adding PE in transformers may not achieve this, hence not using PE on graphs is more natural.
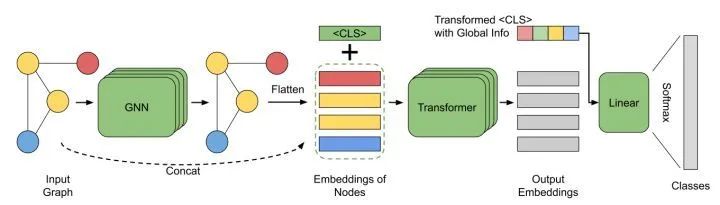
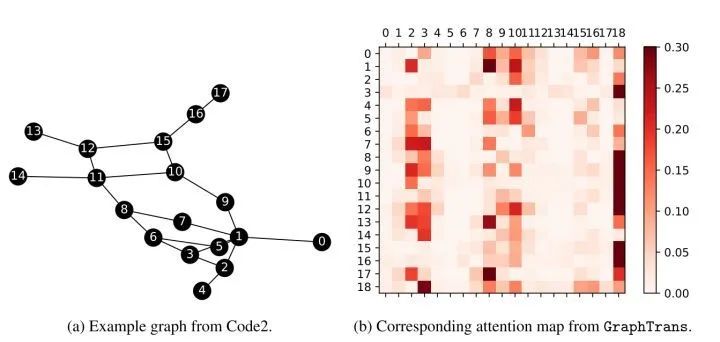
Interpretability ObservationThe [CLS] token is 18, and it can be seen that it interacts frequently with other nodes. It may extract more general information.
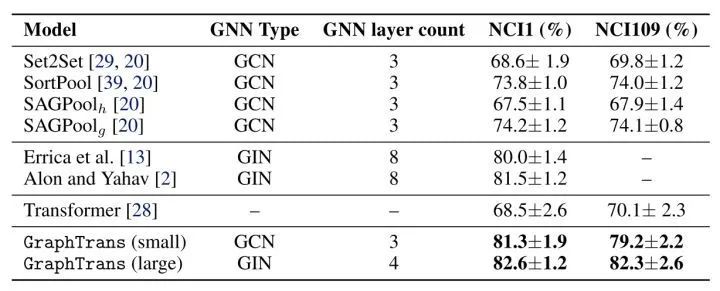
Although the method in this paper is simple, extensive experiments were conducted, and the results were good.NCI Biological Datasets
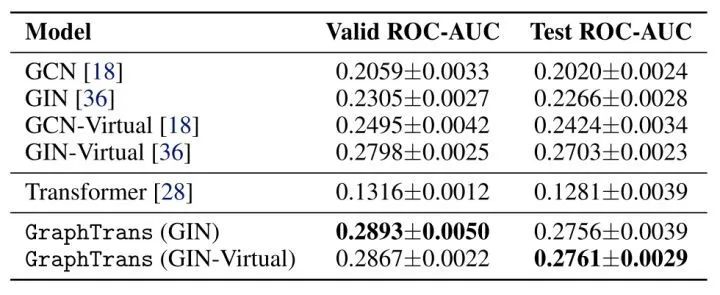
OpenGraphBenchmark Molpcba Dataset
OpenGraphBenchmark Code2 Dataset
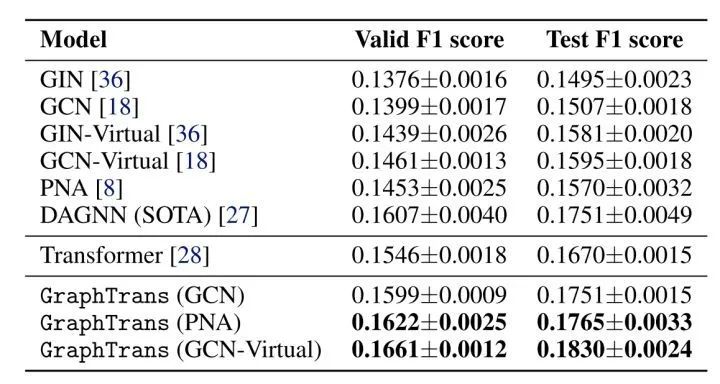
[NIPS 2021] (SAN) Rethinking Graph Transformers with Spectral Attention
This paper uses learnable PE and provides a good explanation of why Laplacian PE is effective.
[NIPS 2021] (Graphormer) Do Transformers Really Perform Bad for Graph Representation?
The original authors conducted an interpretation (https://www.msra.cn/zh-cn/news/features/ogb-lsc):The core point is to utilize structural information to correct the attention score, thus better leveraging the graph’s structural information.
[ICML 2022] (SAT) Structure-Aware Transformer for Graph Representation Learning
This paper is quite similar to GraphTrans. It also first obtains new node representations through GNN, then inputs them into GT. However, this paper provides a more abstract definition of how to extract structural information (but for convenience, still uses GNN). Another difference is that this paper also uses PE (RWPE).
In this paper, the authors demonstrate that the node representations generated by transformers using positional encoding do not necessarily capture the structural similarity between nodes. To address this issue, Chen et al. propose a structure-aware transformer, which is a transformer based on a new self-attention mechanism. This new self-attention extracts subgraph representations (rooted at each node) before calculating attention, thus integrating structural information. The authors propose several methods to automatically generate subgraph representations, theoretically proving that these representations are at least as expressive as subgraph representations.This structure-aware framework can utilize existing GNNs to extract subgraph representations and has been experimentally proven to significantly enhance model performance, closely related to GNNs. Using only absolute position encoding for transformers exhibits overly loose structural inductive bias, which cannot guarantee that nodes with similar local structures generate similar node representations.
[NIPS 2022 Under Review] (GraphGPS) Recipe for a General, Powerful, Scalable Graph Transformer
In this paper, the authors meticulously classify the PEs used previously (local, global, or relative, see the table below). Additionally, this paper proposes three elements for constructing a General, Powerful, Scalable Graph Transformer:
- positional/structural encoding,
- local message-passing mechanism,
- global attention mechanism.
Concerning these three elements, the authors designed a new graph transformer.

For layer design, this paper adopts GPSlayer = a hybrid MPNN+Transformer layer.
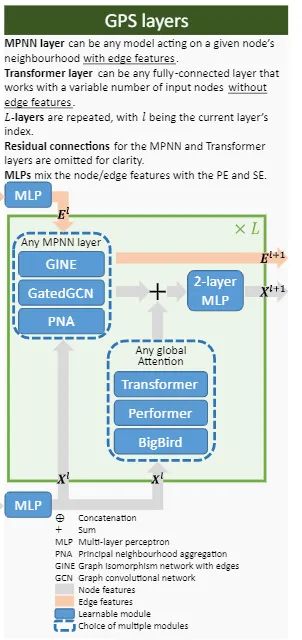
This design differs from GraphTrans, where the input is first fed into several layers of MPNNs before being input into the transformer, which may lead to over-smoothing, over-squashing, and low expressivity against the WL test issues. This means that these layers may fail to retain some information early on, resulting in missing information input into the transformer. The GPS design has each layer as an MPNN+transformer layer, then stacks L layers repeatedly.The specific computation is as follows:Using Linear transformer, GPS can reduce time complexity to .Experimental Results
- Using different Transformers, MPNN: It can be observed that not using MPNN results in a significant drop in performance, while using Transformers can enhance performance.
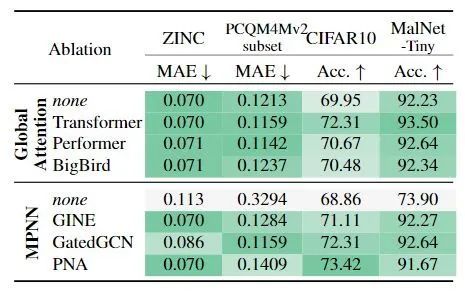
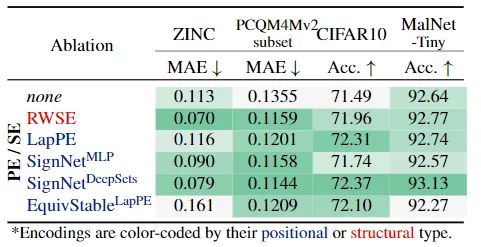
- Using different PE/SE: At low computation costs, using RWSE yields the best results. If computation overhead is not a concern, the better-performing can be used.
- Benchmarking GPS
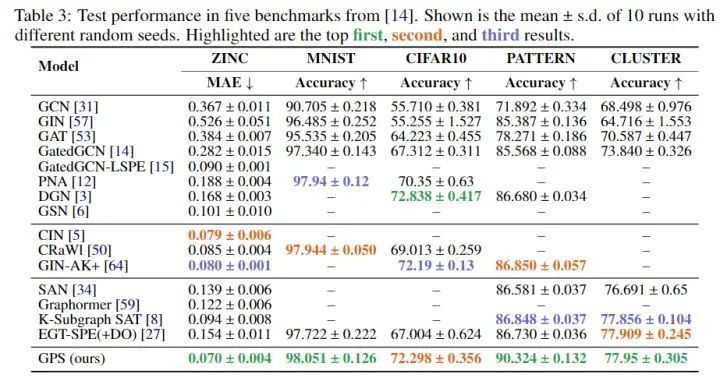
- Benchmarking GNNs
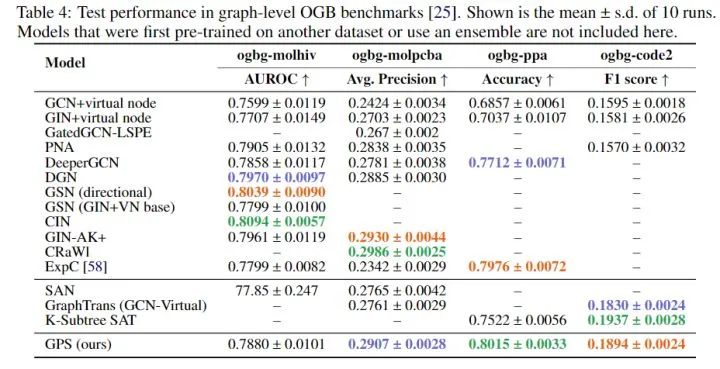
- Open Graph Benchmark
- OGB-LSC PCQM4Mv2
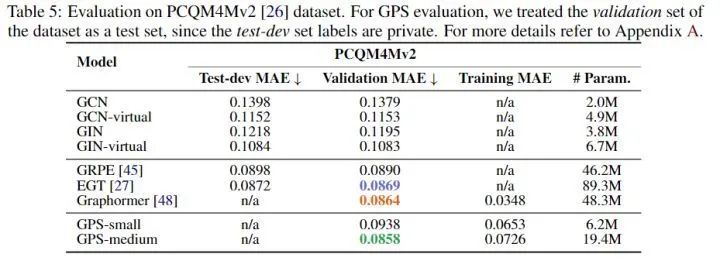
Method Summary
Note: This article primarily summarizes graph transformers on homogeneous graphs; there are also some works on heterogeneous graph transformers, interested readers can check them out.
- The main differences between various transformers on graphs are (1) how to design PE, and (2) how to utilize structural information (combining GNN or using structural information to correct attention scores, etc.).
- Existing methods mainly target small graphs (with at most a few hundred nodes). Although Graph-BERT targets node classification tasks, it first samples subgraphs, which may impair performance (it has more parameters than GAT, but performance is similar); designing a transformer for large graphs remains a challenging issue.
Code References
- GRAPH-BERT: Only Attention is Needed for Learning Graph Representations (https://github.com/jwzhanggy/Graph-Bert)
- (GROVER) Self-Supervised Graph Transformer on Large-Scale Molecular Data (https://github.com/tencent-ailab/grover)
- (GT) A Generalization of Transformer Networks to Graphs (https://github.com/graphdeeplearning/graphtransformer)
- GraphiT: Encoding Graph Structure in Transformers [Code is unavailable]
- (GraphTrans) Representing Long-Range Context for Graph Neural Networks with Global Attention (https://github.com/ucbrise/graphtrans)
- (SAN) Rethinking Graph Transformers with Spectral Attention [Code is unavailable]
- (Graphormer) Do Transformers Really Perform Bad for Graph Representation? (https://github.com/microsoft/Graphormer)
- (SAT) Structure-Aware Transformer for Graph Representation Learning [Code is unavailable]
- (GraphGPS) Recipe for a General, Powerful, Scalable Graph Transformer (https://github.com/rampasek/GraphGPS)
Other Resources
- Graph Transformer Overview (https://arxiv.org/abs/2202.08455); Code (https://github.com/qwerfdsaplking/Graph-Trans)
- Tutorial: A Bird’s-Eye Tutorial of Graph Attention Architectures (https://arxiv.org/pdf/2206.02849.pdf)
- Dataset: Long Range Graph Benchmark (https://arxiv.org/pdf/2206.08164.pdf); Code (https://github.com/vijaydwivedi75/lrgb)
Introduction: GNNs generally can only capture k-hop neighbors and may not be able to capture long-range dependency information. Transformers can solve this problem. This benchmark includes five datasets (PascalVOC-SP, COCO-SP, PCQM-Contact, Peptides-func, and Peptides-struct), requiring models to capture long-range dependencies to achieve better performance. This dataset is mainly used to verify the model’s ability to capture long-range interactions.
There are also some works on homogeneous graphs using Graph Transformers; interested readers can check them out:
- [KDD 2022] Global Self-Attention as a Replacement for Graph Convolution (https://arxiv.org/pdf/2108.03348.pdf)
- [ICOMV 2022] Experimental Analysis of Position Embedding in Graph Transformer Networks (https://www.spiedigitallibrary.org/conference-proceedings-of-spie/12173/121731O/Experimental-analysis-of-position-embedding-in-graph-transformer-networks/10.1117/12.2634427.short)
- [ICLR Workshop MLDD] GRPE: Relative Positional Encoding for Graph Transformer (https://arxiv.org/abs/2201.12787); [Code] (https://github.com/lenscloth/GRPE)
- [Arxiv 2022,05] Your Transformer May Not be as Powerful as You Expect (https://arxiv.org/pdf/2205.13401.pdf); [Code] (https://github.com/lenscloth/GRPE)
- [Arxiv 2022,06] NAGphormer: Neighborhood Aggregation Graph Transformer for Node Classification in Large Graphs (https://arxiv.org/abs/2206.04910)
 We recommend following an AI public account, where we update the latest dynamics in the AI industry daily, share machine learning insights, original deep learning blogs, practical deep learning projects, and translations of the latest papers, bringing you fresh news from the AI industry. We hope you like it. Click the card below to follow us~ ✄———————————————–
We recommend following an AI public account, where we update the latest dynamics in the AI industry daily, share machine learning insights, original deep learning blogs, practical deep learning projects, and translations of the latest papers, bringing you fresh news from the AI industry. We hope you like it. Click the card below to follow us~ ✄———————————————–
Seeing this, it shows you like this article, please click “View” or easily “Share” “Like“.
Feel free to search WeChat for “panchuangxx” and add the editor Pan Xiaoxiao WeChat, where we update a high-quality post daily (no ads), providing you with more exciting content.
▼ ▼ Scan the QR code to add the editor ▼ ▼
